
สรุปจากคลิป ดูคลิปต้นฉบับ
Gemini Audio Stack จากถอดเสียงสู่เพลงสด AI ใช้กับธุรกิจได้แค่ไหน

ถ้าเรายังคิดว่า AI ด้านเสียงมีหน้าที่แค่ถอดคำพูดเป็นตัวอักษร เราอาจกำลังมองของจริงเล็กไปมาก คลิปจากช่อง AI Engineer ที่พาไปดูงานของ Google DeepMind ทำให้เห็นชัดว่า audio stack รุ่นใหม่ไม่ได้หยุดที่การฟังออก แต่กำลังก้าวไปสู่การเข้าใจอารมณ์ แยกผู้พูด แปลภาษา สร้างเสียงพูดแบบกำกับโทนได้ และต่อยอดไปถึงการสนทนาแบบเรียลไทม์รวมถึงการสร้างเพลงได้ใน flow เดียว
ประเด็นที่น่าสนใจไม่ใช่แค่เดโมที่ดูหวือหวา แต่คือคำถามว่า ถ้าเอาสิ่งนี้มาใช้กับงานจริงของธุรกิจไทย หน้าตาจะเป็นอย่างไร อะไรคือของที่พร้อมใช้แล้ว อะไรยังเป็นของโชว์ศักยภาพ และอะไรที่เราควรระวังก่อนเอา AI ไปใส่ในงานลูกค้า งานขาย หรือบริการหลังการขาย
สารบัญ
- Step 1: มอง AI Audio ให้เกินคำว่า ถอดเสียง
- Step 2: ใช้การวิเคราะห์เสียงแบบครบชุดใน API call เดียว
- Step 3: ออกแบบผลลัพธ์ให้พร้อมใช้งาน ไม่ใช่แค่พร้อมอ่าน
- Step 4: สร้างเสียงพูดแบบกำกับการแสดง แทนการเลือกจากแค็ตตาล็อก
- Step 5: ใช้ Gemini Live สำหรับบทสนทนาเสียงแบบเรียลไทม์
- Step 6: เข้าใจว่า multimodal ไม่ได้แปลว่าใช้ได้ทุกงานทันที
- Step 7: ใช้เครื่องมือทดลองให้เป็น ก่อนลงทุนทำระบบเต็ม
- Step 8: มองเพลง AI เป็นมากกว่าของเล่น
- Step 9: แปลงบทเรียนจากคลิปเป็นมุมมองสำหรับธุรกิจไทย
- Actionable Insights
- Troubleshooting
- การต่อยอด
- สรุป Checklist ทั้งหมด
Step 1: มอง AI Audio ให้เกินคำว่า ถอดเสียง
แกนหลักของงานนี้คือแนวคิดว่า AI audio ที่ดีไม่ควรทำหน้าที่แปลงเสียงเป็นข้อความอย่างเดียว แต่ต้องเข้าใจสิ่งที่แฝงอยู่ในเสียงด้วย เช่น ใครเป็นคนพูด พูดภาษาอะไร น้ำเสียงเป็นมิตรหรือกดดัน มีการสลับภาษาระหว่างพูดหรือไม่ หรือแม้แต่มีคนพูดทับกันอยู่หรือเปล่า
นี่คือจุดต่างระหว่างระบบถอดเสียงแบบเดิมกับโมเดลสาย multimodal รุ่นใหม่ของ Gemini เพราะถ้า AI เข้าใจแค่คำพูด ธุรกิจจะได้เพียงบันทึกการสนทนา แต่ถ้าเข้าใจน้ำเสียงและโครงสร้างของบทสนทนาด้วย เราจะเริ่มนำไปใช้กับงานวิเคราะห์คุณภาพบริการ งานสรุปประชุม งานตรวจ call center และงานขายได้จริง
สำหรับธุรกิจไทย ความต่างนี้สำคัญมาก เพราะการสนทนาในโลกจริงไม่ได้พูดชัดทุกคำ ไม่ได้พูดภาษาเดียวตลอด และมักมีคำทับศัพท์ ภาษาอังกฤษ หรือชื่อเฉพาะแทรกอยู่เสมอ ถ้าระบบไม่เข้าใจสิ่งเหล่านี้ ผลลัพธ์ปลายทางจะพังตั้งแต่ต้นน้ำ
Step 2: ใช้การวิเคราะห์เสียงแบบครบชุดใน API call เดียว
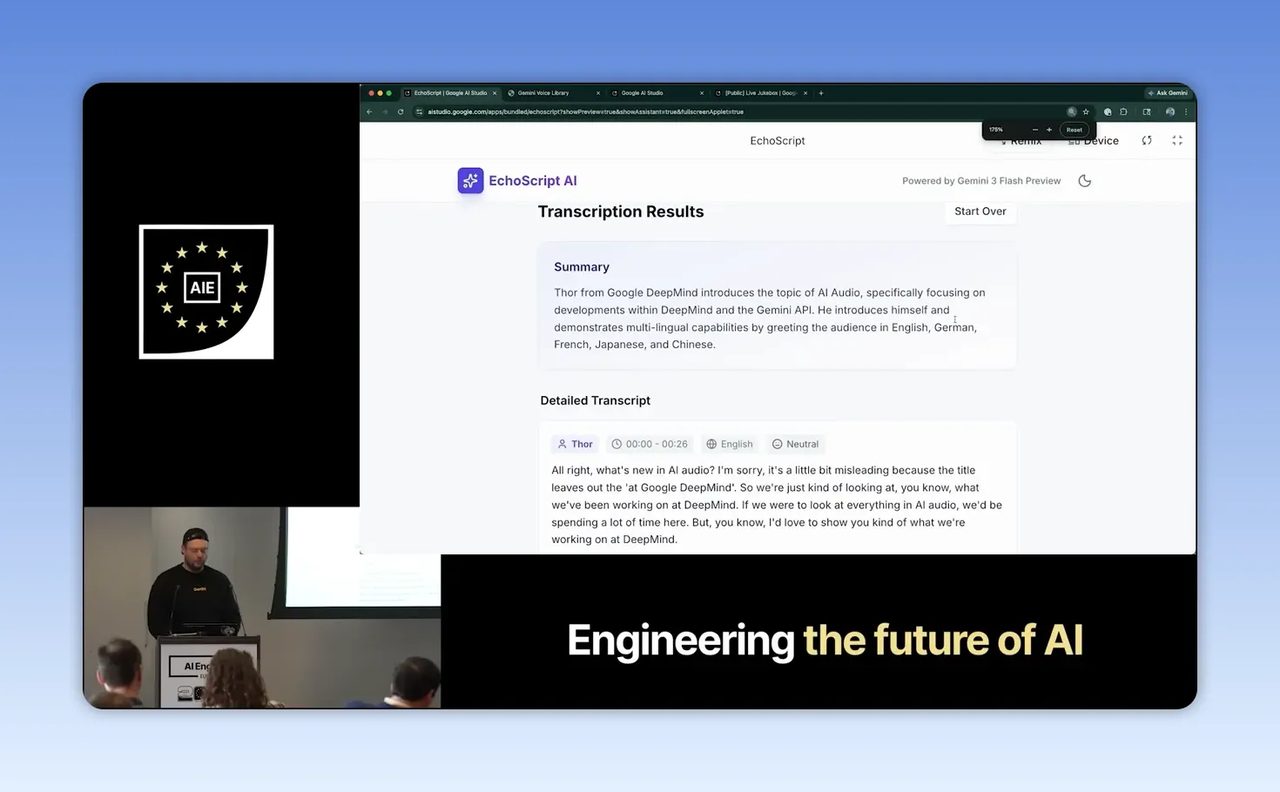
เดโมที่เด่นที่สุดช่วงต้นคือการใช้ Gemini วิเคราะห์ไฟล์เสียงครั้งเดียว แล้วคืนผลลัพธ์ออกมาเป็นชุดข้อมูลที่พร้อมใช้ต่อทันที ไม่ใช่แค่ข้อความถอดเสียง แต่มีทั้ง:
- สรุปภาพรวมของเนื้อหา
- แยกผู้พูดเป็นช่วงเวลา
- ติดป้ายชื่อผู้พูดเมื่อมีข้อมูลอ้างอิง
- ระบุ timestamp
- ตรวจจับภาษา
- แปลเป็นอังกฤษเมื่อไม่ใช่ภาษาอังกฤษ
- ตีความอารมณ์แบบคร่าวๆ เช่น สุข เศร้า โกรธ หรือกลางๆ
สิ่งที่ควรคิดต่อในมุมธุรกิจคือ เมื่อ output ถูกจัดรูปเป็น structured data ตั้งแต่ต้น เราไม่จำเป็นต้องมีทีมเทคนิคใหญ่เพื่อเอาไปต่อแดชบอร์ดหรือ CRM ทันที งานประเภท “ฟังทั้งหมดแล้วค่อยนั่งสรุป” สามารถย่อเหลือ “อัปโหลดเสียงแล้วแปลงเป็นข้อมูลพร้อมใช้” ได้เลย
ตัวอย่างที่เห็นภาพสำหรับธุรกิจไทย ได้แก่
- ทีมเซลส์อัปโหลดไฟล์คุยลูกค้า แล้วให้ระบบสรุป pain point กับ next step
- ฝ่ายบริการลูกค้าตรวจบทสนทนาที่อารมณ์ลูกค้าเริ่มตึง เพื่อใช้โค้ชทีม
- ผู้บริหารอัดประชุมแล้วให้ AI แยกคนพูดพร้อมสรุปประเด็น
- ธุรกิจท่องเที่ยวหรือโรงพยาบาลที่รับหลายภาษา ใช้ตรวจจับภาษาและแปลอัตโนมัติ
อย่างไรก็ตาม เราควรเห็นข้อจำกัดด้วย การตีความอารมณ์จากเสียงยังไม่ใช่ความจริง 100 เปอร์เซ็นต์ ภาษาและสำเนียงมีผลมาก บางภาษาฟังดูแข็งโดยธรรมชาติแต่ไม่ได้แปลว่าโกรธ ดังนั้นถ้าจะใช้กับงานสำคัญ เช่น ประเมินพนักงาน หรือวัดคุณภาพบริการ ควรใช้เป็นตัวช่วยคัดกรอง ไม่ใช่คำตัดสินสุดท้าย
Step 3: ออกแบบผลลัพธ์ให้พร้อมใช้งาน ไม่ใช่แค่พร้อมอ่าน
จุดที่หลายองค์กรพลาดคือใช้ AI แล้วได้ output เป็นย่อหน้ายาวๆ สวยแต่ต่อระบบไม่ได้ สิ่งที่งานนี้ชี้ให้เห็นคือควรบอกโมเดลให้คืนคำตอบตาม schema ที่ชัดเจน เช่น speaker, start time, end time, language, emotion, summary
ความหมายเชิงปฏิบัติคือ เราควรเริ่มจากคำถามว่า “ทีมจะเอาข้อมูลนี้ไปทำอะไรต่อ” ไม่ใช่เริ่มจาก “AI ทำอะไรได้บ้าง” ถ้าปลายทางคือ dashboard ผู้จัดการทีมขาย เราต้องเก็บ field แบบไหน ถ้าปลายทางคือระบบ ticket support เราต้องดึง intent หรือ urgency ออกมาด้วยหรือไม่
นี่เป็นวิธีคิดแบบเจ้าของธุรกิจ ไม่ใช่แบบโชว์เดโม และเป็นสิ่งที่ทำให้ AI กลายเป็น workflow จริง
Step 4: สร้างเสียงพูดแบบกำกับการแสดง แทนการเลือกจากแค็ตตาล็อก
อีกช่วงที่น่าสนใจมากคือ speech generation แทนที่จะเลือกเสียงจากลิสต์ยาวๆ ตามเพศ อายุ หรือสำเนียงเพียงอย่างเดียว แนวทางของ Gemini คือมีชุดเสียงตั้งต้นไม่มากนัก แล้วให้เรา “กำกับ” เสียงนั้นผ่าน prompt คล้ายกับบรีฟนักพากย์
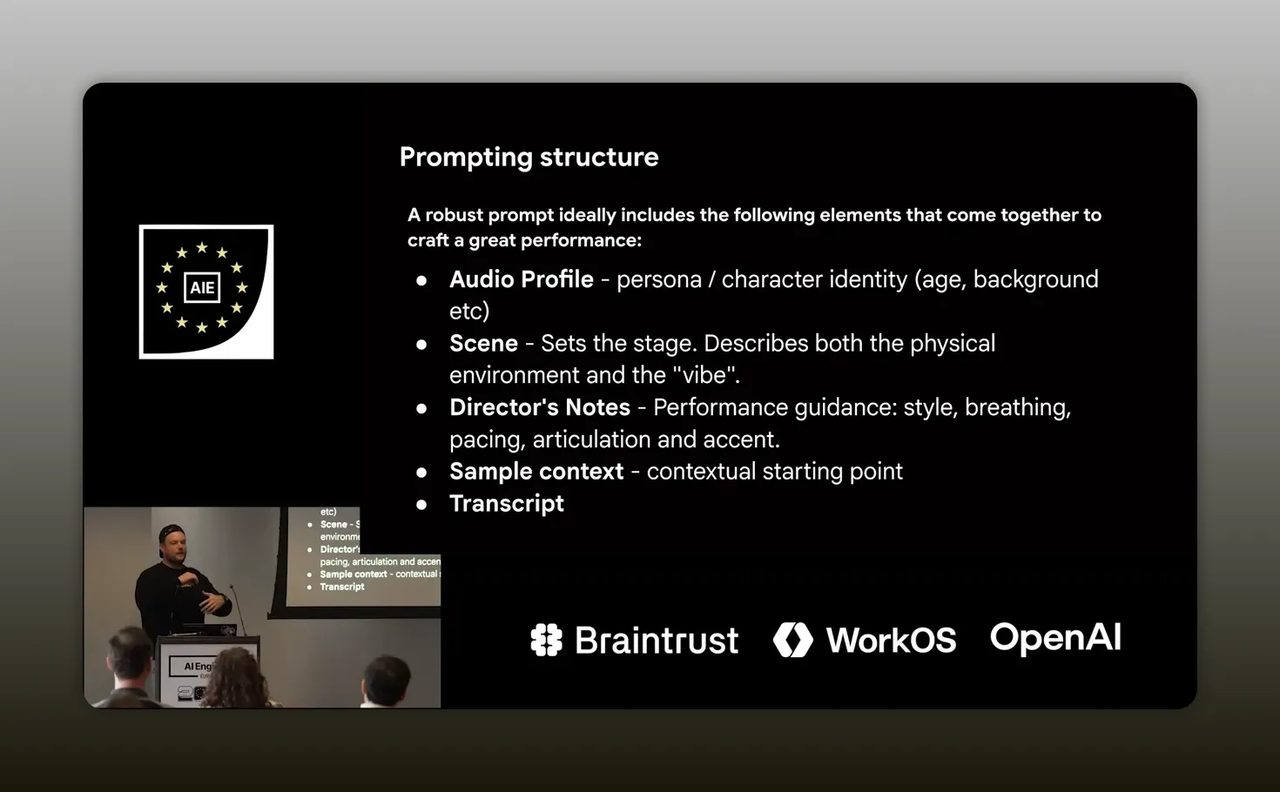
โครงสร้างที่ใช้ประกอบด้วยหลายชั้น เช่น
- Audio profile กำหนดตัวตนของเสียง
- Scene กำหนดฉากหรือสภาพแวดล้อม
- Director's notes บอกจังหวะ การหายใจ วิธีปล่อยอารมณ์
- Sample context ให้ตัวอย่างหรือจุดตั้งต้นของบท
- Transcript ข้อความที่ต้องพูด
มุมนี้สำคัญมากกับงานการตลาดและคอนเทนต์ เพราะมันเปลี่ยนจากการ “หาเสียงที่ใกล้เคียง” ไปเป็น “สั่งให้เสียงเล่นบทบาท” เช่น เสียงพนักงานต้อนรับโรงแรม เสียงพิธีกรโปรโมชัน เสียงผู้ช่วยขายสินค้า หรือเสียงอธิบายสินค้าแบบอบอุ่น
ถ้าคิดต่อในบริบทธุรกิจไทย เราอาจใช้กับงานแบบนี้ได้
- โฆษณาเสียงหลายเวอร์ชันสำหรับ A/B test
- ข้อความตอบรับอัตโนมัติสำหรับคลินิก ร้านอาหาร หรือโรงแรม
- คอนเทนต์สอนใช้งานสินค้าในโทนที่ต่างกันตามกลุ่มลูกค้า
- เสียงบรรยายสินค้าใน marketplace หรือ social commerce
แต่ก็มีข้อควรระวังเหมือนกัน การสร้างเสียงที่ “คล้ายคนจริง” มากขึ้น ทำให้เรื่องความถูกต้องของแบรนด์ยิ่งสำคัญ ถ้า prompt ไม่ดี เสียงอาจหลุดคาแรกเตอร์ หรือพยายามเลียนสำเนียงจนดูแปลก ดังนั้นงานที่เกี่ยวกับภาพลักษณ์แบรนด์ควรมีคนฟังตรวจทุกครั้ง
Step 5: ใช้ Gemini Live สำหรับบทสนทนาเสียงแบบเรียลไทม์
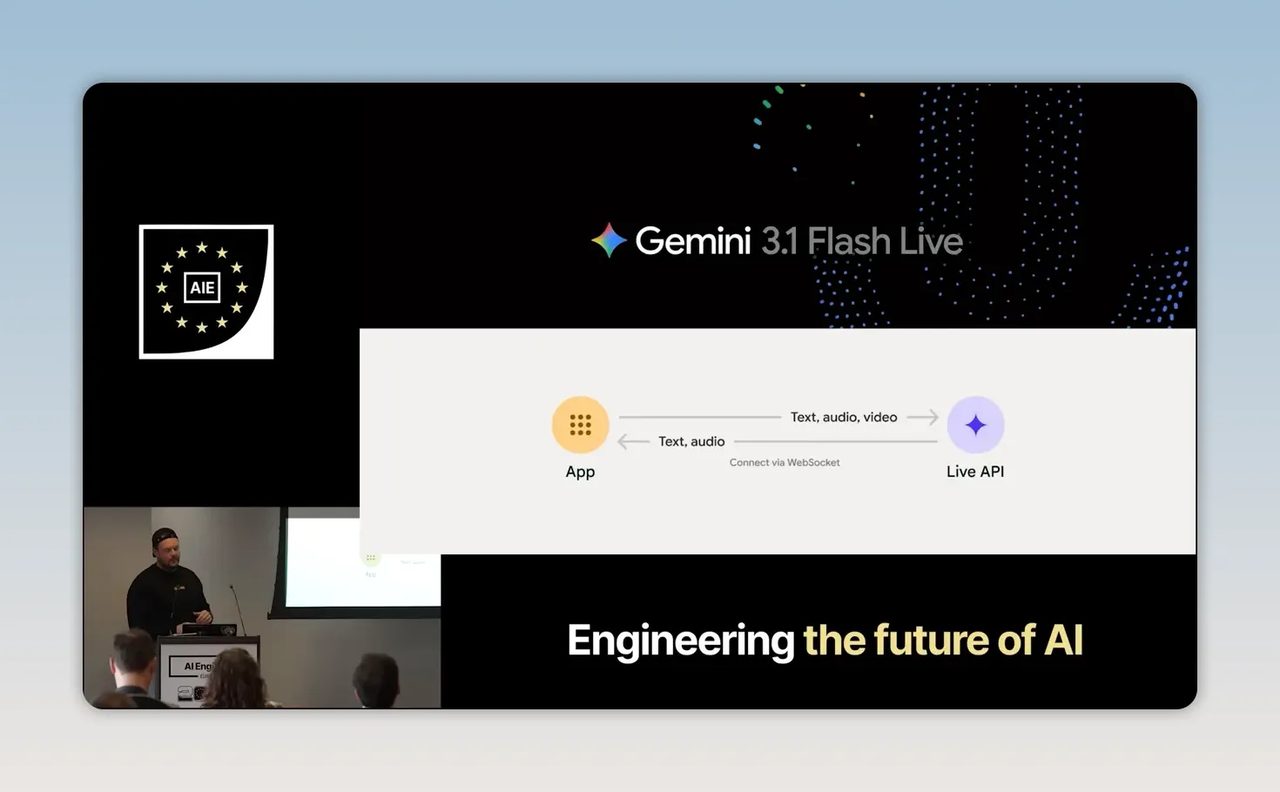
ส่วนที่น่าจับตาที่สุดสำหรับงานบริการคือ Gemini 3.1 Flash Live ซึ่งเป็นโมเดลเสียงแบบ sound-to-sound ที่ทำงานเรียลไทม์ รับได้ทั้งข้อความ เสียง และภาพผ่านการเชื่อมต่อสด แล้วตอบกลับเป็นเสียงทันทีพร้อมข้อความประกอบ
ประเด็นที่ลึกกว่าคำว่าเรียลไทม์ คือโมเดลนี้ไม่ได้ทำงานแบบ pipeline หลายทอดที่เริ่มจากเสียงไปเป็นข้อความ แล้วค่อยส่งต่อให้ LLM คิดคำตอบ จากนั้นค่อยแปลงกลับเป็นเสียงอีกที แต่ความสามารถในการคิดถูกฝังอยู่ในโมเดลเสียงเลย ผลคือการตอบสนองดูเป็นธรรมชาติกว่า และมีโอกาสลดความหน่วงของระบบได้
ในเดโมมีการตั้ง system instruction ให้พูดด้วยสำเนียงเฉพาะ แล้วให้โมเดลรับภาพจากกล้องและตอบเกี่ยวกับสิ่งที่อยู่ตรงหน้าได้ นี่ชี้ให้เห็นว่าระยะถัดไปของ AI assistant ในงานจริงจะไม่ใช่แค่ chatbot แต่คือ agent ที่ฟัง พูด และเห็นสิ่งเดียวกับเรา
ถ้าถามว่าใช้กับธุรกิจไทยได้ยังไง ภาพที่เป็นไปได้มีหลายแบบ
- ผู้ช่วยหน้าร้านที่ตอบคำถามสินค้าได้จากภาพสินค้าและคำถามเสียง
- ระบบช่วยพนักงานหน้าสาขา โดยให้พนักงานยกกล้องไปที่สินค้าแล้วถาม AI ทันที
- ระบบ onboarding ลูกค้าใหม่ที่อธิบายขั้นตอนผ่านเสียงแทนเอกสารยาว
- AI receptionist สำหรับคลินิก โรงแรม หรืออสังหา
แต่ต้องพูดตรงๆ ว่างานเรียลไทม์แบบนี้ยังมีโจทย์ด้านความแม่นยำ ความปลอดภัย และการควบคุมคำตอบสูงมาก โดยเฉพาะถ้าใช้กับข้อมูลสำคัญ เช่น ข้อมูลแพทย์ การเงิน หรือข้อผูกพันทางกฎหมาย เราไม่ควรปล่อยให้ AI คุยสดโดยไร้ขอบเขต ต้องมี guardrail และขอบเขตงานชัดเจน
Step 6: เข้าใจว่า multimodal ไม่ได้แปลว่าใช้ได้ทุกงานทันที
การที่โมเดลรับได้ทั้งเสียงและภาพฟังดูน่าตื่นเต้น แต่ในทางปฏิบัติ เราควรแยกให้ออกระหว่าง “เดโมที่พิสูจน์ความสามารถ” กับ “ระบบพร้อมใช้งานระดับองค์กร”
ตัวอย่างหนึ่งที่น่าสนใจคือ เมื่อสั่งให้โมเดลพูดด้วยสำเนียงไอริช แล้วขอให้แต่งกลอนเป็นภาษาเยอรมัน ระบบยังพยายามคงสำเนียงนั้นไว้แม้จะเปลี่ยนภาษาแล้ว ซึ่งทั้งตลกและมีประโยชน์ เพราะทำให้เห็นชัดว่าคำสั่งระดับ system มีอิทธิพลต่อ output มากแค่ไหน
สำหรับเรา นี่คือบทเรียนเรื่อง prompt governance ถ้าองค์กรจะใช้ AI เสียงกับลูกค้าจริง ต้องกำหนดให้ชัดว่า instruction ไหนเป็นของแบรนด์ Instruction ไหนเป็นของงานเฉพาะหน้า และอะไรที่ห้ามสืบทอดข้ามภาษา ข้าม use case หรือข้าม session
Step 7: ใช้เครื่องมือทดลองให้เป็น ก่อนลงทุนทำระบบเต็ม
อีกจุดที่ดีมากคือหลายอย่างสามารถลองได้ใน Google AI Studio โดยยังไม่ต้องเริ่มจากการเขียนระบบใหญ่หรือใส่บัตรเครดิตทันที แนวทางนี้เหมาะกับเจ้าของธุรกิจและทีม operation มาก เพราะช่วยพิสูจน์ use case ก่อน
ลำดับที่แนะนำคือ
- เริ่มจากเอาไฟล์เสียงจริงขององค์กรไปทดลองวิเคราะห์
- ดูว่าข้อมูลที่ได้ตอบโจทย์การตัดสินใจหรือไม่
- ทดลองหลาย prompt เพื่อหาฟอร์แมตที่ใช้ได้จริง
- ค่อยตัดสินใจว่าจะต่อเข้าระบบภายในหรือใช้แบบกึ่ง manual ไปก่อน
แนวทางนี้ดีกว่าการเริ่มด้วยโปรเจกต์ใหญ่ เพราะหลายครั้งปัญหาไม่ใช่เทคโนโลยี แต่เป็นการที่องค์กรยังตอบไม่ได้ว่าต้องการ output แบบไหนกันแน่
Step 8: มองเพลง AI เป็นมากกว่าของเล่น
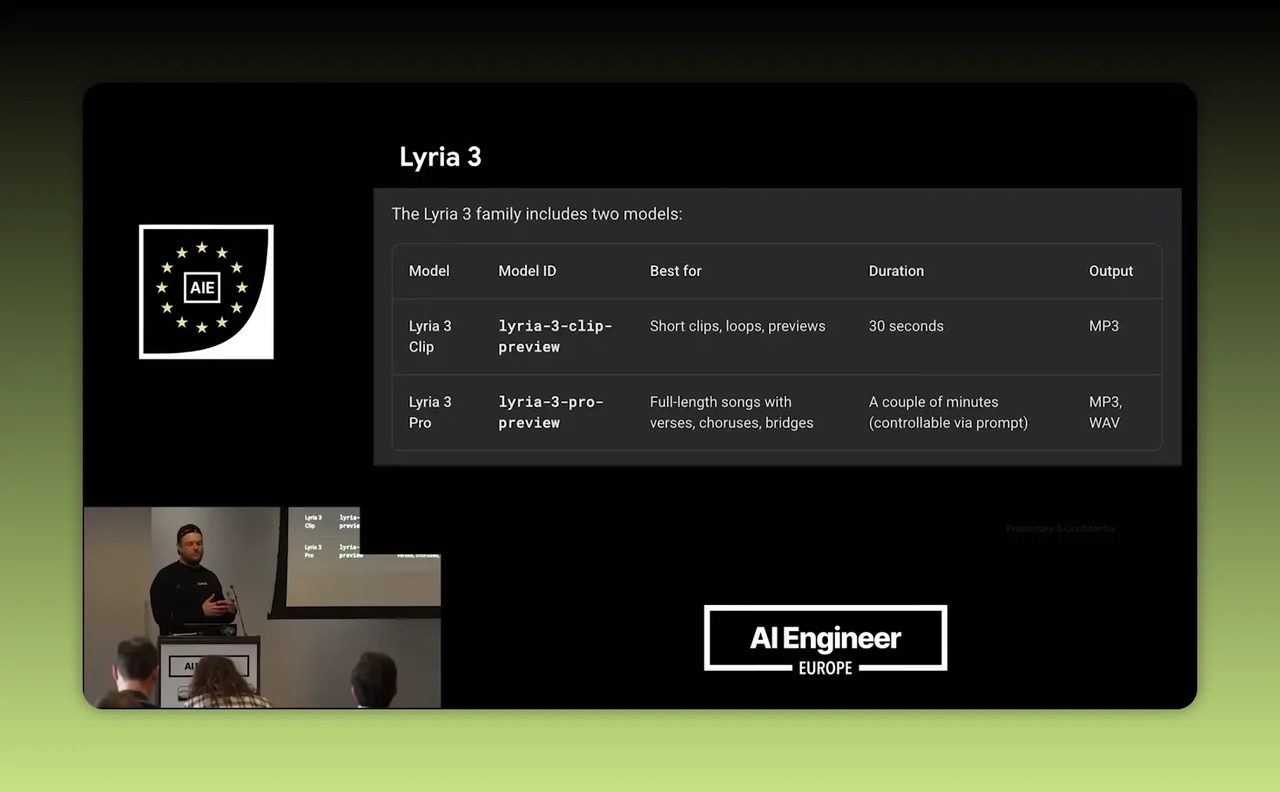
ช่วงท้ายของงานพูดถึง Lyria 3 โมเดลสร้างเพลงของ Google DeepMind ซึ่งตอนนี้ทำเพลงพร้อมเนื้อร้องได้แล้ว โดยมีทั้งรุ่นที่เน้นงานสั้นประมาณจิงเกิล และรุ่นที่ทำเพลงเต็มความยาว
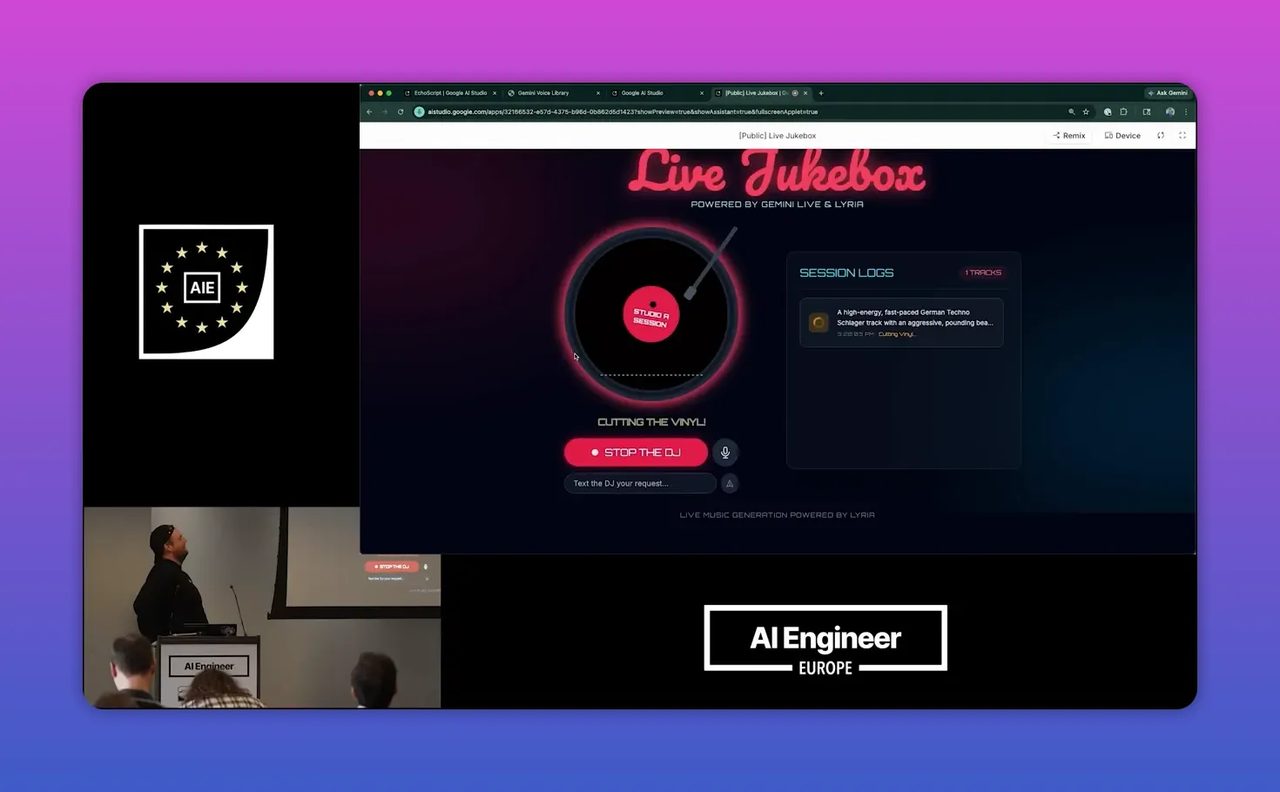
เดโมที่สนุกคือการให้ Gemini Live ทำหน้าที่เหมือนดีเจรับคำขอ แล้วเรียกใช้ Lyria ผ่าน tool use เพื่อสร้างเพลงตามโจทย์สดๆ นี่ไม่ใช่แค่โชว์ลูกเล่น แต่เป็นตัวอย่างชัดมากของการเอาโมเดลหลายตัวมาทำงานร่วมกันใน workflow เดียว
ในโลกธุรกิจ สิ่งนี้แปลได้หลายแบบ เช่น
- ทำจิงเกิลสั้นสำหรับโฆษณาออนไลน์
- สร้างเพลงพื้นหลังเฉพาะแคมเปญ
- ทำคอนเทนต์ branded entertainment ที่ปรับตามเทศกาล
- สร้างเพลงเฉพาะบุคคลในงานอีเวนต์หรือ CRM campaign
แต่ส่วนตัวมองว่า use case ที่ใกล้ตัวกว่าคือ “prototype เร็ว” มากกว่าการเอาไปเป็น master final สำหรับแบรนด์ใหญ่ทันที เพราะงานเพลงยังมีเรื่องลิขสิทธิ์ คุณภาพการร้อง ความคงเส้นคงวา และความเหมาะสมของเนื้อหาที่ต้องตรวจละเอียด
Step 9: แปลงบทเรียนจากคลิปเป็นมุมมองสำหรับธุรกิจไทย
ถ้าสรุปแบบไม่อวยเกินจริง สิ่งที่ Google DeepMind โชว์ในคลิปนี้ทำให้เห็น 3 เรื่องใหญ่
- AI audio กำลังเปลี่ยนจาก feature เดี่ยวเป็น stack เต็มระบบ
- คุณค่าจริงอยู่ที่การเชื่อมความสามารถหลายชั้นเข้าด้วยกัน
- องค์กรที่ได้ประโยชน์ก่อน คือองค์กรที่ออกแบบ workflow ไม่ใช่แค่ลองของใหม่
มุมที่เราเห็นด้วยมากคือการวาง audio understanding เป็นฐานของทุกอย่าง เพราะถ้าฟังไม่เข้าใจ การสร้างเสียงหรือคุยสดก็เป็นแค่เปลือก แต่จุดที่เราควรเผื่อใจคือเดโมที่ดูดีบนเวทีไม่ได้แปลว่าพร้อมสำหรับทุกภาษา ทุกสำเนียง และทุกสถานการณ์จริง โดยเฉพาะภาษาไทยที่มีโทนเสียง ซ้อนคำ และคำไม่เป็นทางการเยอะมาก
ดังนั้น ถ้าจะเอา AI audio มาใช้จริงในไทย เราควรเริ่มจาก use case ที่เสี่ยงต่ำก่อน เช่น สรุปประชุม คัดหมวดหมู่สายสนทนา หรือสร้างเสียงคอนเทนต์ภายในองค์กร แล้วค่อยไต่ไปสู่งานที่สัมผัสลูกค้าโดยตรง
Actionable Insights
- เริ่มจากงานเสียงที่มีอยู่แล้ว เช่น ประชุม โทรหาลูกค้า หรือ voice note แล้วหา use case ที่ลดเวลางานได้ทันที
- บังคับให้ output เป็นโครงสร้างข้อมูลตั้งแต่แรก เพื่อให้เอาไปต่อระบบได้
- แยก use case ระหว่าง “วิเคราะห์เสียง” กับ “ตอบโต้ด้วยเสียง” เพราะความเสี่ยงไม่เท่ากัน
- ถ้าจะใช้ TTS กับแบรนด์ ให้ทำ prompt template กลางขององค์กร ไม่ให้แต่ละทีมตั้งโทนเอง
- ใช้ AI Studio ทดลองกับข้อมูลจริงก่อน แล้วค่อยคุยเรื่องลงทุนระบบเต็ม
Troubleshooting
- ปัญหา: ผลสรุปเสียงไม่ตรงกับสิ่งที่ทีมต้องการ
สาเหตุ: ขอคำตอบกว้างเกินไป ไม่มี schema ชัดเจน
วิธีแก้: ระบุ field ที่ต้องการ เช่น ผู้พูด ประเด็นหลัก next step และความเสี่ยง ให้ครบก่อนรัน - ปัญหา: AI ตีความอารมณ์ผิด
สาเหตุ: สำเนียง ภาษา และน้ำเสียงจริงซับซ้อนเกิน label ง่ายๆ
วิธีแก้: ใช้อารมณ์เป็นสัญญาณเตือนเบื้องต้น แล้วให้คนตรวจกรณีสำคัญ - ปัญหา: เสียงที่สร้างออกมาไม่ตรงคาแรกเตอร์แบรนด์
สาเหตุ: prompt บรีฟไม่ละเอียดพอ หรือไม่มีตัวอย่างโทนที่ชัด
วิธีแก้: เพิ่ม scene, director's note, ตัวอย่างประโยค และคำที่ห้ามใช้ในเสียงนั้น - ปัญหา: ระบบคุยสดตอบแปลกเมื่อสลับภาษา
สาเหตุ: system instruction ถูกบังคับใช้ข้ามภาษาทั้งหมด
วิธีแก้: เขียนกติกาแยกตามภาษา และกำหนด fallback behavior ให้ชัด - ปัญหา: ทดลองแล้วดูดี แต่เอาเข้าองค์กรจริงไม่ได้
สาเหตุ: ข้ามขั้นการออกแบบ workflow และ owner ของข้อมูล
วิธีแก้: นิยามว่าใครอัปโหลด ใครตรวจ ใครอนุมัติ และข้อมูลจะไปจบที่ระบบไหน
การต่อยอด
- ทำ AI Meeting Assistant ภาษาไทยสำหรับผู้บริหาร ที่สรุปประชุมพร้อม action item อัตโนมัติ
- สร้าง Voice QA สำหรับ call center ที่ช่วยหาสายเสี่ยงหลุดมาตรฐานหรือมีโอกาสปิดการขายพลาด
- พัฒนา branded voice สำหรับธุรกิจที่มีหลายสาขา เพื่อให้ข้อความเสียงและคอนเทนต์พูดมีมาตรฐานเดียวกัน
สรุป Checklist ทั้งหมด
- ☐ เลิกมอง AI audio ว่าเป็นแค่เครื่องถอดเสียง
- ☐ เลือก use case ธุรกิจที่มีข้อมูลเสียงอยู่แล้ว
- ☐ กำหนด output schema ให้พร้อมใช้ต่อ
- ☐ ทดลอง audio understanding กับไฟล์จริงขององค์กร
- ☐ ประเมินว่าต้องใช้แค่การวิเคราะห์ หรือจำเป็นต้องคุยสด
- ☐ ออกแบบ prompt สำหรับ speech generation ให้ละเอียดเหมือนบรีฟนักพากย์
- ☐ วางกติกา system instruction สำหรับงานหลายภาษา
- ☐ ใช้ AI Studio ทดสอบก่อนลงทุนทำระบบเต็ม
- ☐ ตั้งขั้นตอนตรวจคุณภาพโดยคนก่อนใช้กับลูกค้าจริง
- ☐ มองเพลง AI เป็นเครื่องมือสร้างต้นแบบและคอนเทนต์เฉพาะแคมเปญ
สรุปแล้ว Gemini Audio Stack จากคลิปนี้ไม่ได้บอกแค่ว่า Google ทำอะไรได้บ้าง แต่บอกเราด้วยว่าระยะถัดไปของงานเสียงในธุรกิจจะเป็นเรื่องของการเชื่อมการฟัง การเข้าใจ การพูดตอบ และการสร้างสื่อเข้าด้วยกันในระบบเดียว สำหรับเจ้าของธุรกิจและคนทำงานไทย คำถามที่ควรถามต่อไม่ใช่ “มันล้ำไหม” แต่คือ “งานไหนของเราที่ควรเริ่มใช้ก่อน เพื่อให้เห็นผลเร็วและคุมความเสี่ยงได้”