
สรุปจากคลิป ดูคลิปต้นฉบับ
RAG ยังไม่ตาย แต่กำลังโตเป็น Agentic Retrieval ที่ใช้ได้จริง

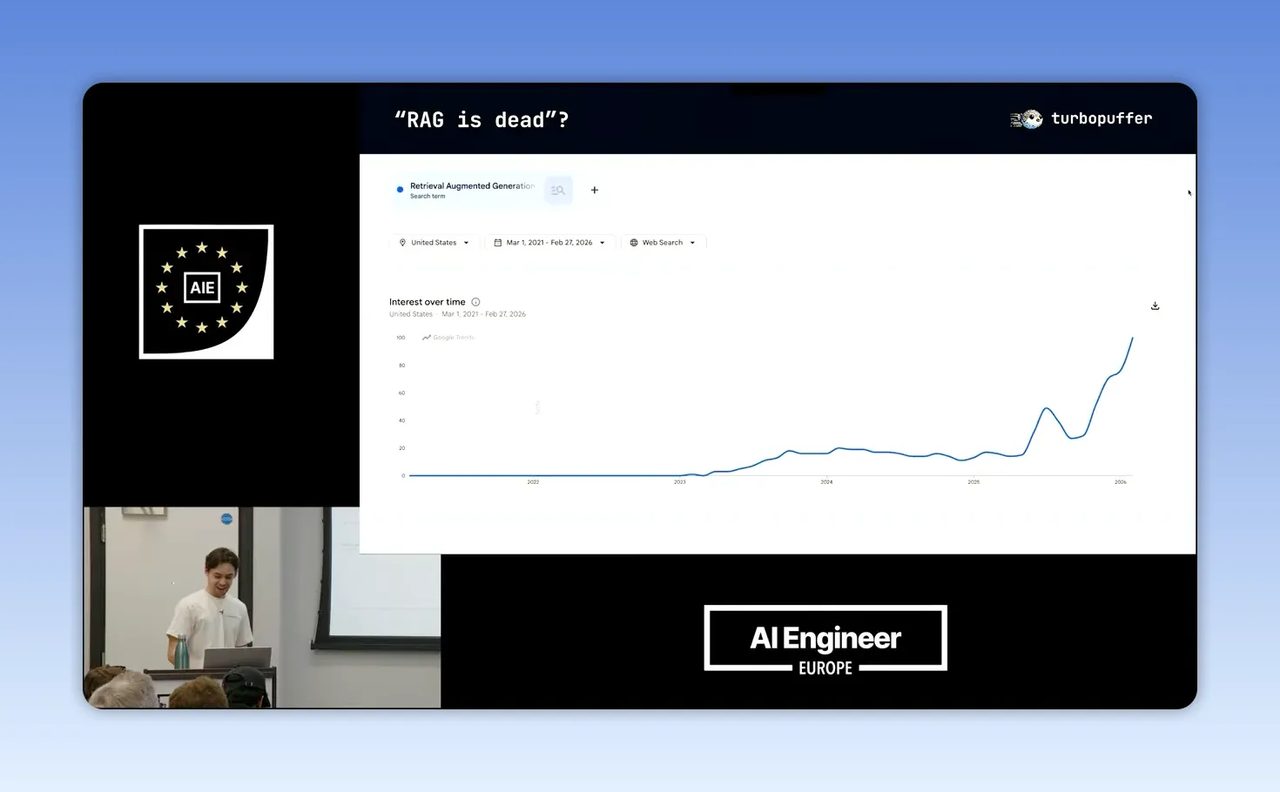
ประโยคว่า “RAG is dead” ฟังแล้วคม ชวนแชร์ และทำให้หลายทีมเริ่มสงสัยว่าของที่เคยลงทุนทำไว้กำลังล้าสมัยหรือเปล่า แต่คลิปจากช่อง AI Engineer ที่ชวน Kuba Rogut จาก Turbopuffer มาพูด กลับเสนอภาพที่น่าสนใจกว่านั้นมาก คือสิ่งที่กำลังตายอาจไม่ใช่ RAG แต่เป็นนิยามแบบแคบของ RAG ต่างหาก
ประเด็นนี้สำคัญกับเจ้าของธุรกิจและคนทำงานไทยมาก เพราะเวลาคุยเรื่อง AI search, knowledge base หรือ AI agent เรามักโดดไปที่คำถามว่า “ใช้ vector search ไหม” ทั้งที่คำถามที่ควรถามจริงๆ คือ “ระบบค้นหาข้อมูลให้ AI ทำงานได้ดีพอหรือยัง” ถ้ามองแบบนี้ เราจะเห็นว่า retrieval ไม่ได้มีแค่ embedding แต่เป็นชุดเครื่องมือค้นหาหลายแบบที่ทำงานร่วมกัน
คลิปนี้ไม่ได้แค่สรุปเทรนด์ แต่มีมุมคิดที่เอาไปใช้วางระบบ AI ในองค์กรได้เลย โดยเฉพาะถ้าเรากำลังทำ chatbot ภายในบริษัท, ระบบตอบคำถามจากเอกสาร, AI assistant สำหรับทีมขาย หรือ agent ที่ต้องอ่านข้อมูลจำนวนมากก่อนตัดสินใจ
สารบัญ
- Step 1: เลิกถามว่า RAG ตายหรือยัง แล้วถามใหม่ว่า retrieval ของเราดีพอหรือยัง
- Step 2: เข้าใจความต่างระหว่าง RAG แบบพื้นฐาน กับ agentic search แบบใช้งานจริง
- Step 3: ดูเคส Cursor แล้วจะเห็นว่าการทำ index ล่วงหน้าให้ผลทางธุรกิจจริง
- Step 4: เข้าใจ trade-off ของ Claude Code กับ Cursor แล้วจะออกแบบระบบได้ฉลาดขึ้น
- Step 5: ใช้มุมคิด “embeddings are cached compute” เพื่อคุมต้นทุน AI
- Step 6: อย่าหลงกับ context window ใหญ่ จงหาข้อมูลที่ใช่ให้เจอ
- Step 7: เปลี่ยนบทเรียนจากคลิปให้เป็นระบบ AI ที่ใช้จริงในธุรกิจไทย
- Actionable Insights
- Troubleshooting
- การต่อยอด
- Step 8: สรุป Checklist ทั้งหมด
Step 1: เลิกถามว่า RAG ตายหรือยัง แล้วถามใหม่ว่า retrieval ของเราดีพอหรือยัง
แก่นหลักของคลิปคือการโต้กลับกระแสที่บอกว่า RAG หมดความจำเป็นแล้ว เพราะตอนนี้มี agentic search หรือ file search มาแทนที่ แต่ถ้าแยกคำว่า RAG ออกจริงๆ จะเห็นว่า retrieval-augmented generation มีสองส่วน คือการดึงข้อมูล และการส่งข้อมูลที่เกี่ยวข้องเข้าไปให้ model ใช้ตอบ
ปัญหาคือหลายทีมตีความ retrieval แค่ว่า “ยิง vector search หนึ่งครั้ง แล้วส่งผลลัพธ์เข้า LLM” พอนิยามแคบแบบนี้ ระบบก็จะตันเร็วมาก โดยเฉพาะในงานจริงที่ข้อมูลกระจัดกระจาย มีทั้งไฟล์ PDF, policy, FAQ, ตาราง, อีเมล, ticket support และโน้ตภายใน
มุมที่น่าสนใจคือ Kuba พยายามขยายความว่า retrieval ที่ดี ไม่ได้มีแค่ semantic search แต่รวมถึง:
- full-text search
- การค้นด้วย keyword แบบ BM25
- grep หรือการไล่หาข้อความตรงตัว
- glob หรือการหาตาม pattern ของไฟล์
- regex
- filter ตาม metadata
ถ้าแปลเป็นภาษาธุรกิจง่ายๆ คือ AI ไม่ควรมีแค่ “ความเข้าใจคล้ายความหมาย” แต่ต้องมี “เครื่องมือหาข้อมูลตรงจุด” ด้วย
สำหรับธุรกิจไทย นี่คือจุดที่หลายองค์กรพลาด เช่น ทำระบบตอบคำถามจากเอกสาร HR แต่ใช้ embedding อย่างเดียว พอถามรหัสฟอร์ม, ชื่อโปรโมชัน, เลขรุ่นสินค้า, SKU หรือคำเฉพาะในองค์กร ระบบกลับหาไม่เจอ ทั้งที่ full-text search น่าจะตอบโจทย์กว่า
Step 2: เข้าใจความต่างระหว่าง RAG แบบพื้นฐาน กับ agentic search แบบใช้งานจริง
คำว่า agentic search ในคลิปไม่ได้หมายถึงระบบที่ฉลาดลึกลับอะไรนัก แต่มันคือการให้ agent มีชุดเครื่องมือไว้ค้นข้อมูลแบบค่อยๆ หา ค่อยๆ อ่าน และค่อยๆตัดสินใจว่าจะค้นต่อหรือพอแล้ว
ต่างจาก RAG แบบพื้นฐานที่มักทำงานเป็นเส้นตรง:
- รับคำถาม
- ค้น vector database หนึ่งครั้ง
- ส่งผลลัพธ์เข้า model
- ตอบกลับ
agentic retrieval จะทำงานเป็นวงรอบมากกว่า:
- เริ่มจากคำถาม
- ค้นหาชุดแรก
- อ่านข้อความที่ได้
- ประเมินว่าข้อมูลยังไม่พอหรือไม่
- ค้นเพิ่มด้วยเครื่องมืออีกแบบ
- ค่อยสรุปคำตอบเมื่อมั่นใจว่ามี context พอ
นี่คือเหตุผลที่คำว่า retrieval ในระบบใหม่ๆ ไม่ได้หมายถึง “หยิบข้อมูลครั้งเดียว” แต่หมายถึง “กระบวนการหา context แบบหลายรอบ”
ถ้าเอาไปใช้กับธุรกิจไทย ภาพจะชัดมากในงานอย่าง:
- AI ผู้ช่วยฝ่ายขายที่ต้องเช็กราคา, เงื่อนไขโปรโมชัน, สต๊อก และเอกสารนำเสนอ
- AI ฝ่ายบริการลูกค้าที่ต้องไล่ดูประวัติลูกค้า, FAQ, policy และ ticket เก่า
- AI ผู้ช่วยฝ่ายกฎหมายหรือจัดซื้อที่ต้องหาข้อกำหนดจากหลายสัญญา
งานเหล่านี้ไม่ค่อยจบด้วยการค้นครั้งเดียว ถ้าระบบไม่มีความสามารถค้นแบบเป็นขั้นตอน มันจะตอบมั่วได้ง่ายมาก
Step 3: ดูเคส Cursor แล้วจะเห็นว่าการทำ index ล่วงหน้าให้ผลทางธุรกิจจริง
หนึ่งในตัวอย่างสำคัญที่คลิปยกมาคือ Cursor ซึ่งหลายคนรู้จักในฐานะ AI coding tool แต่ประเด็นที่ควรสนใจไม่ใช่เรื่องเขียนโค้ดอย่างเดียว คือวิธีคิดเรื่อง “ทำดัชนีล่วงหน้า” หรือ indexing ก่อนใช้งานจริง
แนวทางของ Cursor คือ เมื่อเปิด codebase ใหม่ ระบบจะ parse, chunk และ embed เนื้อหาก่อน เพื่อให้พร้อมสำหรับ semantic search ตอน runtime นั่นแปลว่า agent ไม่ต้องเริ่มหาทุกอย่างใหม่จากศูนย์ในทุกคำถาม
สิ่งที่ฉลาดกว่านั้นคือทีม Cursor ไม่ได้ยอมจ่ายต้นทุนนี้ซ้ำๆ แบบไม่คิด เขาพบว่าในทีมใหญ่ คนจำนวนมากมักเปิด codebase ชุดเดียวกัน จึงใช้วิธีเช็กความคล้ายกันของข้อมูล แล้วอัปเดตเฉพาะส่วนที่เปลี่ยน แทนที่จะ re-embed ทั้งหมดทุกครั้ง

มุมนี้สำคัญกับธุรกิจมาก เพราะมันสะท้อนหลักคิดเรื่องต้นทุน AI ที่ถูกต้อง เราไม่ควรคิดแค่ว่า embedding แพงหรือไม่แพง แต่ควรถามว่า:
- ข้อมูลนี้ถูกใช้ซ้ำบ่อยแค่ไหน
- มีคนถามเรื่องเดิมบ่อยหรือไม่
- ถ้าจ่ายต้นทุนล่วงหน้าแล้ว จะลดต้นทุนตอนใช้งานได้เท่าไร
ในคลิปมีการอ้างตัวเลขจาก Cursor ว่า semantic search ช่วยเพิ่มความแม่นยำของคำตอบได้ราว 12 ถึง 13 เปอร์เซ็นต์โดยเฉลี่ย และในบาง model เพิ่มได้เกือบ 24 เปอร์เซ็นต์ นี่ยังไม่รวมผลเชิงประสบการณ์ใช้งานที่ดีขึ้น
ตัวเลข 2.6 เปอร์เซ็นต์หรือ 2.2 เปอร์เซ็นต์อาจดูน้อยในแวบแรก แต่จริงๆ แล้วเป็นตัวเลขที่มีนัยทางธุรกิจ ถ้าระบบถูกใช้ในสเกลใหญ่ และที่สำคัญ semantic search ไม่ได้ถูกเรียกใช้ทุกคำถาม ดังนั้นเฉพาะคำถามที่เกี่ยวข้อง ผลกระทบจริงอาจสูงกว่าที่เห็นจากค่าเฉลี่ยรวม

ถ้าเอามาแปลเป็นโลกธุรกิจไทย เช่น ระบบ AI ตอบข้อมูลสินค้าให้ทีมขาย ถ้าความแม่นยำดีขึ้นแม้ไม่กี่เปอร์เซ็นต์ แต่ลดการเสนอราคาผิด ลดการตอบนโยบายผิด หรือช่วยให้ปิดดีลเร็วขึ้น ผลลัพธ์ทางธุรกิจอาจคุ้มกว่าค่า token มาก
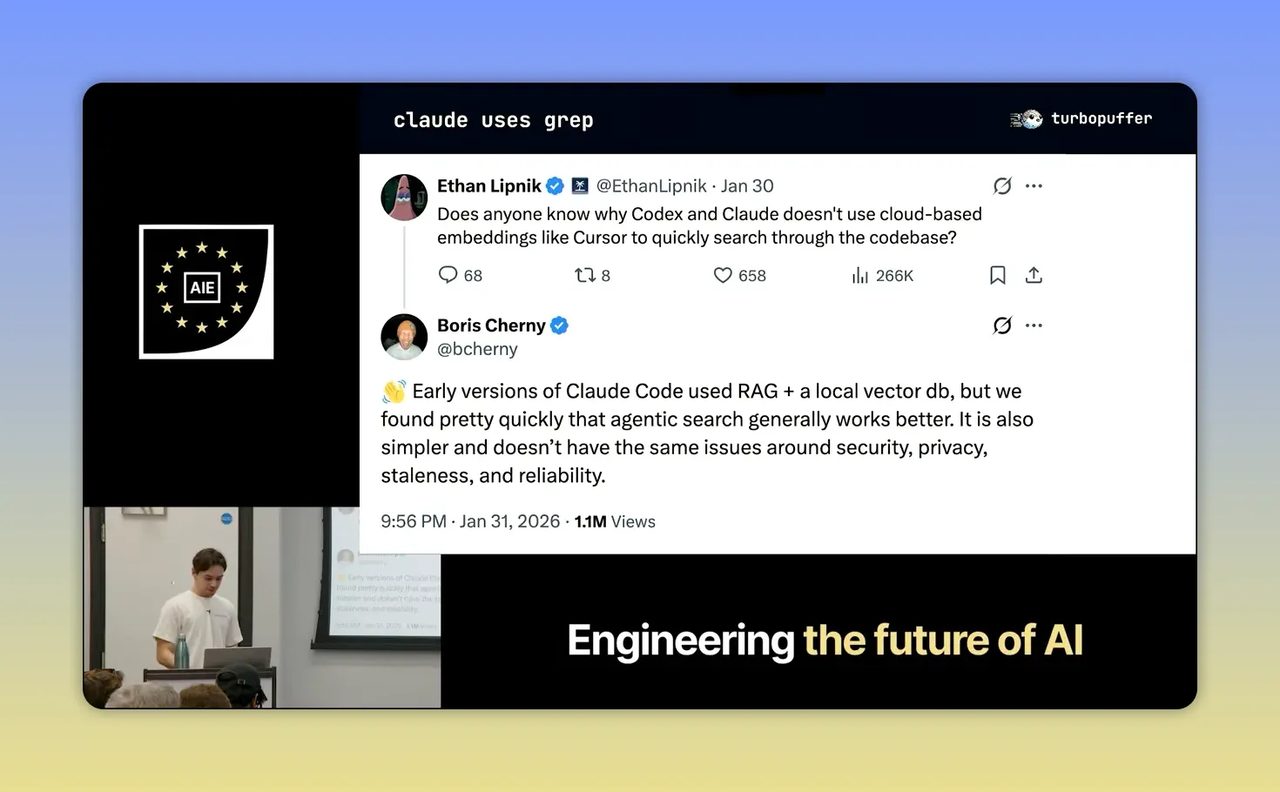
Step 4: เข้าใจ trade-off ของ Claude Code กับ Cursor แล้วจะออกแบบระบบได้ฉลาดขึ้น
อีกช่วงหนึ่งของคลิปที่มีประโยชน์มาก คือการเปรียบเทียบแนวทางคล้าย Claude Code กับแนวทางคล้าย Cursor
ฝั่งแรกคือระบบที่แทบไม่พึ่ง vector search แต่ใช้การไล่ค้นจาก file system ตาม session จริง ข้อดีคือไม่ต้องมีต้นทุนเตรียมข้อมูลมาก ไม่ต้องทำ index ขนาดใหญ่ล่วงหน้า และเหมาะกับงานที่ข้อมูลเปลี่ยนเร็วหรือมี query volume ไม่สูง
ข้อเสียคือทุกครั้งที่ agent ต้องเข้าใจเรื่องเดิม มันต้อง grep, อ่าน, ประเมิน และวนใหม่อีกครั้ง ต้นทุนจึงเกิดซ้ำทุก session
ฝั่ง Cursor คือจ่ายต้นทุนก่อน เพื่อให้ตอนใช้งานค้นได้ไวกว่า เบากว่า และประหยัด token กว่า
สิ่งสำคัญคือคลิปไม่ได้บอกว่าฝั่งหนึ่งถูกอีกฝั่งผิด แต่บอกว่าแต่ละแบบเป็น trade-off
นี่เป็นมุมที่เราเห็นด้วยมาก เพราะหลายองค์กรชอบถามว่า “ควรใช้ RAG หรือ agent” ทั้งที่คำตอบจริงมักเป็น “ขึ้นกับรูปแบบการใช้งาน” เช่น
- ถ้าข้อมูลคงที่พอสมควร และมีคนถามซ้ำเยอะ ควรทำ index ล่วงหน้า
- ถ้าข้อมูลเปลี่ยนตลอด หรือใช้งานไม่ถี่มาก อาจใช้การค้นสดในแต่ละรอบ
- ถ้างานสำคัญและซับซ้อน ควรมีทั้งสองแบบร่วมกัน
Step 5: ใช้มุมคิด “embeddings are cached compute” เพื่อคุมต้นทุน AI
ประโยคที่คมที่สุดช่วงกลางคลิปคือ embedding และ semantic search ควรถูกมองเป็น cached compute หรือการคำนวณที่เราทำเก็บไว้ล่วงหน้า
ฟังเผินๆ อาจเหมือนเทคนิคฝั่งวิศวกรรม แต่สำหรับคนทำธุรกิจ มันคือกรอบคิดด้านการเงินเลย
ลองนึกภาพสองแบบ:
- แบบแรก ไม่เก็บอะไรไว้ ทุกครั้งที่ถาม AI ต้องเริ่มไล่หาใหม่ทั้งหมด
- แบบสอง ยอมประมวลผลล่วงหน้า แล้วเก็บ index ไว้ให้เรียกใช้ได้ทันที
นี่ไม่ต่างจากการเลือกว่าจะทำครัวกลางไว้ก่อน หรือทำอาหารใหม่ทุกจานแบบเริ่มจากศูนย์ ถ้าออร์เดอร์น้อยมาก การเตรียมล่วงหน้าอาจไม่คุ้ม แต่ถ้าออร์เดอร์เยอะ การเตรียมไว้ก่อนย่อมเร็วกว่าและต้นทุนรวมต่ำกว่า
เพราะฉะนั้นคำถามที่ผู้บริหารควรถามทีม ไม่ใช่แค่ “ทำ RAG ได้ไหม” แต่ควรถามเพิ่มว่า:
- คำถามเดิมเกิดซ้ำบ่อยแค่ไหน
- ข้อมูลก้อนนี้เปลี่ยนบ่อยหรือเปล่า
- ต้นทุน index ล่วงหน้า เทียบกับต้นทุนค้นสด อันไหนคุ้มกว่า
- งานนี้ต้องการความเร็วหรือความสดของข้อมูลมากกว่ากัน
สำหรับองค์กรไทยที่เริ่มทำ AI internal search เรามองว่ามีหลายเคสที่การทำ embedding ล่วงหน้าคุ้ม เช่น คู่มือพนักงาน, knowledge base ฝ่ายขาย, เอกสารอบรม, คู่มือผลิตภัณฑ์ และคลังคำตอบของ support
แต่ถ้าเป็นข้อมูลที่เปลี่ยนทุกนาที เช่น ราคาที่อัปเดตตลอด, สถานะสต๊อกสด, transaction ล่าสุด เราอาจต้องออกแบบให้ retrieval มีทั้งส่วน cached และส่วนสดประกบกัน
Step 6: อย่าหลงกับ context window ใหญ่ จงหาข้อมูลที่ใช่ให้เจอ
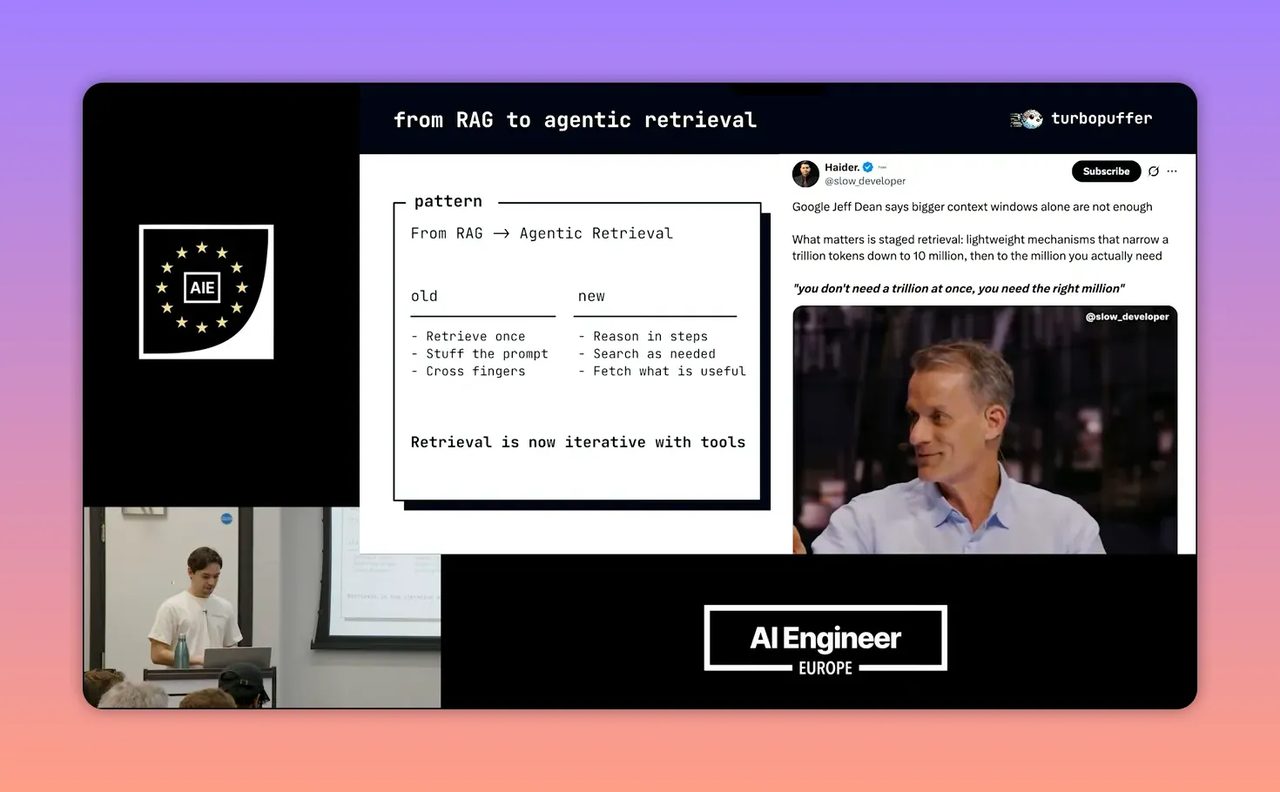
ช่วงท้ายคลิปมีแนวคิดที่ทรงพลังมาก โดยอ้างคำพูดของ Jeff Dean จาก Google ว่า ต่อให้ model มี context window ใหญ่มหาศาล ก็ไม่ได้หมายความว่าเราควรยัดทุกอย่างเข้าไปพร้อมกัน สิ่งที่ต้องการจริงๆ คือ “ล้าน token ที่ใช่” ไม่ใช่ “ล้านล้าน token ทั้งหมด”
นี่คือหัวใจของ retrieval ที่ดี
หลายทีมยังมีภาพฝันว่า model รุ่นใหม่ที่ context ยาวมากจะทำให้ไม่ต้องทำ search หรือ filtering แล้ว แต่มุมนี้ค่อนข้างอันตราย เพราะข้อมูลเยอะไม่ได้แปลว่าคำตอบดีเสมอไป ถ้าเราใส่ข้อมูลไม่เกี่ยวข้องเข้าไปมากเกิน model ก็เสียทั้งเงิน เวลา และโฟกัส
ในทางปฏิบัติ ระบบที่ดีควรทำ staged retrieval หรือการค่อยๆ บีบข้อมูลจากกองใหญ่ลงมาเป็นกองเล็กที่เกี่ยวข้องจริง เช่น:
- คัดจาก metadata ก่อน เช่น แผนก, วันที่, ประเภทเอกสาร
- ใช้ full-text หรือ keyword หาฉบับที่น่าจะใช่
- ใช้ semantic search เพื่อหาเนื้อหาที่ใกล้เคียงคำถาม
- ให้ agent อ่านเฉพาะส่วนที่จำเป็น แล้วค่อยสรุป
แนวคิดนี้ใช้ได้กับแทบทุกธุรกิจ ไม่ว่าจะเป็นประกัน, โรงพยาบาล, อสังหา, การศึกษา หรือค้าปลีก เพราะทุกที่มีปัญหาเหมือนกัน คือข้อมูลเยอะ แต่ข้อมูลที่ “ใช่” มีน้อย
Step 7: เปลี่ยนบทเรียนจากคลิปให้เป็นระบบ AI ที่ใช้จริงในธุรกิจไทย
ถ้าสรุปเป็นมุมปฏิบัติสำหรับธุรกิจไทย บทเรียนจากคลิปนี้มีอย่างน้อย 4 ข้อ
- อย่านิยาม RAG แคบเกินไป เพราะ retrieval ที่ดีต้องใช้หลายเครื่องมือร่วมกัน
- อย่าคิดว่า agent แทน search ได้หมด agent ที่ดีต้องมี search ที่ดีเป็นฐาน
- อย่ามอง embedding เป็นค่าใช้จ่ายล้วนๆ แต่ให้มองเป็นการลงทุนล่วงหน้าเพื่อประหยัด runtime
- อย่าคิดว่า context window ใหญ่จะแก้ทุกอย่าง เพราะการคัดข้อมูลยังสำคัญมาก
เราเห็นด้วยกับทิศทางหลักของคลิป แต่ก็มีข้อควรระวังหนึ่งอย่าง คือหลายองค์กรอาจฟังแล้วอยากกระโดดไปทำระบบ retrieval ซับซ้อนเกินจำเป็น ทั้งที่ปริมาณข้อมูลและจำนวนคำถามยังไม่มาก
ดังนั้นสิ่งที่ควรทำก่อนเสมอคือวัดให้ได้ว่า:
- คำถามแบบไหนเจอบ่อย
- ข้อมูลแบบไหนตอบยาก
- คำตอบผิดเพราะค้นไม่เจอ หรือเพราะ model สรุปผิด
ถ้าวัดตรงนี้ไม่ได้ ต่อให้มีระบบ agentic retrieval สวยแค่ไหน ก็อาจยังไม่คุ้ม
สำหรับคนที่อยากอ่านต่อเรื่องแนวทาง search และ ranking สามารถดูข้อมูลเสริมจาก Pinecone และหลักการค้นแบบ BM25 เพื่อเข้าใจว่าทำไม keyword search ยังสำคัญแม้ในยุค AI
Actionable Insights
- เริ่มจาก map ว่า AI ของเราต้องเข้าถึงข้อมูลประเภทไหนบ้าง แล้วแยกว่าอะไรเหมาะกับ semantic search และอะไรเหมาะกับ keyword search
- ถ้ามีคำถามซ้ำเยอะ ให้ลองทำ index ล่วงหน้ากับข้อมูลที่คงที่ก่อน เช่น FAQ, คู่มือ, policy
- ออกแบบ retrieval เป็นหลายชั้น อย่าใช้ vector search แบบยิงครั้งเดียวแล้วจบ
- วัดผลจากธุรกิจจริง เช่น อัตราตอบผิด, เวลาหาคำตอบ, อัตราส่งต่อให้คน ไม่ใช่วัดแค่ demo ที่ดูฉลาด
- ถ้าจะทำ AI agent ให้เริ่มจากการให้เครื่องมือค้นที่เหมาะก่อน ค่อยเพิ่มความสามารถ reasoning ภายหลัง
Troubleshooting
- ปัญหา: AI ตอบคล้ายถูก แต่รายละเอียดผิด
สาเหตุ: ใช้ semantic search อย่างเดียว จึงหาเอกสารใกล้เคียงแต่ไม่ใช่ฉบับจริง
วิธีแก้: เพิ่ม full-text search, filter ตาม metadata และบังคับให้ระบบดึงแหล่งอ้างอิงที่ตรงคำถามก่อนสรุป - ปัญหา: ระบบช้าและค่า token สูงมาก
สาเหตุ: agent ต้องค้นใหม่ทุกครั้งโดยไม่มี index หรือ cache ล่วงหน้า
วิธีแก้: เลือกข้อมูลที่ถูกใช้ซ้ำบ่อยมาทำ embedding และ index เก็บไว้ก่อน - ปัญหา: ข้อมูลเยอะแต่ AI ยังตอบไม่ตรง
สาเหตุ: ส่ง context เข้า model มากเกินไปโดยไม่ได้คัดกรอง
วิธีแก้: ทำ staged retrieval ลดข้อมูลจากกองใหญ่ลงมาเป็นเฉพาะส่วนที่เกี่ยวข้องจริง - ปัญหา: ลงทุนทำ RAG แล้วทีมบอกว่าไม่คุ้ม
สาเหตุ: ใช้กับงานที่ query น้อย หรือข้อมูลเปลี่ยนเร็วเกินไป
วิธีแก้: แยกงานที่ควรค้นสดออกจากงานที่ควรทำ index และวัด usage จริงก่อนขยายระบบ
การต่อยอด
- ทำ hybrid search สำหรับ knowledge base ภายในองค์กร โดยรวม keyword, semantic และ metadata filtering ไว้ใน workflow เดียว
- สร้าง AI assistant สำหรับฝ่ายขายหรือ support ที่รู้จักค้นหลายรอบก่อนตอบ ไม่ใช่ตอบจากผลลัพธ์ชุดเดียว
- ทำ dashboard วัด retrieval quality เช่น เอกสารที่ถูกเรียกใช้บ่อย, คำถามที่หาไม่เจอ, ค่าใช้จ่ายต่อคำตอบ เพื่อใช้ตัดสินใจว่าจะ cache ตรงไหนเพิ่ม
Step 8: สรุป Checklist ทั้งหมด
- เข้าใจใหม่ว่า RAG ไม่ได้เท่ากับ vector search อย่างเดียว
- แยกประเภทข้อมูลว่าอะไรควรใช้ semantic search อะไรควรใช้ keyword search
- ออกแบบ retrieval ให้เป็นหลายรอบ ไม่ใช่ค้นครั้งเดียวแล้วจบ
- ประเมินว่าเคสของเราเหมาะกับการทำ index ล่วงหน้าหรือค้นสด
- มอง embedding เป็น cached compute ไม่ใช่ต้นทุนเปล่า
- วัดผลจากความแม่นยำ ความเร็ว และผลลัพธ์ทางธุรกิจจริง
- ลดการยัดข้อมูลทั้งหมดเข้า context แล้วหันมาคัดข้อมูลที่ใช่
- เริ่มจาก use case เล็กที่มีคำถามซ้ำสูงก่อนค่อยขยาย
ถ้าจะสรุปคลิปนี้เป็นประโยคเดียว ก็คือ RAG ยังไม่ตาย แต่มันกำลังเปลี่ยนจากสูตรสำเร็จง่ายๆ ไปเป็นระบบ retrieval ที่ฉลาดขึ้นและใช้หลายเครื่องมือร่วมกัน สำหรับองค์กรที่อยากเอา AI ไปใช้จริง บทเรียนสำคัญจึงไม่ใช่การวิ่งตามคำฮิต แต่คือการออกแบบให้ AI หาข้อมูลที่ใช่ได้เร็วพอ แม่นพอ และคุ้มพอสำหรับงานของเรา