ในยุคที่ AI กำลังเข้ามามีบทบาทในทุกวงการ การพัฒนาและประเมินผล AI Agents กลายเป็นหัวข้อที่ได้รับความสนใจอย่างมาก แต่ในความเป็นจริง AI Agents ที่เรามีอยู่ตอนนี้ยังไม่สามารถทำงานได้อย่างเต็มประสิทธิภาพตามที่หลายคนคาดหวังไว้ จากการวิเคราะห์ของ Sayash Kapoor นักวิจัยและ AI Engineer ที่มีชื่อเสียง
บทความนี้จะพาไปสำรวจปัญหาของ AI Agents ในปัจจุบัน พร้อมแนวทางและข้อคิดสำหรับการพัฒนา AI Agents ให้มีความน่าเชื่อถือและใช้งานได้จริงในโลกจริง
ทำไม AI Agents ถึงเป็นที่พูดถึงมากในตอนนี้?
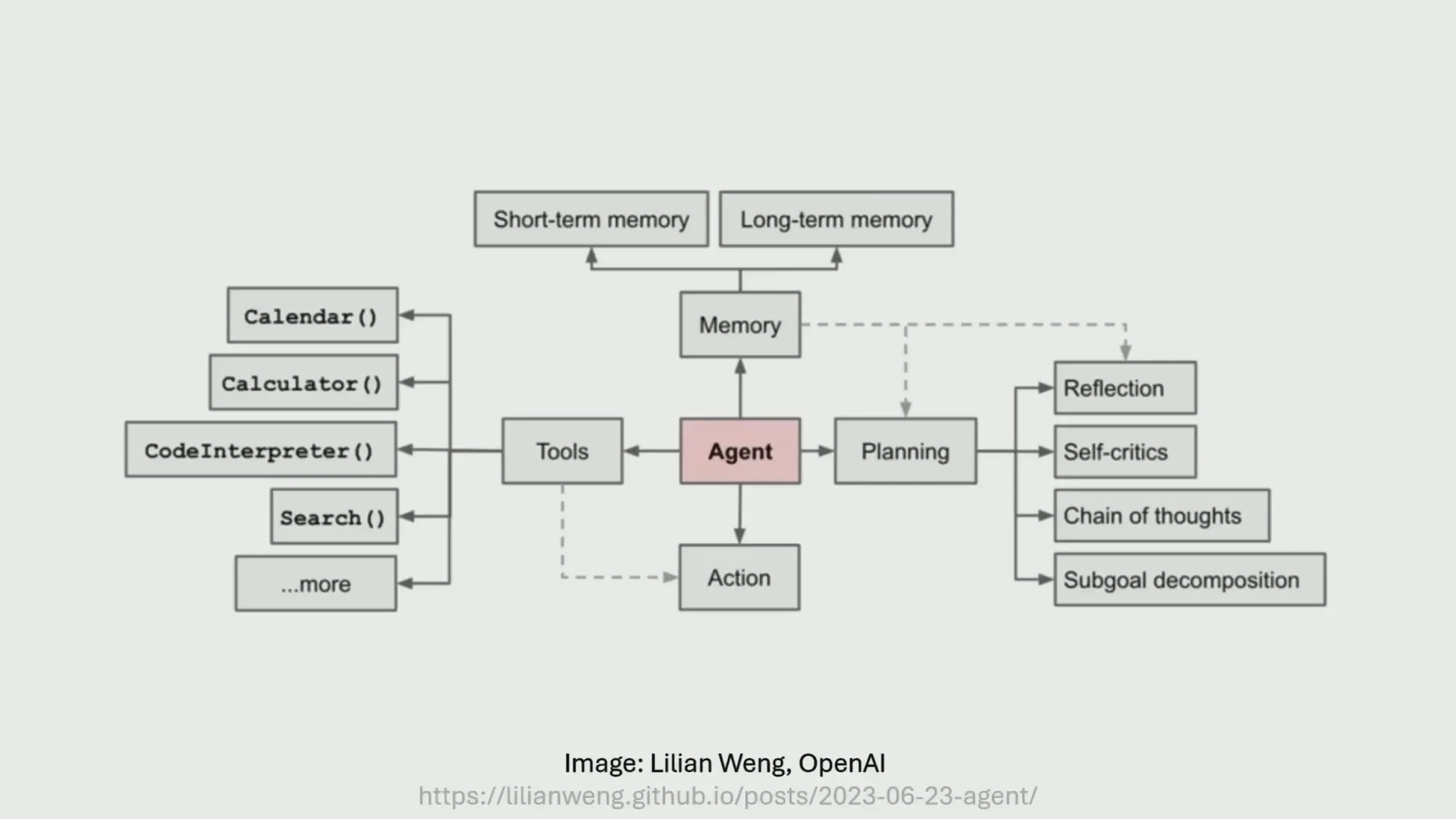
AI Agents คือระบบที่ใช้โมเดลภาษา (Language Models) เป็นหัวใจในการควบคุมและดำเนินงานในระบบต่าง ๆ โดยสามารถรับข้อมูลเข้าและส่งผลลัพธ์ออก รวมถึงเรียกใช้เครื่องมืออื่น ๆ เพื่อแก้ไขปัญหา ตัวอย่างเช่น ChatGPT ที่หลายคนรู้จักก็ถือเป็น AI Agents ในระดับพื้นฐาน เพราะมีการกรองข้อมูลเข้าออกและสามารถทำงานบางอย่างได้โดยอัตโนมัติ
ในปัจจุบัน มี AI Agents ที่สามารถทำงานที่ซับซ้อนขึ้น เช่น OpenAI Operator ที่สามารถทำงานบนอินเทอร์เน็ตแบบเปิดกว้าง หรือ Deep Research Tool ที่สามารถเขียนรายงานเชิงลึกในเวลานานถึง 30 นาทีได้ แต่ถึงอย่างนั้น วิสัยทัศน์ที่ใหญ่กว่า เช่น การสร้าง AI Agents ที่เหมือนในภาพยนตร์ไซไฟ ยังห่างไกลจากความเป็นจริงมาก
ปัญหาหลักที่ทำให้ AI Agents ยังไม่ทำงานได้ดี
จากประสบการณ์และงานวิจัยของ Sayash Kapoor มี 3 ปัจจัยหลักที่ทำให้ AI Agents ไม่สามารถทำงานได้ดีในโลกจริง
1. การประเมินผล AI Agents เป็นเรื่องยากมาก
การวัดประสิทธิภาพของ AI Agents ไม่ใช่เรื่องง่าย เพราะการทำงานของ AI Agents มักซับซ้อนและเปิดกว้างกว่าการประเมินโมเดลภาษาเพียงอย่างเดียว ตัวอย่างเช่น สตาร์ทอัพ "Do Not Pay" ที่ประกาศว่าจะช่วยทนายความทำงานได้ทั้งหมด แต่สุดท้ายถูกปรับจาก FTC เนื่องจากการอ้างสิทธิ์ที่ไม่เป็นความจริง
ในโลกจริง การใช้งาน AI Agents เพื่อการตัดสินใจที่สำคัญ ความน่าเชื่อถือจึงมีความสำคัญมากกว่าความสามารถที่เกิดขึ้นเป็นบางครั้ง เพราะถ้า AI Agents ทำงานผิดพลาดบ่อยครั้ง ผลลัพธ์จะส่งผลเสียต่อผู้ใช้โดยตรง
ตัวอย่างเช่น ถ้า AI Agents ที่ทำหน้าที่เป็นผู้ช่วยส่วนตัวสั่งอาหารผิดพลาด 20% ของคำสั่ง นั่นถือเป็นความล้มเหลวอย่างร้ายแรงสำหรับผลิตภัณฑ์
แม้วิธีการเพิ่มความน่าเชื่อถือ เช่น การสร้าง verifier หรือ unit test เพื่อทดสอบคำตอบจะช่วยได้บางส่วน แต่ในทางปฏิบัติ verifier เองก็มีข้อจำกัด เช่น บางครั้งโค้ดที่ผิดอาจผ่าน unit test ได้ ทำให้ประสิทธิภาพของโมเดลดูดีเกินความจริง
แนวทางแก้ไขและการเปลี่ยนแปลงแนวคิดสำหรับ AI Engineering
การแก้ไขปัญหา AI Agents ที่ไม่เสถียรและประเมินผลได้ยาก จำเป็นต้องเปลี่ยนมุมมองและวิธีการทำงานของวิศวกร AI โดยเน้นไปที่การออกแบบระบบที่รองรับความไม่แน่นอนของโมเดลภาษา (stochastic models) มากกว่าการมุ่งเน้นที่การสร้างโมเดลเพียงอย่างเดียว
Cost (ค่าใช้จ่าย): ค่าใช้จ่ายในการรัน AI Agents ซึ่งรวมถึงการใช้พลังงานและทรัพยากรคอมพิวเตอร์
บทสรุปจาก Insiderly
การพัฒนา AI Agents ที่ใช้งานได้จริงในโลกปัจจุบันยังคงเผชิญกับอุปสรรคที่ซับซ้อนทั้งในการประเมินผล การสร้างความน่าเชื่อถือ และการจัดการต้นทุน ความเข้าใจที่ชัดเจนว่าความสามารถและความน่าเชื่อถือไม่ใช่สิ่งเดียวกันเป็นสิ่งสำคัญมากสำหรับวิศวกร AI ในยุคนี้
อีกทั้งการเปลี่ยนมุมมองจากการเป็นนักพัฒนาโมเดลไปสู่การเป็นวิศวกรความน่าเชื่อถือ (reliability engineer) จะช่วยสร้างระบบ AI Agents ที่พร้อมใช้งานและตอบโจทย์ความต้องการของผู้ใช้จริง การนำแนวทางนี้ไปใช้จะช่วยหลีกเลี่ยงความล้มเหลวซ้ำ ๆ ที่เกิดขึ้นกับผลิตภัณฑ์ AI Agent หลายตัวในอดีต
สุดท้าย AI Agents จะไม่ใช่แค่เทคโนโลยีที่น่าตื่นเต้น แต่จะกลายเป็นเครื่องมือสำคัญที่ช่วยขับเคลื่อนนวัตกรรมและเปลี่ยนแปลงโลกได้อย่างแท้จริงก็ต่อเมื่อเราสามารถสร้างความน่าเชื่อถือและประสิทธิภาพที่เหมาะสมได้อย่างแท้จริง
สำรวจการเดินทางของ OpenAI จากความฝันสู่ความจริงกับ Sam Altman พร้อมบทเรียนการสร้างทีม AI ชั้นนำและเทคโนโลยีล้ำสมัยอย่าง ChatGPT และฟีเจอร์ Memory ที่เปลี่ยนแปลงโลก AI ไปตลอดกาล
เจาะลึกเรื่องราวของ Alexandr Wang ซีอีโอ Scale AI การเปลี่ยนแปลงงานด้วย Agents และการแข่งขัน AI ระหว่างสหรัฐฯ กับจีน พร้อมวิเคราะห์เทคโนโลยีและโมเดล AI ที่กำลังพลิกโฉมธุรกิจทั่วโลก
สรุปและวิเคราะห์งาน Microsoft Build 2025 กับการเปิดตัว AI Agents, GitHub Copilot รุ่นใหม่, Azure AI Foundry และ Microsoft Discovery ที่จะเปลี่ยนโลกเทคโนโลยีและวิทยาศาสตร์