
สรุปจากคลิป ดูคลิปต้นฉบับ
Stop Making Models Bigger: บทเรียน AI ที่สอนให้แก้พฤติกรรม ไม่ใช่เพิ่มขนาด

หลายทีมเริ่มทำ AI สำหรับงานจริงด้วย model ใหญ่ที่สุดที่หาได้ เพราะมันดูเหมือนเป็นทางลัดที่ปลอดภัยที่สุด แต่คลิป Stop Making Models Bigger, Make Them Behave จากช่อง AI Engineer กลับชี้อีกมุมที่น่าสนใจกว่า คือปัญหาหลายอย่างไม่ได้เกิดจาก model “ยังไม่ฉลาดพอ” แต่เกิดจากมัน “ยังทำงานไม่เป็น”
ประเด็นนี้สำคัญมากกับเจ้าของธุรกิจและคนทำงานไทยที่อยากใช้ AI ในองค์กร โดยเฉพาะงานที่ต้องเชื่อมกับฐานข้อมูล เอกสาร ระบบภายใน หรือเครื่องมือเฉพาะทาง เพราะสิ่งที่คุ้มค่ากว่าเสมอ อาจไม่ใช่การอัปเกรดไปใช้ model แพงขึ้น แต่เป็นการฝึกให้ model ขนาดเล็กมีวินัยในการใช้เครื่องมือให้ถูกจังหวะ ถูกลำดับ และแก้ข้อผิดพลาดได้เอง
งานนำเสนอนี้อธิบายเคสของ Snorkel ร่วมกับทีมวิจัยจาก UC Berkeley ที่ทำให้ model ขนาด 4B เอาชนะ model 235B ในงานวิเคราะห์การเงินแบบใช้ tools ได้จริง และต้นทุนการเทรนหนึ่งรอบยังต่ำกว่า 500 ดอลลาร์ด้วย
สารบัญ
- Step 1: เริ่มจากตั้งคำถามใหม่ว่า ปัญหาอยู่ที่ความฉลาด หรืออยู่ที่พฤติกรรม
- Step 2: ดูตัวอย่างให้ชัดว่า model ใหญ่พลาดอย่างไร
- Step 3: สร้างข้อมูลฝึกที่ดีพอ ก่อนคิดเรื่องเทรนเพิ่ม
- Step 4: ใช้ RL เพื่อฝึกพฤติกรรมเฉพาะ ไม่ใช่ยัดความรู้ทุกอย่างลงไป
- Step 5: ออกแบบ environment ให้ AI ทำงานในสนามจริงย่อส่วน
- Step 6: วัดผลที่ปลายทาง แล้วกลับมาดูว่าพฤติกรรมไหนเปลี่ยน
- Step 7: สนใจผลข้างเคียงที่ดี คือฝึกง่าย แต่ส่งผลไปงานยากได้
- Step 8: ใช้ rubric แยกให้ได้ว่า model พลาดตรงไหน
- Step 9: แปลบทเรียนนี้เป็นภาพธุรกิจไทยให้ชัด
- Actionable Insights
- Troubleshooting
- การต่อยอด
- สรุป Checklist ทั้งหมด
Step 1: เริ่มจากตั้งคำถามใหม่ว่า ปัญหาอยู่ที่ความฉลาด หรืออยู่ที่พฤติกรรม
แกนหลักของงานนี้คือการท้าความเชื่อที่พบได้บ่อยในองค์กรว่า ถ้า AI ยังทำงานไม่ได้ดีพอ ให้เปลี่ยนไปใช้ model ใหญ่กว่าเดิมทันที แนวคิดนี้ใช้ได้ในบางกรณี แต่ไม่ใช่ทุกกรณี
สำหรับงานระดับองค์กร โดยเฉพาะงานการเงิน สุขภาพ หรือระบบภายในบริษัท สิ่งที่ต้องคิดไม่ได้มีแค่ความแม่น แต่มีเรื่องต้นทุน ความเร็ว ความปลอดภัย การควบคุมข้อมูล และการ deploy แบบ on-premise เข้ามาเกี่ยวข้องด้วย ยิ่ง model ใหญ่ ภาระเหล่านี้ยิ่งโตตาม
มุมที่น่าสนใจคือ งานบางประเภทไม่ได้ต้องการ “การให้เหตุผลระดับอัจฉริยะ” มากนัก แต่ต้องการ “ลำดับการลงมือทำ” ที่ถูกต้อง เช่น
- เช็กก่อนว่ามีตารางอะไรบ้าง
- ดู schema ก่อนคิวรี
- คิวรีแล้วอ่าน error เป็น
- เจอ error แล้วแก้คำสั่งใหม่
- ตอบเมื่อมีข้อมูลรองรับจริง
ถ้า AI พลาดที่ขั้นตอนเหล่านี้ ต่อให้ model ฉลาดขึ้นก็อาจยังพลาดแบบเดิมอยู่ดี นี่คือ insight ที่เจ้าของธุรกิจควรจำให้ขึ้นใจ เพราะเวลา AI ใช้ไม่ได้ในงานจริง เรามักโทษ model ก่อน ทั้งที่บางครั้งสิ่งที่ต้องแก้คือ workflow และพฤติกรรม
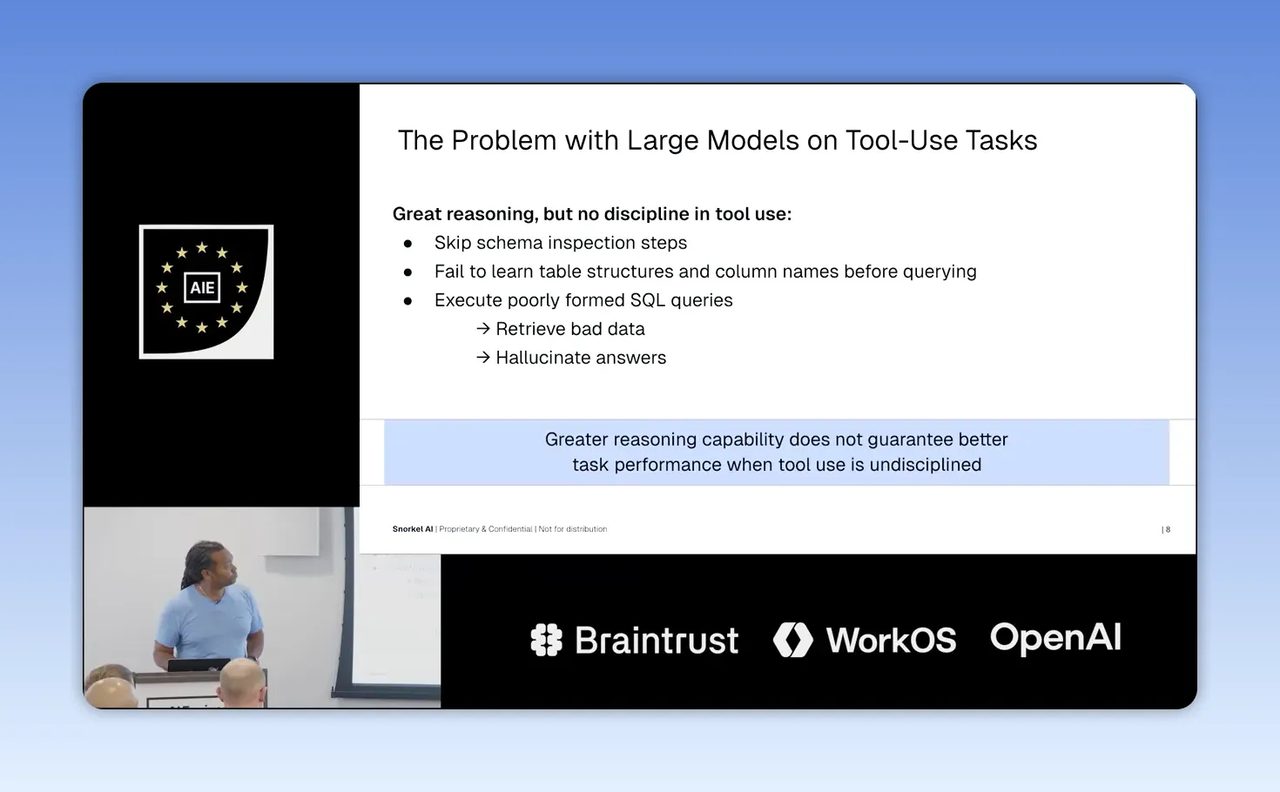
Step 2: ดูตัวอย่างให้ชัดว่า model ใหญ่พลาดอย่างไร
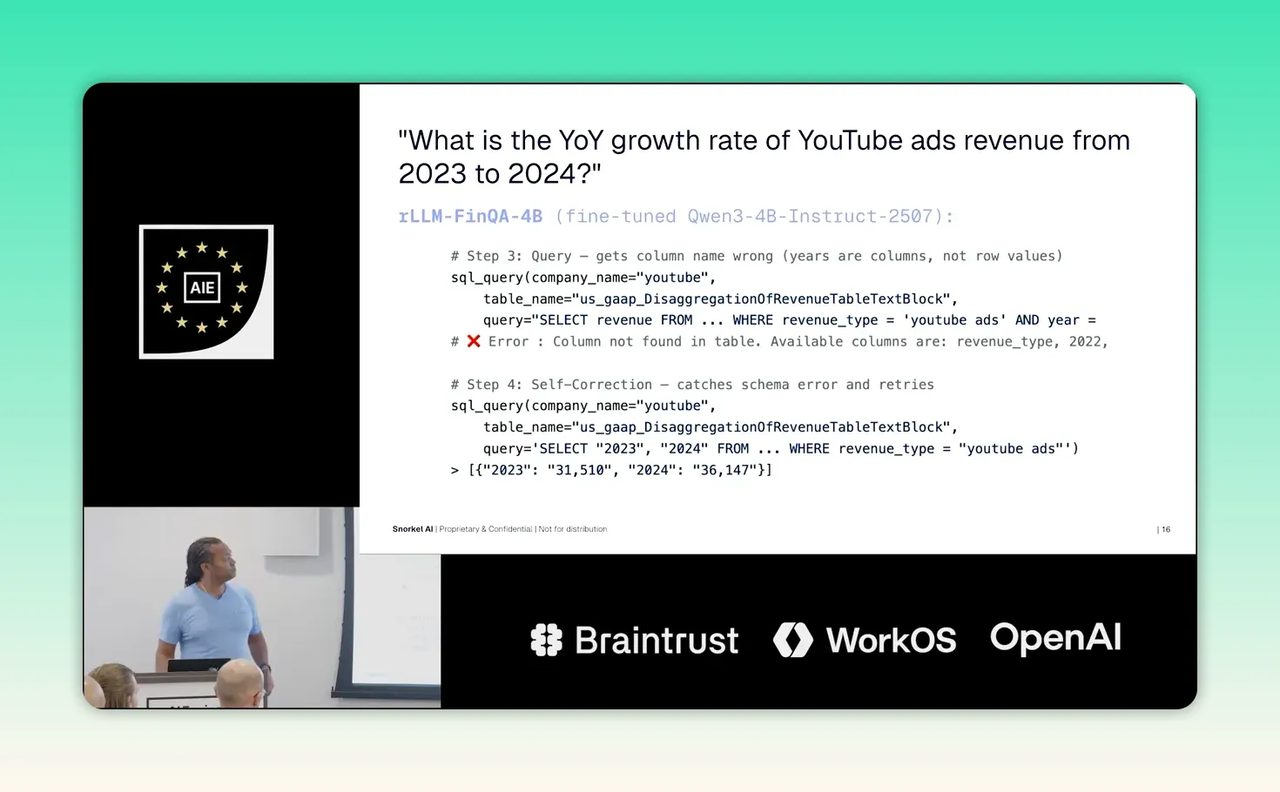
ตัวอย่างที่ใช้ในงานนี้ชัดมาก คำถามคืออัตราการเติบโตแบบปีต่อปีของรายได้โฆษณา YouTube ระหว่างปี 2023 กับ 2024 ฟังดูเหมือนงานที่ model ใหญ่ควรทำได้สบาย แต่สิ่งที่เกิดขึ้นกลับไม่เป็นแบบนั้น
model 235B เริ่มจากยิง SQL query ไปที่ตารางที่ไม่มีอยู่จริง พอไม่ได้ผลก็ลองใหม่แบบเดาสุ่มอีกครั้ง และเมื่อยังไม่ได้ข้อมูล มันก็จบด้วยการตอบออกมาเองแบบไม่มีหลักฐานรองรับ
จุดนี้สะท้อนปัญหาคลาสสิกของ AI ในงานองค์กร คือไม่ได้ล้มเหลวเพราะคิดเลขไม่ได้หรือไม่เข้าใจคำถาม แต่ล้มเหลวเพราะไม่สำรวจ environment ก่อนลงมือทำ
ถ้าแปลงเป็นภาษาธุรกิจไทย มันเหมือนพนักงานที่รีบตอบลูกค้าทันทีโดยไม่เปิดไฟล์ ไม่เช็กระบบ และไม่ถามข้อมูลเพิ่มให้ครบ คำตอบอาจฟังดูมั่นใจ แต่ใช้งานจริงไม่ได้

นี่คือเหตุผลว่าทำไมคำว่า tool discipline จึงสำคัญกว่าที่หลายทีมคิด เพราะเมื่อ AI ต้องทำงานผ่านฐานข้อมูล ระบบภายใน หรือ API ความถูกต้องไม่ได้มาจาก reasoning เพียงอย่างเดียว แต่มาจากลำดับการใช้เครื่องมือด้วย
Step 3: สร้างข้อมูลฝึกที่ดีพอ ก่อนคิดเรื่องเทรนเพิ่ม
อีกประเด็นที่งานนี้ย้ำแรงมากคือ ถ้าจะเทรนให้ model ดีขึ้น สิ่งแรกที่ต้องทำไม่ใช่รีบเทรน แต่ต้องสร้าง dataset ที่ดีพอเสียก่อน
Snorkel ใช้วิธีดึงผู้เชี่ยวชาญเข้ามาอยู่ใน loop ของการสร้างข้อมูล โดยเฉพาะคนที่เข้าใจงานการเงินจริง ทั้งฝั่งวิชาการและฝั่งอุตสาหกรรม แล้วค่อยตรวจสอบว่างานที่ให้ model ฝึกนั้นเป็นโจทย์ที่ตอบได้จริง มีคำตอบตรวจสอบได้จริง และสอดคล้องกับงานปลายทางจริง
ตรงนี้เป็นจุดที่หลายองค์กรไทยมักพลาด เพราะเวลาอยากใช้ AI เรามักรีบเก็บข้อมูลให้ได้เยอะที่สุด แต่ไม่ได้ถามว่าข้อมูลชุดนั้น “สอนพฤติกรรมที่อยากได้” หรือเปล่า
ตัวอย่างเช่น ถ้าเราอยากให้ AI ช่วยทีมบัญชี สิ่งที่ต้องฝึกอาจไม่ใช่แค่ความรู้บัญชี แต่คือ
- รู้ว่าต้องเปิดเอกสารไหนก่อน
- รู้ว่าต้องตรวจเลขจากช่องใด
- รู้ว่าเมื่อเจอข้อมูลไม่ครบต้องถามกลับ
- รู้ว่าเมื่อระบบตอบ error ต้องลองแบบไหนต่อ
นี่คือความต่างระหว่าง “สอนเนื้อหา” กับ “สอนนิสัยการทำงาน” และงานนี้กำลังย้ำว่าหลายเคสอย่างหลังสำคัญกว่า
Step 4: ใช้ RL เพื่อฝึกพฤติกรรมเฉพาะ ไม่ใช่ยัดความรู้ทุกอย่างลงไป
แนวทางที่ใช้คือ reinforcement learning หรือ RL โดยเริ่มจาก model ขนาด 4B แล้วฝึกให้ทำงานใน environment ที่ออกแบบมาสำหรับโจทย์การเงินแบบใช้ tools
จุดที่ควรสนใจมากคือ RL ในงานนี้ไม่ได้ถูกใช้เพื่อทำให้ model “รู้มากขึ้น” แต่ใช้เพื่อทำให้ model “เลือกพฤติกรรมที่ถูกต้องมากขึ้น” เช่น สำรวจเครื่องมือก่อน ใช้คำสั่งให้ตรงกับ schema และแก้ตัวเมื่อเจอ error
นี่เป็นกรอบคิดที่เอาไปใช้ในธุรกิจได้ทันที ถ้า AI ของเราพลาดซ้ำๆ ใน pattern เดิม เราควรถามก่อนว่าเป็นปัญหาเรื่อง knowledge gap หรือ behavior gap
ถ้าเป็น behavior gap การฝึกด้วยโจทย์ที่สะท้อนลำดับงานจริงมักคุ้มกว่าเปลี่ยน model ทั้งก้อน
อีกจุดที่น่าสนใจคือ ต้นทุนการเทรนหนึ่งรอบต่ำกว่า 500 ดอลลาร์ และใช้เวลาประมาณ 21 ชั่วโมง ตัวเลขนี้ทำให้เห็นว่าการปรับปรุง AI ให้เหมาะกับงานเฉพาะ ไม่จำเป็นต้องเป็นโปรเจกต์มหาศาลเสมอไป
สำหรับทีมธุรกิจ นี่แปลว่าเราไม่ควรมองการปรับ model เป็นเรื่องของ lab ใหญ่เท่านั้น แต่ควรมองเป็นการลงทุนเชิงเป้าหมาย ถ้ารู้ชัดว่าจะแก้พฤติกรรมอะไร
Step 5: ออกแบบ environment ให้ AI ทำงานในสนามจริงย่อส่วน
งานนี้สร้าง environment ชื่อ FinQA สำหรับทดสอบงานวิเคราะห์การเงินที่ต้องใช้ tools โดยเป็น environment แบบ self-contained ไม่มี dependency ภายนอก ทำให้ควบคุมการทดลองได้ง่ายและเหมาะกับงานที่กังวลเรื่องข้อมูล
ภายในมีชุดเครื่องมือที่ model ใช้ได้ เช่น การดูชื่อตาราง การดู schema และการคิวรีข้อมูล และยังมี benchmark สองระดับ ได้แก่โจทย์แบบตารางเดียว และโจทย์ยากขึ้นที่ต้องดึงข้อมูลข้ามหลายตาราง
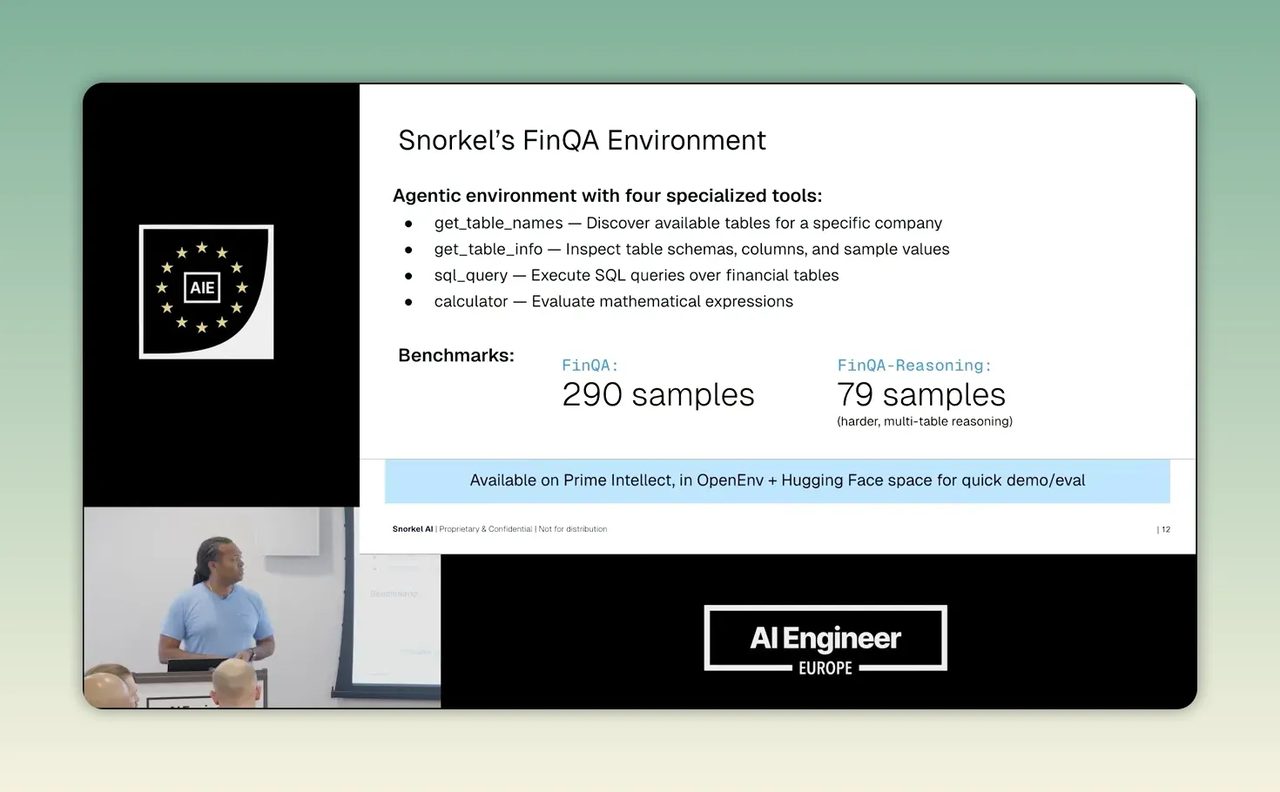
ถ้ามองในเชิงธุรกิจไทย หลักคิดนี้แปลได้ว่า ก่อนจะปล่อย AI ไปแตะระบบจริง เราควรทำ sandbox ของงานนั้นขึ้นมาก่อน เป็นสภาพแวดล้อมที่มีข้อมูลจำลอง ชุดเครื่องมือจำลอง และเกณฑ์วัดชัดเจน
เพราะถ้าเราไม่มีสนามซ้อม เราจะไม่รู้เลยว่า AI พลาดเพราะอะไร และยิ่งแก้ยากเมื่อระบบจริงมีหลายชั้น ทั้ง ERP, CRM, Excel, เอกสาร PDF, หรือฐานข้อมูลหลายชุด
แนวคิดเรื่อง environment ที่ดีใกล้เคียงกับแนวทางประเมินระบบ AI แบบมีงานจริงรองรับ ซึ่งองค์กรที่เริ่มทำเรื่องนี้จริงจังมักอ้างอิงหลักจากแหล่งอย่าง Hugging Face หรือแนวทางประเมิน model จากชุมชนวิจัยกว้างขึ้น
Step 6: วัดผลที่ปลายทาง แล้วกลับมาดูว่าพฤติกรรมไหนเปลี่ยน
ผลลัพธ์สำคัญของงานนี้คือ model 4B ที่ผ่านการฝึกด้วย RL ทำคะแนนดีกว่า model 235B ในงาน tool use สำหรับการเงิน โดยคะแนนผ่านโจทย์เพิ่มขึ้นแบบมีนัยสำคัญ และขึ้นไปแซง model ใหญ่ได้

แต่สิ่งที่สำคัญกว่าตัวเลขคือเหตุผลเบื้องหลัง ความเก่งที่เพิ่มขึ้นไม่ได้มาจาก model ฉลาดขึ้นแบบครอบจักรวาล แต่มาจากการเรียนรู้พฤติกรรมที่สำคัญต่อโจทย์นี้โดยตรง
model 4B ที่ผ่านการฝึกแล้วทำงานเป็นลำดับดังนี้
- เริ่มจากดูว่ามีตารางอะไรให้ใช้บ้าง
- จากนั้นดู schema ของตาราง
- ค่อยเขียน query ที่เหมาะสม
- เมื่อเจอ error เรื่องชื่อคอลัมน์ ก็ปรับคำสั่งใหม่
- สุดท้ายจึงสรุปคำตอบจากข้อมูลจริง
นี่คือพฤติกรรมของคนทำงานที่ดีมากกว่าพฤติกรรมของ model ที่เดาสุ่ม และมันบอกเราว่าในงาน AI สำหรับองค์กร การสอนลำดับวิธีทำงานอาจให้ผลมากกว่าการเพิ่มสมอง
Step 7: สนใจผลข้างเคียงที่ดี คือฝึกง่าย แต่ส่งผลไปงานยากได้
หนึ่งในผลลัพธ์ที่น่าแปลกใจของงานนี้คือ การฝึกด้วยโจทย์แบบตารางเดียวอย่างเดียว กลับให้ผลดีที่สุด แถมยังส่งผลดีไปถึงโจทย์ยากที่ต้องใช้หลายตารางด้วย
นี่เป็นข้อสังเกตที่น่าสนใจมาก เพราะหลายทีมชอบคิดว่า ถ้างานปลายทางซับซ้อน ข้อมูลฝึกต้องซับซ้อนตามให้มากที่สุด แต่ในความเป็นจริง ถ้า failure mode หลักอยู่ที่เรื่องพื้นฐาน เช่น ไม่สำรวจ tools ไม่อ่าน schema ไม่แก้ error การแก้รากของปัญหาอาจทำให้ performance ดีขึ้นทั่วระบบ
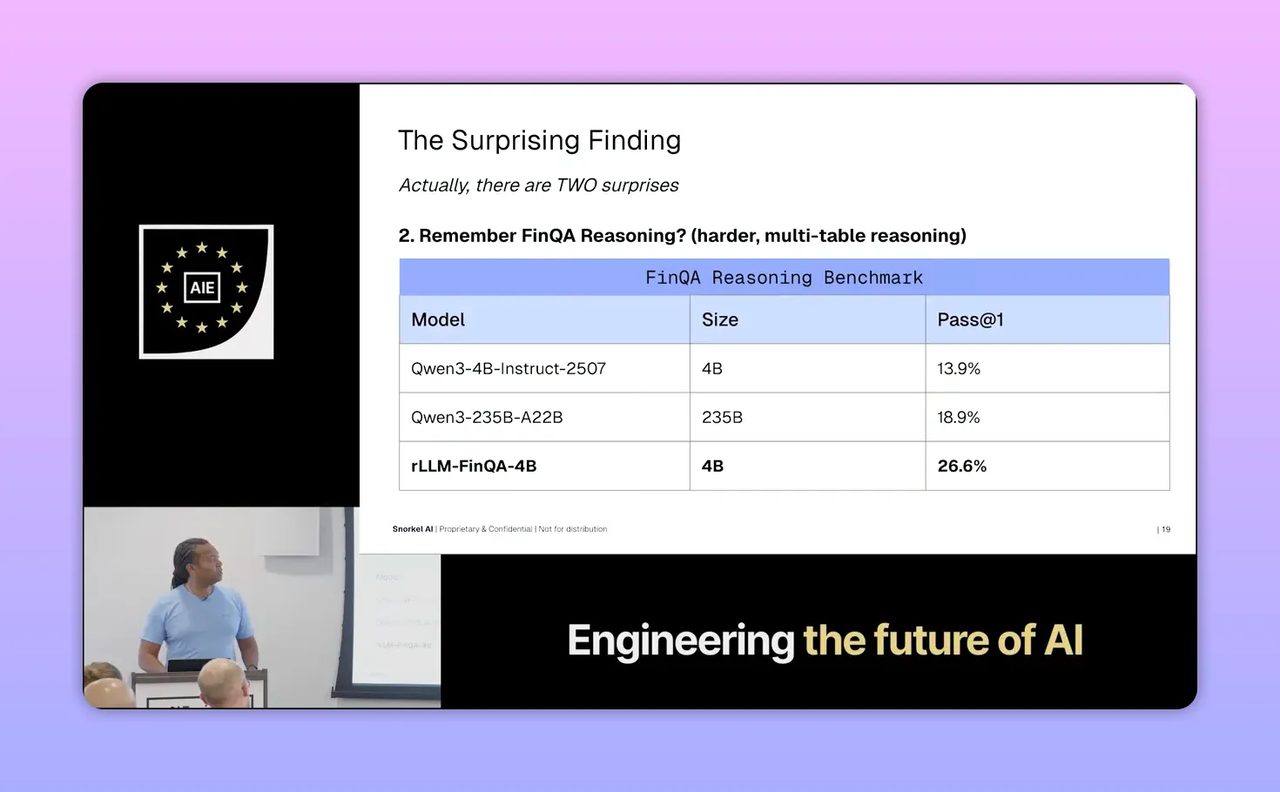
มุมนี้เอาไปใช้กับธุรกิจได้ชัดมาก เช่น ถ้าเรากำลังสร้าง AI assistant ให้ทีมขาย เราอาจไม่ต้องเริ่มจากทุกเคสซับซ้อนทันที แต่อาจเริ่มฝึกแค่ให้มันเปิดข้อมูลลูกค้า เช็กประวัติคำสั่งซื้อ และหยิบข้อมูลจากฟิลด์ที่ถูกก่อน ถ้าพฤติกรรมพื้นฐานแน่น การต่อยอดไปสู่เคสยากมักง่ายขึ้น
Step 8: ใช้ rubric แยกให้ได้ว่า model พลาดตรงไหน
อีกประเด็นที่มีค่ามากสำหรับคนทำระบบคือเรื่องการประเมินผล งานนี้เสนอว่าการวัดแบบตอบถูกหรือผิดอย่างเดียวไม่พอ เพราะมันบอกไม่ได้ว่า model พลาดตรงไหนกันแน่
วิธีที่ควรทำคือสร้าง rubric หรือเกณฑ์ย่อยแยกเป็นหลายคำถาม เช่น
- เลือก tool ถูกไหม
- สำรวจ environment ก่อนหรือไม่
- schema ที่ใช้ตรงหรือเปล่า
- อ่าน error แล้วแก้ถูกทางไหม
- คำตอบสุดท้ายมีข้อมูลรองรับจริงหรือไม่
เมื่อเรามี rubric เราจะเลิกมองว่า AI “เก่งหรือไม่เก่ง” แบบกว้างๆ แล้วเริ่มเห็นว่ามันพลาดที่จุดไหนอย่างเป็นระบบ ซึ่งสำคัญมากต่อการตัดสินใจว่าจะเก็บข้อมูลเพิ่มแบบไหน หรือจะเทรนเพื่อแก้อะไร
แนวคิดนี้สอดคล้องกับทิศทางการประเมินระบบ AI ที่องค์กรระดับโลกให้ความสำคัญมากขึ้น เช่นแนวทางเกี่ยวกับ evaluation และ trustworthy AI จาก NIST AI Risk Management Framework
Step 9: แปลบทเรียนนี้เป็นภาพธุรกิจไทยให้ชัด
ถ้าจะสรุปเป็นภาษาของเจ้าของธุรกิจไทย งานนี้กำลังบอกว่าเราไม่ควรถามแค่ว่า “จะใช้ model ไหน” แต่ควรถามเพิ่มว่า
- งานนี้ต้องใช้เครื่องมืออะไรบ้าง
- AI ต้องมีลำดับการทำงานแบบไหน
- มันพลาดตรงขั้นตอนไหนบ่อยที่สุด
- ข้อมูลฝึกของเราสอนพฤติกรรมนั้นหรือยัง
- มี benchmark ที่สะท้อนงานจริงหรือยัง
ตัวอย่างการใช้งานในธุรกิจไทยที่เห็นภาพได้ทันที ได้แก่
- ฝ่ายการเงิน ให้ AI ดึงข้อมูลจากหลายชีตแล้วคำนวณตัวเลข แต่ต้องฝึกให้เช็กชื่อชีตและหัวคอลัมน์ก่อน
- ฝ่ายบริการลูกค้า ให้ AI ตอบจากฐานความรู้ภายใน แต่ต้องฝึกให้ค้นเอกสารก่อนตอบ ไม่เดา
- ฝ่ายขาย ให้ AI สรุปลูกค้าจาก CRM แต่ต้องฝึกให้ตรวจประวัติล่าสุดก่อนเสนอ next action
- ฝ่ายปฏิบัติการ ให้ AI สั่งงานผ่านระบบหลายตัว แต่ต้องฝึกให้ตรวจสถานะแต่ละระบบก่อนข้ามไปขั้นตอนถัดไป
พูดอีกแบบคือ งาน AI ที่ใช้ได้จริงในองค์กร ไม่ได้ชนะกันที่ IQ ของ model อย่างเดียว แต่ชนะกันที่ discipline ของ workflow
Actionable Insights
- เริ่มจากหาว่า AI พลาดเพราะไม่รู้ หรือพลาดเพราะลำดับการทำงานผิด
- ถ้างานต้องใช้ฐานข้อมูลหรือระบบภายใน ให้สร้าง sandbox ทดสอบก่อนปล่อยใช้งานจริง
- เก็บตัวอย่างงานที่ดีจากคนทำงานเก่งๆ เพื่อสอน behavior ไม่ใช่เก็บแค่คำตอบสุดท้าย
- ทำ rubric ประเมินงานเป็นขั้นตอน เช่น ค้นข้อมูลถูกไหม ใช้ tool ถูกไหม แก้ error ได้ไหม
- ก่อนอัปเกรดไป model แพงขึ้น ลองแก้ failure mode หลักด้วยข้อมูลและการฝึกเฉพาะทางก่อน
Troubleshooting
- ปัญหา: AI ตอบมั่นใจ แต่คำตอบผิด
สาเหตุ: model ไม่ได้ใช้ tool หรือข้อมูลจริงก่อนตอบ
วิธีแก้: บังคับ workflow ให้ค้นข้อมูลก่อนตอบ และเพิ่มการประเมินว่าคำตอบทุกข้อมีหลักฐานรองรับหรือไม่ - ปัญหา: ต่อฐานข้อมูลแล้ว แต่ AI query ผิดบ่อย
สาเหตุ: ไม่ได้ฝึกให้สำรวจชื่อตารางและ schema ก่อน
วิธีแก้: เพิ่มโจทย์ฝึกที่ให้ model เรียกดู table names และ schema เป็นขั้นตอนบังคับ - ปัญหา: เจอ error แล้ว workflow พัง
สาเหตุ: model ไม่ได้เรียนรู้การ self-correct
วิธีแก้: สร้างตัวอย่างที่มี error จริง และให้รางวัลกับการแก้คำสั่งรอบถัดไปให้ถูก - ปัญหา: ใช้ model ใหญ่แล้วต้นทุนสูงเกินไป
สาเหตุ: เลือกแก้ปัญหาด้วยขนาด model แทนการแก้พฤติกรรม
วิธีแก้: หา failure mode หลักก่อน ถ้าปัญหาอยู่ที่ tool use ให้ลองเทรน model เล็กกับงานเฉพาะ - ปัญหา: ประเมินแล้วรู้แค่ว่าผิด แต่ไม่รู้ว่าผิดตรงไหน
สาเหตุ: วัดผลแบบผ่านหรือไม่ผ่านอย่างเดียว
วิธีแก้: แตกเกณฑ์ประเมินเป็น rubric ย่อย เพื่อให้เห็นจุดที่ต้องแก้จริง
การต่อยอด
- สร้าง AI pilot สำหรับทีมการเงินหรือทีมแอดมิน โดยเริ่มจากงานที่ใช้ตารางเดียวก่อน แล้วค่อยขยายไปงานหลายระบบ
- ทำ internal benchmark ขององค์กรเอง เช่น 50 คำถามที่สะท้อนงานจริง แล้ววัดพฤติกรรมการใช้ tools อย่างต่อเนื่อง
- เก็บ playbook ของพนักงานที่ทำงานเก่ง แล้วแปลงเป็นชุดตัวอย่างสำหรับฝึก AI ใน workflow เฉพาะของบริษัท
สรุป Checklist ทั้งหมด
- ☐ ระบุให้ได้ก่อนว่าโจทย์นี้ต้องการความฉลาดเพิ่ม หรือแค่ต้องการพฤติกรรมที่ดีขึ้น
- ☐ หา failure mode หลักของ AI จากงานจริง
- ☐ สร้าง rubric เพื่อแยกจุดพลาดเป็นขั้นตอนย่อย
- ☐ เก็บข้อมูลฝึกจากผู้เชี่ยวชาญหรือคนที่ทำงานจริงเก่ง
- ☐ ออกแบบ environment หรือ sandbox สำหรับงานนั้น
- ☐ ฝึกให้ AI มี tool discipline เช่น เช็กตาราง ดู schema และแก้ error
- ☐ ทดสอบด้วย benchmark ที่สะท้อนงานจริงขององค์กร
- ☐ เปรียบเทียบต้นทุนกับผลลัพธ์ ก่อนตัดสินใจขยับไป model ใหญ่ขึ้น
- ☐ เริ่มจากงานง่ายที่ชี้พฤติกรรมหลักให้ชัด แล้วค่อยขยายไปงานยาก
- ☐ วัดผลต่อเนื่องว่าความแม่นดีขึ้นเพราะ behavior ดีขึ้นจริงหรือไม่
สรุปสุดท้ายจากคลิปนี้ชัดมากว่า Stop Making Models Bigger ไม่ได้แปลว่าห้ามใช้ model ใหญ่ แต่แปลว่าอย่าใช้ขนาด model เป็นคำตอบแรกของทุกปัญหา ถ้างานของเราต้องอาศัย tools, database, เอกสาร และ workflow จริงในองค์กร สิ่งที่ควรทำก่อนคือสอนให้ AI ทำงานให้เป็น
สำหรับเจ้าของธุรกิจและคนทำงาน นี่คือบทเรียนที่คุ้มมาก เพราะมันเปลี่ยนวิธีคิดจากการ “ซื้อความฉลาดเพิ่ม” ไปสู่การ “ออกแบบพฤติกรรมให้ถูกงาน” และนั่นมักเป็นจุดที่ทำให้ AI เริ่มใช้ได้จริงในองค์กร