
สรุปจากคลิป ดูคลิปต้นฉบับ
Self Driving Products เมื่อ AI เปลี่ยนสัญญาณปัญหาเป็น PR

ทุกธุรกิจมีข้อมูลปัญหาไหลเข้ามาตลอดเวลา ทั้ง error ที่พุ่งตอนดึก ข้อความจากลูกค้าใน Slack หรือ session replay ที่บอกว่าคนใช้งานติดตรงไหน แต่ในความจริง ข้อมูลเหล่านี้มักไปจบที่ dashboard แล้วรอให้ทีมค่อยมาเปิดดู ค่อยวิเคราะห์ ค่อยตั้ง issue และค่อยแก้ทีหลัง ซึ่งช้าเกินไปสำหรับโลกที่ปัญหาเกิดขึ้นทุกนาที
คลิปจากช่อง AI Engineer ที่พูดถึงงานของ Joshua Snyder จาก PostHog เสนอภาพที่น่าสนใจมาก คือแทนที่เราจะมีระบบไว้ “ดูปัญหา” อย่างเดียว เราอาจมีระบบที่ “ลงมือแก้ปัญหา” ให้เลย ตั้งแต่รับ signal จัดกลุ่ม ค้นคว้าหาสาเหตุ ไปจนเปิด Pull Request อัตโนมัติ แนวคิดนี้ไม่ใช่แค่เรื่องของทีม developer แต่เป็นเรื่องของเจ้าของธุรกิจด้วย เพราะมันแตะคำถามสำคัญว่า เราจะทำให้ product ปรับปรุงตัวเองได้แค่ไหน
บทความนี้สรุปและวิเคราะห์แนวคิด Self Driving Products ว่ามันทำงานอย่างไร มีข้อจำกัดอะไร และถ้าเอามาปรับใช้กับธุรกิจไทย เราควรเริ่มจากตรงไหนก่อนเพื่อให้ AI ช่วยงานจริง ไม่ใช่แค่เพิ่มของเล่นใหม่เข้าองค์กร
สารบัญ
- Step 1: มองปัญหาใหม่ว่า dashboard ไม่ใช่ปลายทาง
- Step 2: รวบรวม signal จากหลายแหล่งให้เป็นภาษาเดียวกัน
- Step 3: จัดกลุ่มปัญหาแบบข้ามประเภท ไม่ใช่ข้ามแค่ข้อความ
- Step 4: ให้ research agent หาหลักฐานก่อนตัดสินใจแก้
- Step 5: ตัดสินใจว่าอะไรทำต่อได้ทันที และอะไรต้องให้คนช่วย
- Step 6: ให้ execution agent สร้าง PR และวนแก้จนพร้อมใช้
- Step 7: เรียนรู้จากบทเรียน 4 ข้อที่ช่วยให้เอา AI ไปใช้จริงได้
- Step 8: คิดต่อว่า Self Driving Products ใช้กับธุรกิจไทยได้แค่ไหน
- Actionable Insights
- Troubleshooting
- การต่อยอด
- สรุป Checklist ทั้งหมด
Step 1: มองปัญหาใหม่ว่า dashboard ไม่ใช่ปลายทาง
แกนกลางของแนวคิดนี้คือ การตั้งคำถามกับวิธีทำงานแบบเดิมของ observability tools
ปกติแล้ว flow จะประมาณนี้ มีบางอย่างผิดปกติเกิดขึ้นใน product แล้ว metric บน dashboard เปลี่ยน จากนั้นทีมค่อยเข้ามาดู ค่อยสืบหาสาเหตุ ค่อยสร้าง ticket แล้วสุดท้ายค่อยเขียนโค้ดแก้ ปัญหาคือกระบวนการนี้ใช้เวลาตั้งแต่หลักชั่วโมงไปถึงหลายวัน และหลายครั้งงานส่วนใหญ่ก็เป็นงานจุกจิกที่ไม่ได้สร้างความต่างทางธุรกิจมากนัก
สิ่งที่ PostHog พยายามทำคือย้ายจุดสนใจจาก dashboard ไปสู่ GitHub PR แทน กล่าวคือ เมื่อมีสัญญาณบางอย่างเกิดขึ้น ระบบไม่ควรหยุดแค่บอกว่ามีปัญหา แต่ควรเริ่มวิเคราะห์และเสนอวิธีแก้ทันที จนได้ PR ที่พร้อม review หรือพร้อม deploy หลัง feature flag
ถ้ามองในมุมธุรกิจไทย นี่คือการลดเวลาจาก “เจอปัญหา” ไปสู่ “เริ่มแก้ปัญหา” ซึ่งมีผลโดยตรงกับรายได้ เช่น ถ้าหน้า checkout พัง 4 ชั่วโมง ความเสียหายไม่ใช่แค่เรื่องเทคนิค แต่คือยอดขายที่หายไปแบบจับต้องได้
Step 2: รวบรวม signal จากหลายแหล่งให้เป็นภาษาเดียวกัน
ปัญหาใหญ่ของระบบลักษณะนี้ไม่ใช่การเขียนโค้ดแก้ แต่คือการเข้าใจข้อมูลที่กระจัดกระจายก่อน
PostHog มีข้อมูลจากหลายแหล่งมาก เช่น product analytics, session replay, web analytics, error tracking และ experiment results แต่ละแหล่งมีหน้าตาต่างกันหมด error มี stack trace, log เป็น JSON, replay เป็นพฤติกรรมของผู้ใช้, ข้อความจากลูกค้าเป็นภาษาคน ถ้าปล่อยให้ข้อมูลอยู่ในรูปดั้งเดิม AI จะทำงานต่อยากมาก
วิธีคิดที่สำคัญจึงเป็นการ normalize signal ให้เหลือโครงสร้างกลางชุดเดียว เช่น
- แหล่งที่มา
- ประเภทของ signal
- เนื้อหาหลัก
- น้ำหนักความสำคัญ
- embedding สำหรับค้นหาความเกี่ยวข้อง
ก่อนถึงจุดนั้นยังต้องมี safety layer ด้วย เพราะบางแหล่งเป็นข้อมูลสาธารณะ หากระบบรับทุกอย่างเข้ามาโดยไม่กรอง ก็เสี่ยงโดน prompt injection หรือข้อมูลหลอกให้ agent ไปทำสิ่งอันตรายได้ PostHog จึงใช้ LLM classifier เป็นด่านแรกเพื่อตัด signal ที่ดูไม่ปลอดภัยออกก่อน
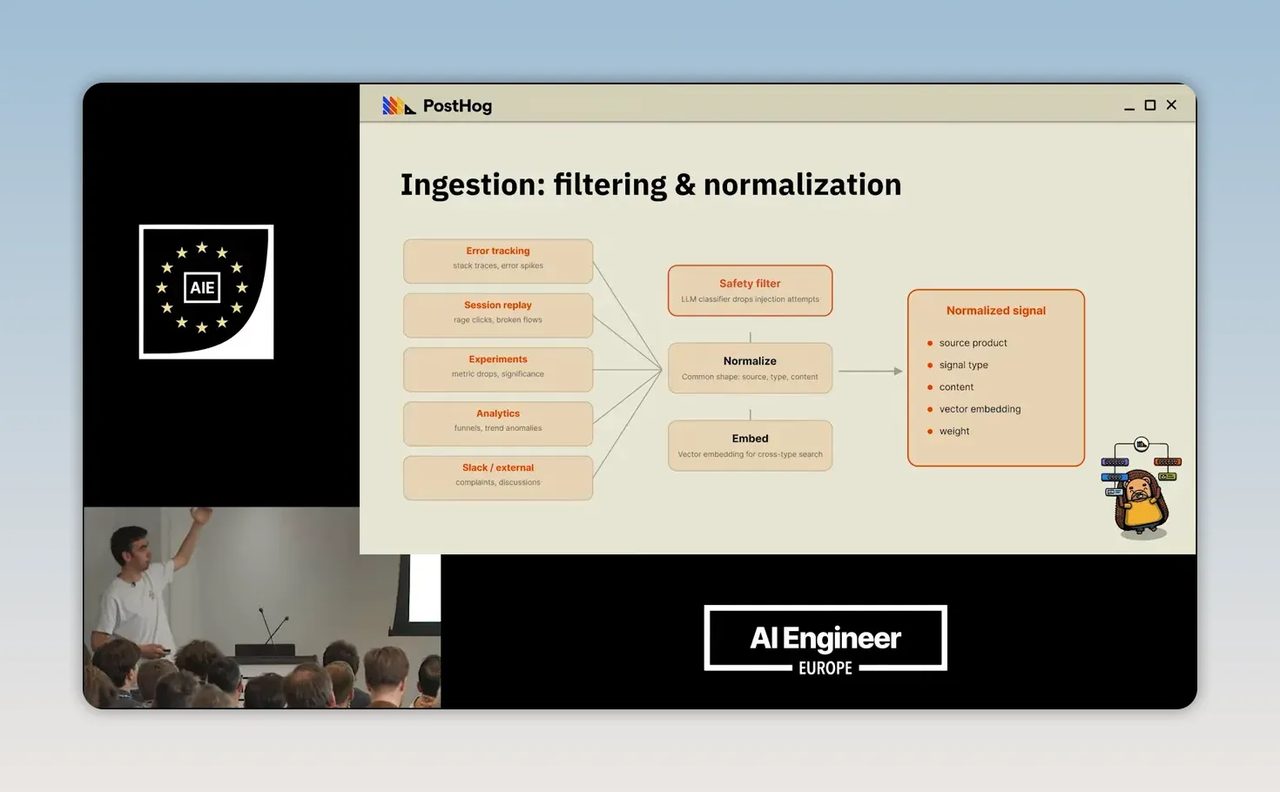
นี่เป็นบทเรียนที่หลายองค์กรพลาดเวลาเริ่มใช้ AI กับข้อมูลภายใน เรามักรีบโยนทุกอย่างเข้า model แล้วหวังผล แต่ถ้า input ยังเละ output ก็แทบไม่มีทางดีขึ้น ธุรกิจที่อยากเริ่มไม่จำเป็นต้องมีข้อมูลระดับหลายล้าน event ต่อวัน แค่เริ่มจาก 3 แหล่งหลัก เช่น support ticket, error log และ analytics events แล้วนิยาม schema กลางให้ชัด ก็เดินต่อได้แล้ว
Step 3: จัดกลุ่มปัญหาแบบข้ามประเภท ไม่ใช่ข้ามแค่ข้อความ
หนึ่งในจุดที่น่าสนใจที่สุดของคลิปนี้คือเรื่องการจัดกลุ่มปัญหา หรือ cross type clustering
ในโลกจริง ปัญหาเดียวกันอาจโผล่มาหลายรูปแบบ เช่น ลูกค้าบอกใน Slack ว่าจ่ายเงินไม่ได้ ขณะเดียวกันระบบมี error ที่ checkout และ session replay ก็โชว์ว่าคนใช้งานกดปุ่มเดิมซ้ำหลายครั้ง ทั้งหมดนี้คือเรื่องเดียวกัน แต่ถ้าใช้ embedding model แบบสำเร็จรูปกับข้อมูลดิบตรงๆ model มักจัดกลุ่มตาม “รูปแบบข้อมูล” มากกว่า “ความหมาย”
ผลคือ error จะไปอยู่กับ error, ข้อความแชตจะไปอยู่กับข้อความแชต, replay ก็แยกเป็นอีกกองหนึ่ง ทั้งที่ความจริงทั้งหมดอาจชี้ไปที่ checkout พังเหมือนกัน
ทางแก้ที่ PostHog ใช้คือไม่ค้นหาจาก raw signal โดยตรง แต่ให้ LLM ช่วยสร้าง query ที่อธิบายว่า signal นี้เกี่ยวกับอะไร แล้วค่อยเอา query นั้นไป embed และจับกลุ่มแทน วิธีนี้ทำให้ระบบมองทะลุรูปแบบภายนอกและจับที่ความหมายจริง
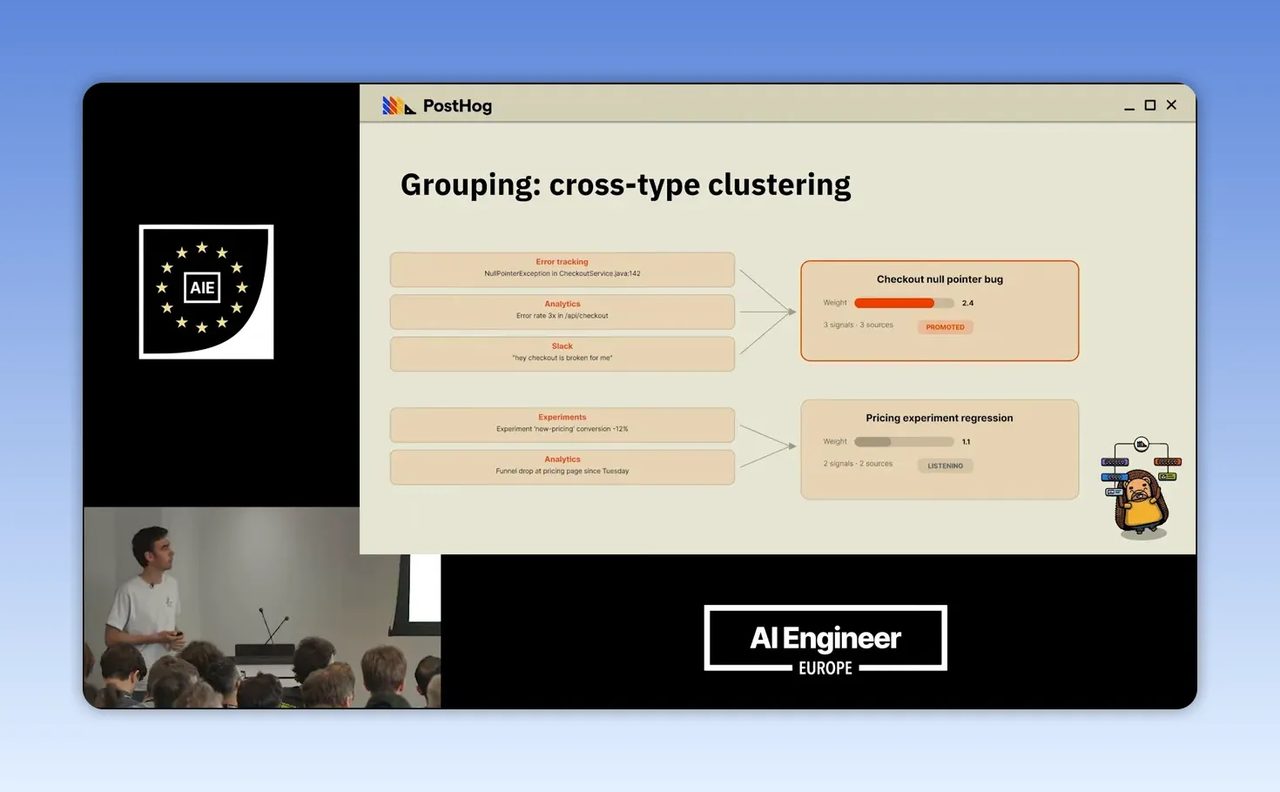
มุมนี้สำคัญมากสำหรับธุรกิจที่มีข้อมูลหลายช่องทาง เช่น ร้านค้าออนไลน์ไทยที่มีทั้งแชตจาก LINE OA, คำร้องจากคอลเซ็นเตอร์ และข้อมูลจากหน้าเว็บ ถ้าเราอยากใช้ AI เพื่อหา pain point จริง เราไม่ควรถามว่า “ข้อความนี้คล้ายข้อความไหน” แต่ควรถามว่า “ข้อมูลนี้กำลังพูดถึงปัญหาอะไร”
นี่คือความต่างระหว่างระบบที่ฉลาดแบบใช้งานได้ กับระบบที่ดูเหมือนฉลาดแต่สร้าง noise เพิ่ม
Step 4: ให้ research agent หาหลักฐานก่อนตัดสินใจแก้
เมื่อระบบรวมหลาย signal เป็นรายงานปัญหาเดียวได้แล้ว ขั้นต่อไปคือส่งต่อให้ research agent
agent นี้ไม่ได้ทำหน้าที่แค่สรุปปัญหาแบบผิวเผิน แต่มันถูกออกแบบให้ดึงข้อมูลเพิ่มจากหลายแหล่งเพื่อหาหลักฐานประกอบ เช่น log เพิ่มเติม, codebase context และข้อมูลจากเครื่องมือภายในอย่าง Linear หรือ Notion เพื่อทำความเข้าใจว่าปัญหานี้เคยเกิดไหม เกี่ยวข้องกับฟีเจอร์อะไร หรือทีมไหนควรเป็นคนตรวจ
ผลลัพธ์ของขั้นนี้มี 3 อย่างหลัก
- สรุปว่าปัญหาคืออะไร
- ประเมินความสำคัญ
- ระบุคนหรือทีมที่ควร review PR หากมีการสร้างขึ้นมา
ความเห็นที่น่าสนใจคือ agent จะทำงานได้ดีขึ้นมากเมื่อถูกเชื่อมกับระบบความรู้ขององค์กร ไม่ใช่มีแค่โค้ดกับ error อย่างเดียว เพราะในชีวิตจริง การแก้ปัญหาไม่ได้อิงเทคนิคอย่างเดียว แต่พึ่งความรู้สะสม เช่น “ทีมเคยตั้งใจให้ flow นี้เป็นแบบนี้” หรือ “ฟีเจอร์นี้กำลัง redesign อยู่”
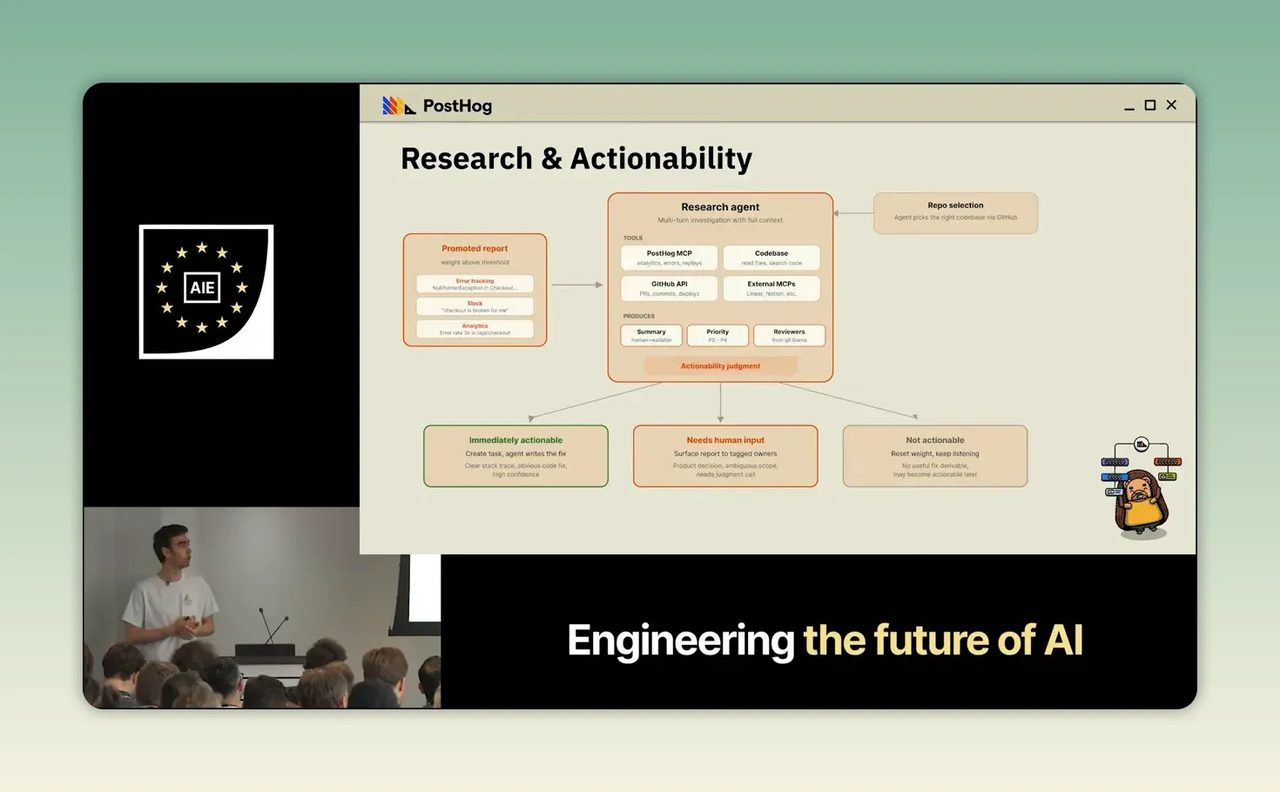
สำหรับธุรกิจไทย นี่แปลว่า ถ้าเราอยากให้ AI ช่วยงานจริง เราต้องจัดระเบียบ knowledge base ให้ดีขึ้นก่อนด้วย ไม่ว่าจะเป็น SOP, FAQ ภายใน, product decision log หรือ ticket เก่าๆ เพราะ AI ที่ไม่มีความรู้ขององค์กร มักตอบได้แค่ระดับทั่วไป และระดับทั่วไปแก้ปัญหาธุรกิจจริงไม่ได้
Step 5: ตัดสินใจว่าอะไรทำต่อได้ทันที และอะไรต้องให้คนช่วย
หลังจาก research แล้ว ระบบยังไม่ควรรีบเขียนโค้ดทุกครั้ง ต้องมีด่านสำคัญคือ actionability
PostHog แบ่งปัญหาออกเป็น 3 แบบ
- ยังไม่ actionable คือข้อมูลยังไม่พอ ต้องรอหลักฐานเพิ่ม
- ต้องการคนตัดสินใจ มักเป็นเรื่อง product decision ที่ไม่มีคำตอบเดียว
- actionable ทันที คือชัดพอให้ agent เขียน fix ได้เลย
จุดนี้สำคัญมาก เพราะถ้าเราโยนโจทย์กว้างๆ ให้ agent มันก็มักจะพยายามแก้บางอย่างให้เสมอ แม้โจทย์จะยังคลุมเครืออยู่ก็ตาม ผลลัพธ์คือได้ PR ที่ดูเหมือนมีงานทำ แต่ไม่ได้แก้ต้นเหตุจริง
ตัวอย่างที่คลิปชี้ไว้ชัดคือ error tracking มัก actionable กว่า เพราะข้อมูลเฉพาะเจาะจง เช่น stack trace หรือ failing condition ตรงไปตรงมา แต่ข้อความใน Slack หรือ session replay มักเปิดกว้าง มีหลายความเป็นไปได้ และมักต้องการ judgement จากคนมากกว่า
มุมนี้เอามาใช้กับองค์กรได้เลย หากเรากำลังเอา AI ไปใช้ในงาน support, marketing หรือ operations เราไม่ควรหวังให้ AI ปิดงานทุกเคส แต่ควรออกแบบ triage ก่อนว่าเคสไหน auto ได้ เคสไหนเสนอ draft ให้คนแก้ต่อ และเคสไหนต้องส่งต่อให้ทีมตัดสินใจ
Step 6: ให้ execution agent สร้าง PR และวนแก้จนพร้อมใช้
เมื่อปัญหาผ่านเกณฑ์ว่า actionable แล้ว ขั้นต่อไปคือ execution
ระบบจะ clone repository เข้า sandbox จากนั้นใช้ agent เขียนโค้ดแก้ สร้าง PR และตรวจผลกับ CI หาก CI ไม่ผ่าน หรือมี comment บน PR ระบบจะ rerun ต่อจาก snapshot เดิมแทนที่จะเริ่มใหม่ทั้งหมด ทำให้ agent แก้งานต่อเนื่องได้จน PR อยู่ในสถานะพร้อม merge
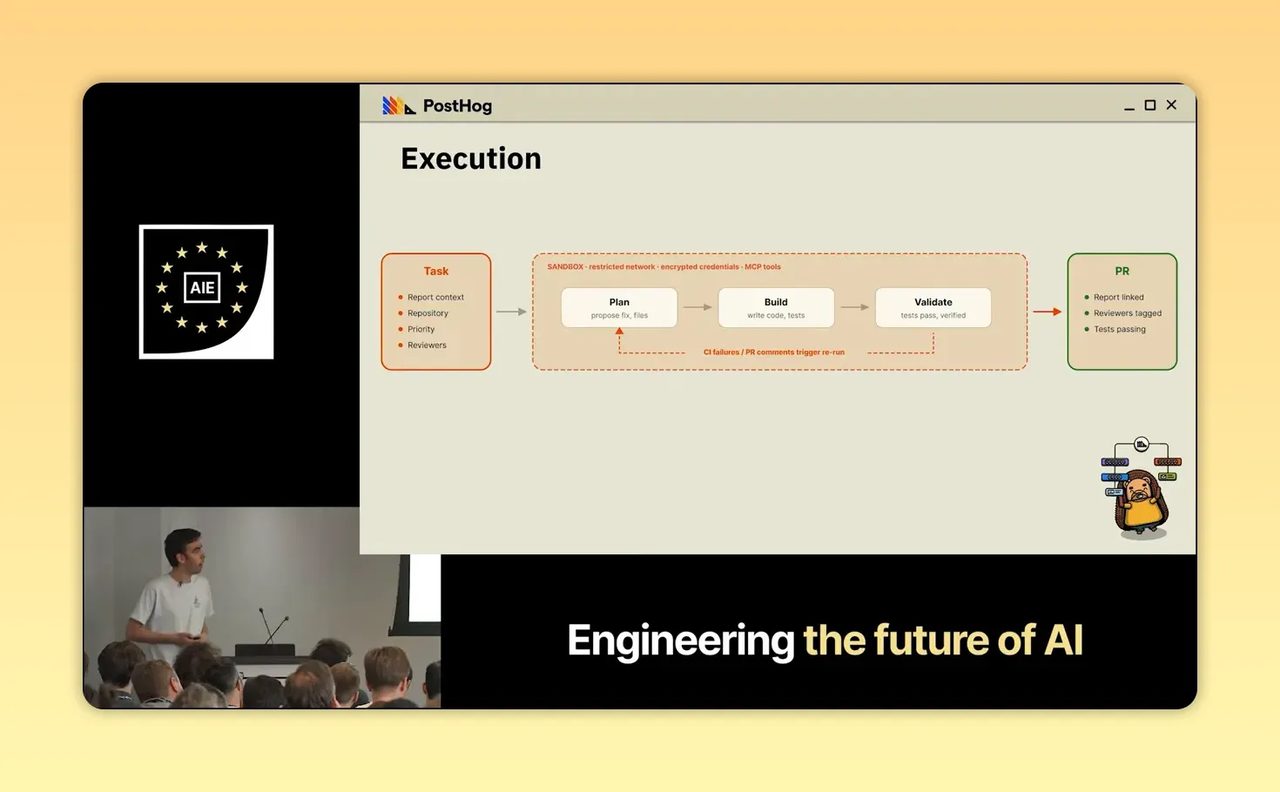
ภาพที่ PostHog วางไว้คือ ตอนเช้ามาเปิด GitHub แล้วเจอ PR สีเขียวที่พร้อม review แทนการเจอ dashboard เต็มไปด้วย alert หรือ CI ที่แดงค้างอยู่
แนวคิดนี้น่าสนใจสำหรับธุรกิจที่มีทีมเทคนิคไม่ใหญ่ โดยเฉพาะ startup หรือทีม product ที่โดน bug จุกจิกกินเวลาเยอะ ถ้า AI ช่วยปิดงานซ้ำๆ ได้ ทีมก็เอาเวลาไปทำฟีเจอร์ใหม่หรือทดลองเรื่องที่กระทบรายได้มากกว่า
แต่ต้องพูดตรงๆ ว่าโมเดลนี้ยังเหมาะกับงานที่มีขอบเขตชัด เช่น bug fix, regression หรือการแก้ logic ที่เจาะจงมากกว่างานออกแบบระบบใหม่ งานที่มีผลข้างเคียงเยอะยังต้องระวังและควรถูกคุมด้วย feature flag หรือ human review เสมอ
Step 7: เรียนรู้จากบทเรียน 4 ข้อที่ช่วยให้เอา AI ไปใช้จริงได้
ช่วงท้ายของคลิปมี 4 บทเรียนที่ใช้ได้ไกลกว่ากรณีของ PostHog มาก และน่าจะเป็นส่วนที่เจ้าของธุรกิจเอาไปคิดต่อได้เยอะที่สุด
1) Evals สำคัญมาก
การลองระบบกับข้อมูลของตัวเองไม่กี่ชุดแล้วรู้สึกว่า “น่าจะโอเค” ไม่พอ ถ้าจะใช้กับงานจริงต้องทดสอบกับข้อมูลที่ใกล้เคสจริงที่สุด ไม่อย่างนั้นเราจะปรับระบบแบบเดาสุ่ม
ในมุมธุรกิจ นี่หมายถึงต้องมีตัวชี้วัดชัด เช่น AI จัดหมวดปัญหาแม่นแค่ไหน ลดเวลา triage ได้กี่เปอร์เซ็นต์ หรือ PR ที่สร้างมาถูก merge จริงกี่ส่วน
2) ต้อง embed สิ่งที่ถูก
ถ้า data คนละ format กัน อย่าหวังว่า embedding แบบเดียวจะเข้าใจได้หมด ต้องออกแบบ representation ให้เหมาะก่อน บางครั้ง query ที่ AI ช่วย rewrite อาจมีค่ามากกว่าข้อมูลดิบเอง
3) agent จะพยายามแก้เสมอ แม้โจทย์ยังไม่ชัด
นี่เป็นข้อเตือนใจที่ดีมาก AI ไม่ค่อยบอกว่า “ข้อมูลไม่พอ” ถ้าเราไม่สร้างเงื่อนไขบังคับไว้ มันจึงชอบลงมือทำอะไรบางอย่าง และนั่นอาจเป็นงานผิดทิศทาง
4) ตอนทดลอง อย่ากลัว token cost มากเกินไป
ประโยคที่น่าจำคือ token ไม่ได้ฟรี แต่ในช่วงทดลอง การกังวลเรื่องต้นทุนเร็วเกินไปอาจทำให้เราไม่เห็นวิธีที่ดีที่สุดก่อน PostHog พบว่าเมื่อรัน agent กับปัญหาซ้ำๆ มากพอ จะเริ่มเห็น pattern และสามารถยุบขั้นตอนแพงๆ ให้กลายเป็น one shot call หรือระบบเฉพาะทางที่ถูกลงภายหลัง
อันนี้เราค่อนข้างเห็นด้วย โดยเฉพาะสำหรับองค์กรที่ยังไม่รู้เลยว่า AI จะช่วยตรงไหน ถ้าประหยัดเร็วเกินไป เราอาจได้แค่ระบบกั๊กๆ ที่ไม่เคยพิสูจน์คุณค่าแท้จริง
Step 8: คิดต่อว่า Self Driving Products ใช้กับธุรกิจไทยได้แค่ไหน
แม้แนวคิดนี้เกิดจากงาน product engineering แต่หลักการเอาไปประยุกต์กับธุรกิจไทยได้กว้างกว่าที่คิด
ตัวอย่างเช่น
- ธุรกิจ e-commerce ใช้ AI รวมสัญญาณจากแชตลูกค้า, error หน้า checkout และ funnel drop เพื่อเปิด ticket หรือ draft วิธีแก้ให้ทีม
- SaaS B2B ใช้ AI รวม support issue, usage drop และ log anomalies เพื่อบอกว่าลูกค้ากลุ่มไหนเสี่ยง churn
- ธุรกิจบริการใช้ AI รวม complaint, call summary และ operation logs เพื่อหา root cause ของปัญหาซ้ำๆ
อย่างไรก็ตาม จุดที่ควรเห็นต่างจากความตื่นเต้นในคลิปคือ คำว่า “product สร้างตัวเอง” ยังเป็นวิสัยทัศน์มากกว่าสภาพจริง ระบบลักษณะนี้จะเก่งมากกับงานที่เป็น pattern ชัด ซ้ำ และวัดผลได้ แต่จะเริ่มยากเมื่อปัญหาเกี่ยวกับกลยุทธ์ ประสบการณ์ลูกค้า หรือ trade off ทางธุรกิจที่ไม่มีคำตอบเดียว
ดังนั้นคำถามที่ดีกว่าไม่ใช่ “AI จะมาแทนทีมได้ไหม” แต่คือ “เราจะให้ AI รับผิดชอบงานประเภทไหนก่อน เพื่อคืนเวลาของทีมให้ไปทำงานที่สำคัญกว่า”
สำหรับคนที่อยากต่อยอดความเข้าใจเรื่อง observability และ workflow automation สามารถอ่านเพิ่มได้ที่ PostHog Blog, แนวคิดเรื่อง observability จาก Martin Fowler และเรื่อง Pull Requests บน GitHub
Actionable Insights
- เริ่มจากปัญหาที่ซ้ำและวัดผลได้ เช่น error ที่เกิดบ่อย หรือ ticket support หมวดเดิม
- รวมข้อมูล 2 ถึง 3 แหล่งให้เป็น schema เดียวก่อน อย่าเพิ่งต่อทุกระบบพร้อมกัน
- ออกแบบเกณฑ์ actionability ชัดว่าเคสไหน AI ทำเอง เคสไหนต้องมีคนอนุมัติ
- เก็บ evals ตั้งแต่วันแรก เช่น ความแม่นในการจัดกลุ่มและเวลาที่ลดลงจริง
- ใช้ feature flag หรือ sandbox ทุกครั้งก่อนปล่อย AI ไปแตะระบบจริง
Troubleshooting
- ปัญหา: AI จัดกลุ่มปัญหาผิด เอาเรื่องคนละอย่างมารวมกัน
สาเหตุ: ใช้ embedding กับข้อมูลดิบที่มีโครงสร้างต่างกันมาก
วิธีแก้: สร้าง query กลางจากแต่ละ signal ก่อน แล้วค่อย embed เพื่อจับความหมายแทนรูปแบบ - ปัญหา: ได้ PR ที่ดูขยัน แต่ไม่แก้ปัญหาจริง
สาเหตุ: โจทย์กว้างเกินไป หรือ signal ยังไม่ specific พอ
วิธีแก้: เพิ่มด่าน actionability ถ้าปัญหายังคลุมเครือให้ส่งเข้า inbox เพื่อให้คนช่วยตัดสินใจก่อน - ปัญหา: ค่าใช้จ่าย model สูงเกินคาดตอนเริ่มระบบ
สาเหตุ: ใช้ agent หลายขั้นกับทุกเคสตั้งแต่ต้น
วิธีแก้: ยอมให้ช่วงทดลองมีต้นทุนเพื่อหา pattern ก่อน จากนั้นค่อยยุบขั้นตอนที่ซ้ำให้เป็น one shot workflow - ปัญหา: AI สรุปปัญหาได้ แต่ตัดสินใจอะไรไม่ค่อยได้
สาเหตุ: ขาด knowledge base ภายใน เช่น ticket เก่าหรือเอกสาร product decision
วิธีแก้: เชื่อมระบบกับแหล่งความรู้ที่ทีมใช้อยู่จริง เช่น Notion, issue tracker หรือคู่มือภายใน - ปัญหา: ทีมไม่ไว้ใจสิ่งที่ AI สร้างมา
สาเหตุ: ไม่มีหลักฐานรองรับหรือวัดผลย้อนหลัง
วิธีแก้: ให้ทุก output ของ AI แนบเหตุผล, หลักฐานที่ใช้ และผลลัพธ์หลัง deploy เพื่อสร้าง feedback loop
การต่อยอด
- ขยับจาก bug fix ไปสู่การรัน experiment อัตโนมัติ เช่น ปรับ onboarding หรือ pricing copy แล้ววัดผลเอง
- สร้าง executive inbox ที่ไม่ใช่ dashboard ดิบ แต่เป็นรายการปัญหาที่ AI สรุปพร้อมข้อเสนอการแก้
- ใช้ feedback หลัง deploy มาปรับน้ำหนักการตัดสินใจของ agent เพื่อให้ PR รุ่นต่อไปแม่นขึ้น
สรุป Checklist ทั้งหมด
- เปลี่ยนมุมมองจาก dashboard เป็นระบบที่ลงมือทำต่อได้
- รวม signal จากหลายแหล่งให้อยู่ในโครงสร้างกลางเดียวกัน
- ใส่ safety filter ก่อนให้ AI แตะข้อมูลสาธารณะหรือ input ภายนอก
- ใช้การจัดกลุ่มแบบอิงความหมาย ไม่ใช่อิงรูปแบบข้อมูล
- ให้ research agent ดึงข้อมูลเพิ่มจาก codebase และ knowledge tools
- แยกปัญหาเป็นยังไม่พร้อม, ต้องให้คนช่วย, และทำต่อได้ทันที
- ให้ execution agent สร้าง PR ใน sandbox และวนแก้ตามผล CI
- วัดผลด้วย evals บนข้อมูลจริง ไม่ใช่แค่ลองกับเคสสวยๆ
- อย่าประหยัด token เร็วเกินไปในช่วงค้นหา workflow ที่ใช่
- ปิด loop ด้วยการเรียนรู้จากผลลัพธ์หลัง deploy และการ reject PR
สรุปสั้นที่สุด แนวคิด Self Driving Products ไม่ได้บอกว่า AI จะทำ product แทนเราได้หมด แต่กำลังบอกว่า งานส่วนหนึ่งที่วันนี้เสียเวลาไปกับการตามปัญหา จัดลำดับ และเขียนงานแก้ซ้ำๆ สามารถถูกย้ายให้ AI รับไปก่อน ถ้าเราออกแบบ signal, workflow และเกณฑ์ตัดสินใจให้ดีพอ สำหรับเจ้าของธุรกิจและคนทำงานที่อยากเอา AI ไปใช้จริง นี่คือโจทย์ที่น่าลองมากกว่าแค่ถามว่า model ไหนเก่งที่สุด เพราะคำตอบที่คุ้มจริงมักอยู่ที่ระบบรอบ model ไม่ใช่ model เพียงตัวเดียว