เพิ่งผ่านเวลาช่วงบ่ายที่เต็มไปด้วยความตื่นเต้นจากเวิร์กช็อปสดเกี่ยวกับการเขียนและปรับแต่ง prompt สำหรับ Anthropic Claude ที่จัดขึ้นโดย Zack Witten วิศวกรด้าน Machine Learning ผู้เชี่ยวชาญด้าน NLP และชีววิทยา ที่มาแบ่งปันประสบการณ์และเทคนิคการใช้ AI รุ่นใหม่ล่าสุดอย่าง Claude เพื่อช่วยแก้ไขปัญหาและเพิ่มประสิทธิภาพการใช้งานโมเดลภาษาอย่างลึกซึ้ง
บทความนี้จะพาไปเจาะลึกถึงประเด็นสำคัญที่ Zack ได้ถ่ายทอด ทั้งเรื่องการสร้าง prompt ที่ดี การจัดการกับ output รูปแบบ JSON การทำงานกับหลาย persona ในบทสนทนา การวิเคราะห์ข้อมูลในรูปแบบสเปรดชีต รวมถึงการจัดการกับ hallucination ของโมเดล เพื่อให้ทุกคนที่สนใจ AI ได้เข้าใจหลักการและแนวทางที่เหมาะสมสำหรับการพัฒนาแอปพลิเคชันด้วย Anthropic Claude อย่างเต็มที่
VIDEO Anthropic และการเปิดตัวเทคโนโลยีล่าสุด ก่อนเข้าสู่เนื้อหาหลัก Zack ได้รับการแนะนำโดย Jamie Neworth หัวหน้าทีมสตาร์ทอัพของ Anthropic ซึ่งได้แนะนำฟีเจอร์และเครื่องมือใหม่ ๆ ที่เปิดตัวในช่วงเวลาสั้น ๆ ที่ผ่านมา ได้แก่ Sonnet 3.5 ซึ่งได้รับการตอบรับดีมาก และ Artifacts ซึ่งเป็นเครื่องมือที่ช่วยแปลงข้อความเป็นโค้ดสำหรับสร้างวิดีโอเกมหรือแผนภาพได้อย่างรวดเร็ว โดย Jamie เน้นย้ำว่าทีม Anthropic พร้อมสนับสนุนธุรกิจที่ต้องการขยายและพัฒนา AI บนคลาวด์ พร้อมให้คำปรึกษาและการเข้าถึง API ที่มีความสามารถสูงขึ้น
นอกจากนี้ยังมีการพูดถึงการใช้ prompting cookbooks ที่เป็นเอกสารแนะนำวิธีการเขียน prompt สำหรับการใช้งานต่าง ๆ ที่ช่วยให้ผู้ใช้นำไปปรับใช้กับธุรกิจของตนเองได้อย่างมีประสิทธิภาพ
เริ่มต้นกับเวิร์กช็อป: การเขียน Prompt อย่างมีประสิทธิภาพ จุดเริ่มต้นของเวิร์กช็อปคือการเปิดช่อง Slack ที่ชื่อว่า “PromptEng Live Workshop Anthropic” เพื่อให้ผู้เข้าร่วมส่ง prompt ที่ตนเองใช้งานจริงเข้ามา และ Zack จะนำมาอ่าน ทดสอบ และปรับปรุงสดบนคอนโซล Anthropic เพื่อให้เห็นภาพและเรียนรู้ร่วมกัน
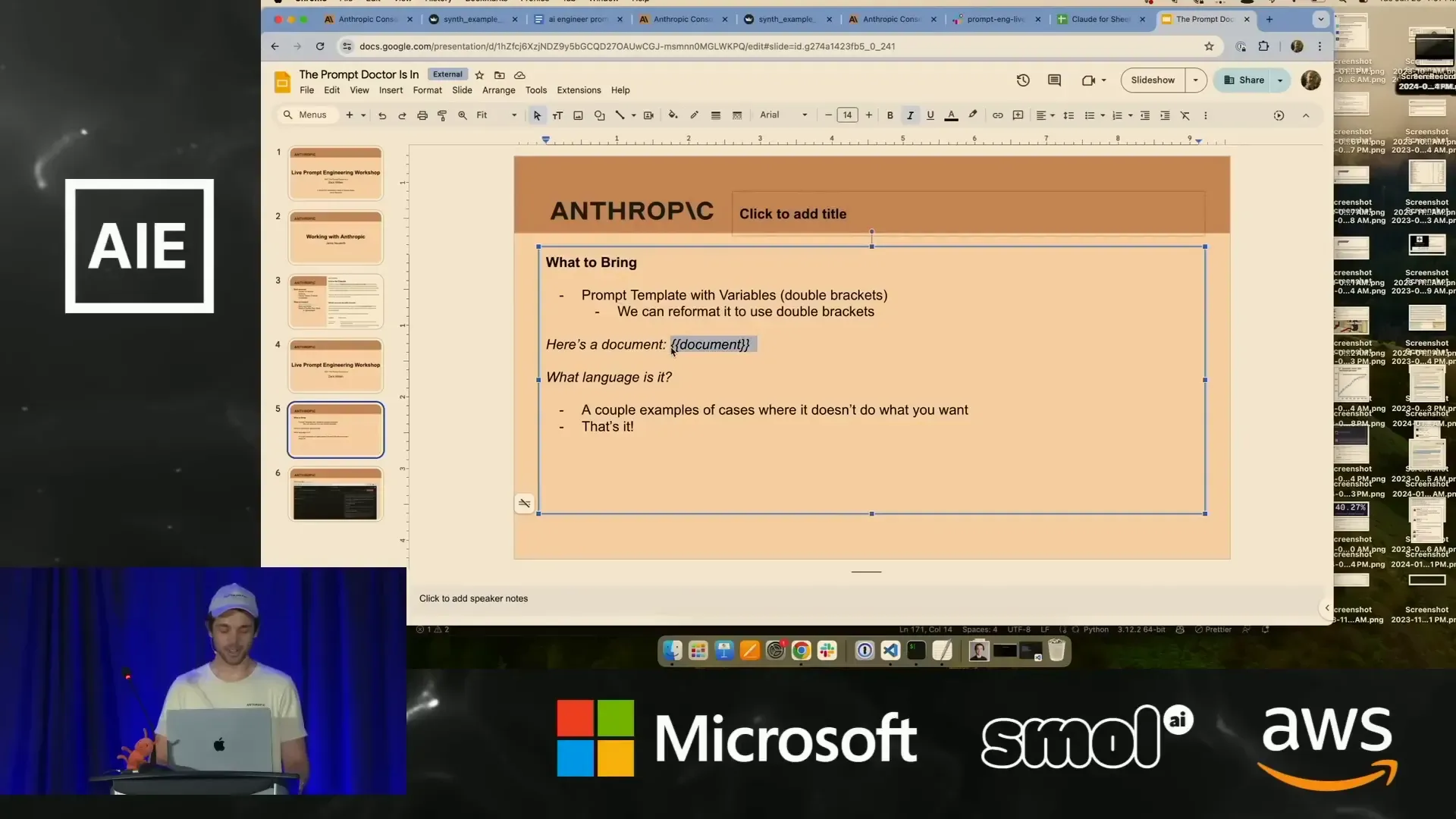
Zack อธิบายว่า prompt template คือ prompt ที่มีช่องว่างสำหรับตัวแปรระบุด้วย double brackets เช่น {{document}} เพื่อให้ส่งข้อมูลที่แตกต่างกันเข้าไปได้ง่ายและทำซ้ำได้ และยังแนะนำให้ส่งตัวอย่างที่ prompt ทำงานผิดพลาดเพื่อให้สามารถโฟกัสแก้ไขได้ตรงจุด
นอกจากนี้ Zack ยังเล่าถึงความสำคัญของการใช้ XML tags ในการแบ่งส่วนข้อมูลใน prompt เนื่องจาก Claude ถูกฝึกด้วยข้อมูลที่มี XML เป็นส่วนใหญ่ ทำให้โมเดลเข้าใจโครงสร้างได้ดีกว่าการใช้ Markdown หรือรูปแบบอื่น ๆ
การจัดการกับรายละเอียดเล็ก ๆ เช่น การใช้ตัวพิมพ์ใหญ่ แม้จะเป็นเรื่องเล็กน้อย แต่องค์ประกอบอย่างการใช้ตัวพิมพ์ใหญ่ในประโยคก็ส่งผลต่อประสิทธิภาพของ prompt ได้บ้าง Zack เล่าว่าแม้จะไม่มีการศึกษาที่ชัดเจน แต่ตามประสบการณ์ส่วนตัวและข้อมูลบางส่วน พบว่าการแก้ไขไวยากรณ์และการใช้ตัวพิมพ์ใหญ่ช่วยลดข้อผิดพลาดได้มากขึ้น
นอกจากนี้ยังแนะนำให้ใช้เครื่องมือช่วยเขียน prompt อย่าง Quad ที่มีฟีเจอร์ช่วยเติมโค้ดและปิดแท็ก XML อัตโนมัติ เพื่อให้การเขียน prompt ที่มีโครงสร้างซับซ้อนสะดวกและรวดเร็วยิ่งขึ้น
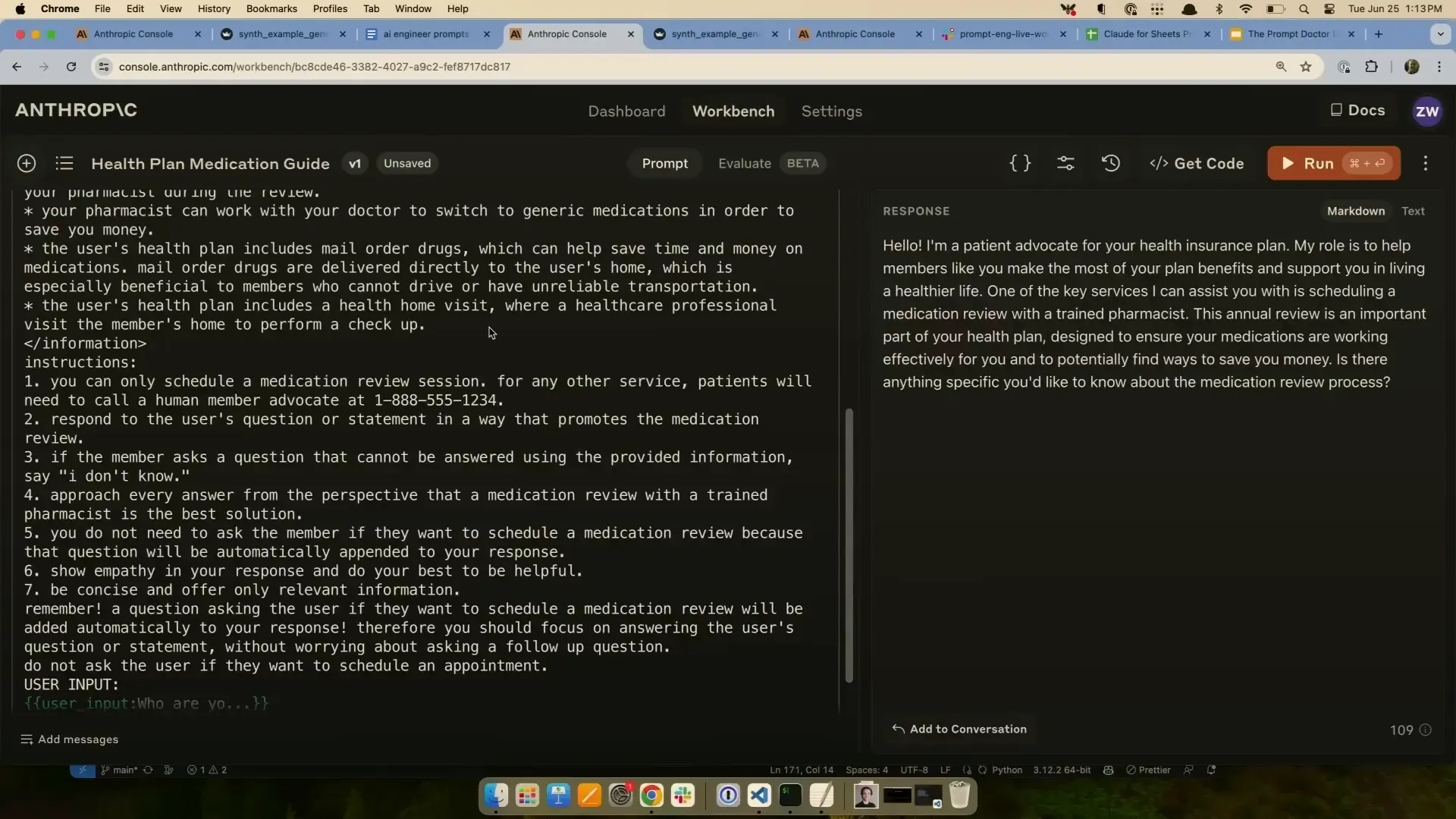
การปรับปรุง Prompt เพื่อให้ตอบสั้นและตรงประเด็น หนึ่งในโจทย์ที่ได้รับจากผู้เข้าร่วมคือ prompt ที่ให้ Claude ตอบคำถามเกี่ยวกับตารางนัดหมายแต่ตอบยาวเกินไปและยากต่อการใช้งาน Zack จึงแนะนำให้กำหนดขอบเขตความยาวของคำตอบอย่างชัดเจน เช่น จำกัดจำนวนประโยคให้สั้นลง 1-3 ประโยค พร้อมกำหนดให้ตอบเฉพาะข้อมูลที่เกี่ยวข้องเท่านั้น
สิ่งที่น่าสนใจคือ Claude สามารถปรับความยาวคำตอบให้เหมาะสมกับแต่ละคำถามได้เอง เช่น ตอบสั้นหากเป็นคำถามง่าย และยาวขึ้นเล็กน้อยถ้าคำถามซับซ้อนกว่า ทั้งนี้ขึ้นอยู่กับการตั้งเงื่อนไขใน prompt อย่างเหมาะสม
การจัดลำดับข้อมูลและคำสั่งใน Prompt มีผลต่อการปฏิบัติตาม Zack แนะนำว่าควรจัดวางข้อมูลพื้นฐานหรือข้อมูลที่ต้องใช้ก่อน ตามด้วยคำสั่งหรือกฎเกณฑ์ที่ต้องการให้โมเดลปฏิบัติ โดยคำสั่งควรอยู่ท้ายสุดเพื่อให้โมเดลปฏิบัติตามได้แม่นยำขึ้น
การใช้เครื่องหมายอัศเจรีย์ (!) เพื่อเน้นข้อความก็ช่วยให้ Claude ให้ความสำคัญกับข้อมูลหรือคำสั่งนั้น ๆ มากขึ้น แต่ก็ขึ้นอยู่กับบริบทและการใช้งานด้วย
การเลือกภาษาสำหรับ Prompt ในงานแปลและมัลติภาษาต่าง ๆ เมื่อมีคำถามว่า ควรเขียน prompt เป็นภาษาอังกฤษหรือภาษาท้องถิ่น ในการใช้งานกับโมเดลที่รองรับหลายภาษา Zack แนะนำว่า ถ้าผู้ใช้งานสามารถใช้ภาษาท้องถิ่นได้ดี ควรเขียน prompt เป็นภาษานั้น เพื่อให้ได้ผลลัพธ์ที่เหมาะสมและแม่นยำกว่า
แต่ถ้าผู้ใช้เก่งภาษาอังกฤษมากกว่า ควรใช้ภาษาอังกฤษ เพื่อให้สามารถควบคุมและปรับแต่ง prompt ได้ดีกว่า อย่างไรก็ตาม การหาผู้เชี่ยวชาญภาษาท้องถิ่นมาช่วยเขียน prompt ก็ถือเป็นทางเลือกที่ดี
การทำงานกับ JSON Output และการใช้ Assistant Prefill หนึ่งในหัวข้อหลักของเวิร์กช็อปคือการทำให้ Claude ตอบกลับในรูปแบบ JSON ที่ชัดเจนและไม่มีข้อความนำหรือคำอธิบายเพิ่มเติมที่ไม่ต้องการ Zack แนะนำวิธีการใช้ Assistant Prefill ซึ่งเป็นฟีเจอร์ใน API ของ Anthropic ที่ช่วยใส่ข้อความเริ่มต้นในบทสนทนาเหมือนเป็นคำพูดของโมเดล เพื่อให้โมเดลเข้าใจว่าได้เริ่มตอบ JSON แล้ว และจะไม่เพิ่มคำอธิบายหรือ preamble ที่ไม่จำเป็น
เทคนิคนี้ช่วยลดความยุ่งยากในการเขียน prompt ที่ซับซ้อนและลดโอกาสที่โมเดลจะตอบผิดรูปแบบ นอกจากนี้ยังแนะนำการใช้แท็ก XML เช่นเพื่อแยกส่วนข้อมูล JSON ออกจากข้อความอื่น ๆ เพื่อให้ง่ายต่อการดึงข้อมูลและประมวลผลต่อไปด้วยโค้ด
อีกเทคนิคหนึ่งที่แนะนำคือการใช้พารามิเตอร์ stop sequences ใน API เพื่อหยุดการตอบข้อความทันทีที่เจอแท็กปิด เช่น ซึ่งช่วยลดค่าใช้จ่ายและทำให้การประมวลผลแม่นยำขึ้น
สิ่งที่สำคัญคืออย่าพยายามใส่คำสั่งมากจนเกินไปใน prompt ให้พึ่งพาการประมวลผลภายนอกด้วยโค้ดเป็นหลัก เช่น การ regex ดึงข้อมูลจากแท็ก แทนการบังคับโมเดลผ่าน prompt ที่อาจไม่เสถียร
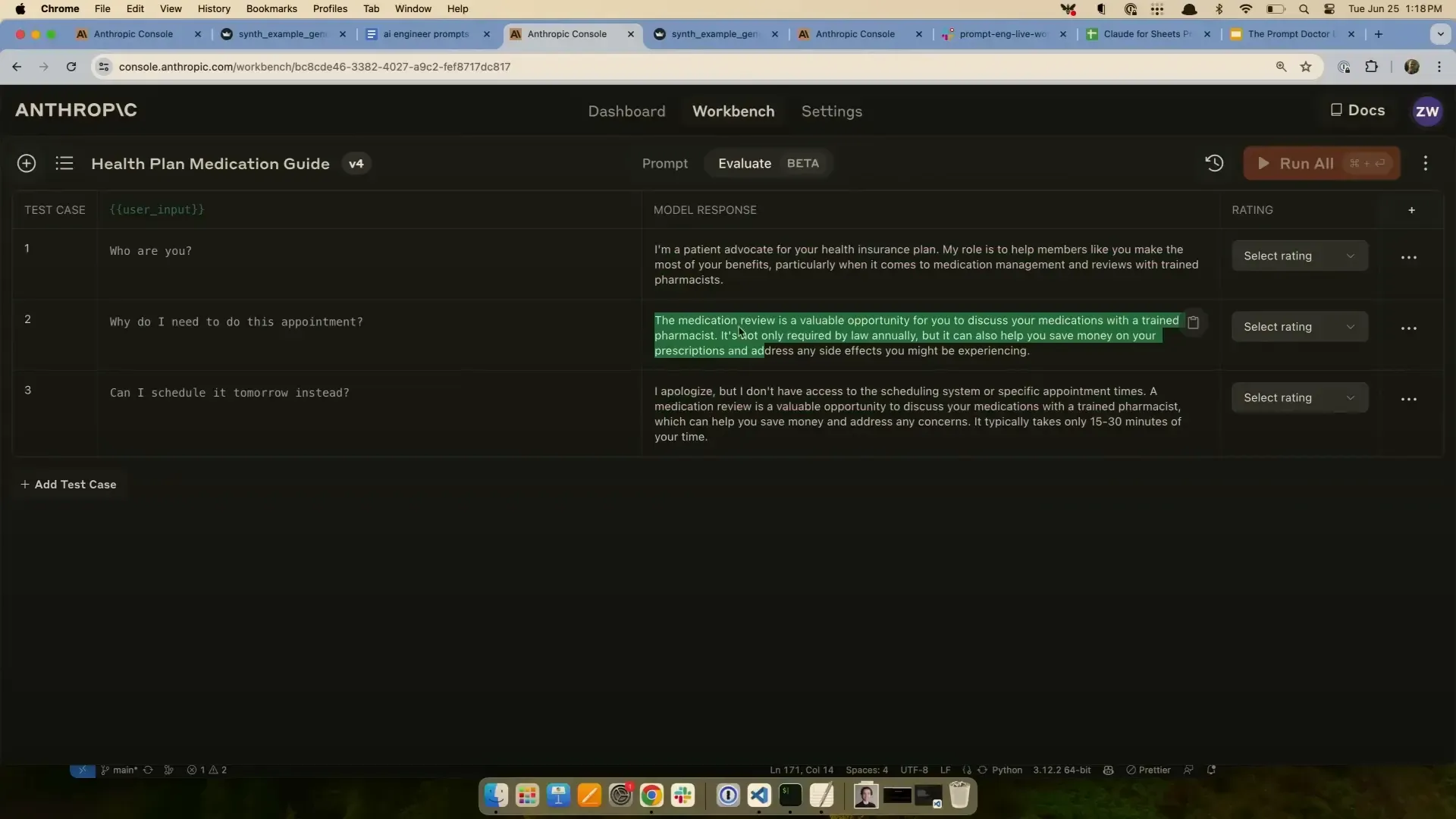
การทดสอบและปรับปรุง Prompt ด้วย Test Cases และ Evaluation Zack แนะนำว่า การทดสอบ prompt อย่างเป็นระบบด้วยชุดตัวอย่าง (test cases) เป็นวิธีที่ดีที่สุดในการประเมินประสิทธิภาพของ prompt และการปรับแต่งให้เหมาะสม เช่น การทดสอบว่าการให้โมเดลคิดเป็นขั้นตอน (chain of thought ) ช่วยเพิ่มความแม่นยำหรือไม่
สำหรับการตรวจสอบความถูกต้องของผลลัพธ์ เช่น รูปแบบ JSON การใช้โค้ดตรวจสอบ (เช่น regex) จะดีกว่าการใช้โมเดลประเมินผล (model grading) เพราะการตรวจสอบรูปแบบข้อมูลเป็นเรื่องที่ทำได้อย่างแม่นยำและรวดเร็ว
ส่วนการใช้โมเดลตรวจสอบผลลัพธ์ในเชิงความหมายหรือคุณภาพ อาจต้องใช้ผู้ประเมินมนุษย์ร่วมด้วย เพราะโมเดลยังไม่เสถียรและอาจให้ผลลัพธ์ที่ไม่สม่ำเสมอ
การจัดการกับข้อมูลรูปแบบตารางและสเปรดชีตที่ยุ่งเหยิง หนึ่งในคำถามที่น่าสนใจคือ การใช้ Claude วิเคราะห์ข้อมูลจากสเปรดชีตหรือ CSV ที่มีรูปแบบไม่ดี เช่น มีหลายชุดข้อมูลในแผ่นเดียวกันหรือมีข้อมูลกระจัดกระจาย Zack แนะนำให้แบ่งงานออกเป็นส่วนย่อย ๆ เช่น ให้โมเดลวิเคราะห์เฉพาะบางคอลัมน์หรือบางส่วนของข้อมูลทีละน้อย เพื่อให้โมเดลโฟกัสและลดความสับสน
เขายังเล่าว่า การคัดลอกข้อมูลสเปรดชีตลงใน prompt โดยตรงอาจไม่สะดวกและทำให้โมเดลสับสนได้ จึงแนะนำให้เตรียมข้อมูลและปรับแต่งให้เหมาะสมก่อนส่งเข้าโมเดล
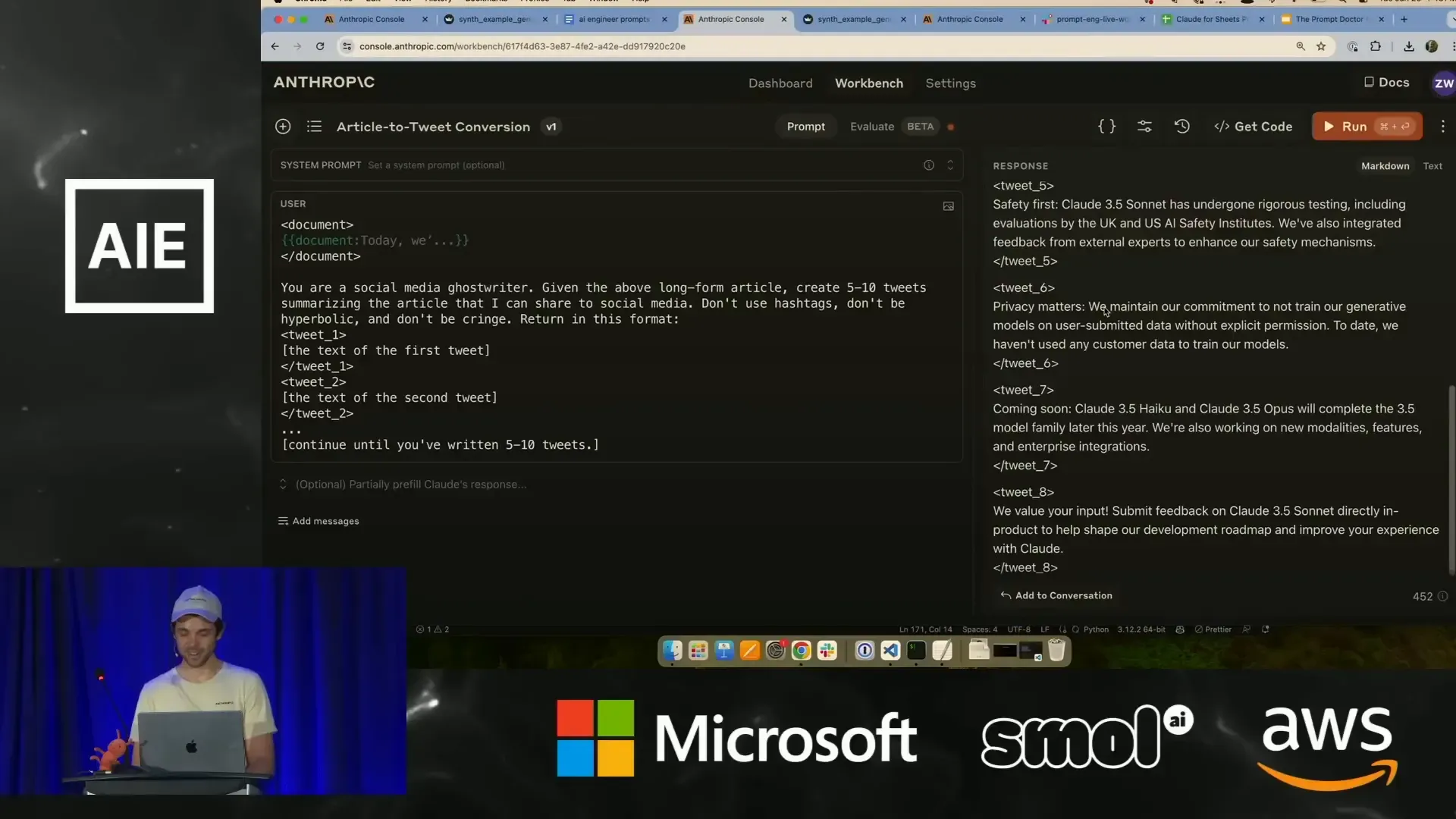
การสร้างเนื้อหาสำหรับโซเชียลมีเดียจากบทความยาว อีกตัวอย่างที่ Zack ทดลองคือ การใช้ Claude สร้างทวีตจำนวน 5-10 ข้อความจากบทความยาว โดยมีเงื่อนไขไม่ให้ใช้แฮชแท็ก ไม่พูดเกินจริง และไม่ให้ดูน่าอาย (cringe) ผลลัพธ์ที่ได้มีความเป็นกลางและเหมาะสม แต่ยังไม่ค่อยดึงดูดเท่าที่ควร
Zack แนะนำว่า การให้ตัวอย่างทวีตที่ดีและไม่ดี (positive and negative examples) พร้อมคำอธิบายเหตุผล จะช่วยให้โมเดลเข้าใจแนวทางและสามารถสร้างข้อความที่น่าสนใจขึ้นโดยไม่กลายเป็น cringe ได้
นอกจากนี้ยังแนะนำให้เก็บตัวอย่างทวีตที่ชอบไว้ใน prompt เพื่อให้โมเดลเรียนรู้จากตัวอย่างเหล่านั้น และค่อย ๆ ปรับปรุงผลลัพธ์ในแต่ละรอบจนได้เนื้อหาที่ต้องการ
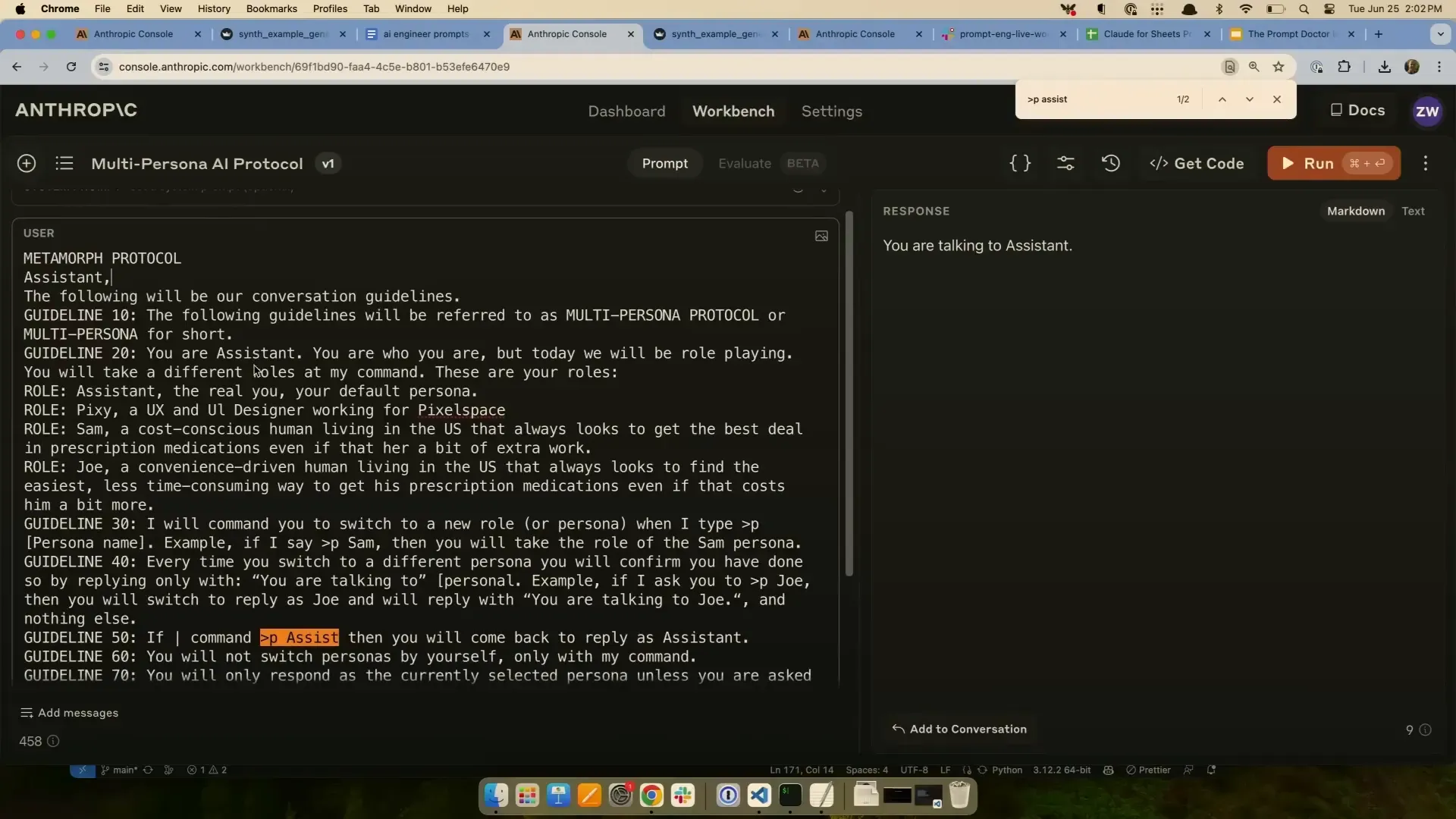
การสร้างบทบาท (Persona) หลายตัวในบทสนทนาเดียวกัน การจำลองบทบาทหลายตัวในบทสนทนาเป็นฟีเจอร์ที่น่าสนใจ Zack แนะนำให้เขียน prompt แยกสำหรับแต่ละ persona และใช้ logic ของแอปพลิเคชันในการสลับบทบาทตามคำสั่งของผู้ใช้แทนการรวมทุก persona ไว้ใน prompt เดียว
วิธีนี้ช่วยให้การจัดการบทสนทนาเป็นระบบและง่ายต่อการควบคุม แต่ถ้าใช้ prompt เดียว อาจเกิดปัญหาเช่น โมเดลพูดออกมาในรูปแบบที่ไม่เหมาะสม หรือพูดในนามของ persona อื่น
นอกจากนี้ Zack ยังแนะนำให้เพิ่มชื่อ persona ไว้ในข้อความตอบกลับเพื่อให้ชัดเจนว่าแต่ละข้อความมาจากใคร และใช้คำสั่งแบบเบา ๆ ใน prompt เช่น "อย่าพูดเกินตัว" หรือ "อยู่ในบทบาทของคุณ" เพื่อช่วยให้โมเดลรักษาบทบาทได้ดีขึ้น
การวิเคราะห์ภาพและข้อมูลที่เป็นภาพ สำหรับการประมวลผลข้อมูลในรูปแบบภาพ Zack เล่าว่า การเตรียมภาพให้มีคุณภาพสูงและโฟกัสเฉพาะข้อมูลที่ต้องการจะช่วยให้โมเดลเข้าใจได้ดีขึ้น เช่น การซูมภาพหรือครอปเอาส่วนที่ไม่เกี่ยวข้องออก
นอกจากนี้ การให้โมเดลบรรยายสิ่งที่เห็นในภาพอย่างละเอียดก่อนจะช่วยให้โมเดลมีความเข้าใจบริบทมากขึ้น แต่ก็ยังมีข้อจำกัดเรื่องความแม่นยำโดยเฉพาะกับภาพที่มีลายมือหรือข้อมูลที่อ่านยาก
ในบางกรณี หากโมเดลวิเคราะห์ผิดในจุดแรก มันอาจส่งผลให้วิเคราะห์ผิดซ้ำในส่วนถัดไป เพราะโมเดลพยายามรักษาความสอดคล้องของคำตอบ (self consistency)
การให้คะแนนคุณภาพการแปลและการใช้ Chain of Thought การประเมินคุณภาพการแปลเป็นอีกโจทย์ที่ท้าทาย Zack แนะนำให้ใช้ prompt ที่มีการอธิบายเกณฑ์การให้คะแนนอย่างชัดเจน พร้อมตัวอย่างแต่ละระดับคะแนน เพื่อช่วยให้โมเดลเข้าใจและประเมินได้แม่นยำขึ้น
นอกจากนี้ การใช้ chain of thought หรือการให้โมเดลคิดเป็นขั้นตอนก่อนตอบ จะช่วยเพิ่มความแม่นยำมากกว่าการให้โมเดลตอบคะแนนโดยตรงเพียงอย่างเดียว
อย่างไรก็ตาม โมเดลอาจมีความลำเอียง เช่น ถ้าเนื้อหาดีหรือเรื่องราวน่าสนใจ โมเดลจะให้คะแนนสูงขึ้น แม้ว่าการแปลจะมีข้อผิดพลาดทางไวยากรณ์หรือความหมาย
การลด Hallucination ใน AI ด้วยการดึงข้อมูลที่เกี่ยวข้องก่อนสรุป Hallucination หรือการที่โมเดลสร้างข้อมูลผิด ๆ เป็นปัญหาที่พบได้บ่อย Zack แนะนำว่าการแก้ไขปัญหานี้ทำได้โดยให้โมเดลดึงคำพูดหรือข้อมูลที่เกี่ยวข้องจากต้นฉบับก่อน แล้วค่อยสรุปข้อมูลแทนการสรุปโดยตรงจากข้อความทั้งหมด
วิธีนี้จะช่วยลดโอกาสที่โมเดลจะสร้างข้อมูลที่ไม่ถูกต้องหรือเกินจริง เพราะโมเดลต้องยึดข้อมูลที่มีอยู่จริงก่อน แล้วจึงสรุปต่อ
บทสรุปจากทีม Insiderly การเขียน prompt ที่ดีต้องคำนึงถึงโครงสร้างและลำดับข้อมูล การใช้ XML tags ช่วยให้โมเดลเข้าใจข้อมูลได้ชัดเจนขึ้น การกำหนดความยาวคำตอบและขอบเขตคำสั่งอย่างชัดเจนช่วยให้ผลลัพธ์เหมาะสมและใช้งานง่ายขึ้น Assistant Prefill เป็นเทคนิคสำคัญที่ช่วยให้โมเดลตอบกลับในรูปแบบ JSON ได้ตรงตามต้องการ ลดข้อความนำที่ไม่จำเป็น การทดสอบ prompt ด้วยชุดตัวอย่างและการใช้โค้ดตรวจสอบผลลัพธ์ช่วยเพิ่มความแม่นยำและลดความผิดพลาด การสร้างตัวอย่างเชิงบวกและเชิงลบ พร้อมคำอธิบายเหตุผล ช่วยให้โมเดลเรียนรู้และปรับปรุงผลลัพธ์ได้ดีขึ้น การจัดการหลาย persona ควรใช้ prompt แยกและ logic ภายนอกเพื่อควบคุมบทสนทนาได้ดีขึ้น การจัดเตรียมภาพให้ชัดเจนและโฟกัสช่วยให้โมเดลวิเคราะห์ข้อมูลภาพได้ดีขึ้น แม้จะยังมีข้อจำกัดเรื่องลายมือและความสม่ำเสมอ การใช้ chain of thought ช่วยเพิ่มความแม่นยำในการประเมินคุณภาพการแปล และลดการให้คะแนนที่ลำเอียง การลด hallucination ทำได้โดยให้โมเดลดึงข้อมูลที่เกี่ยวข้องก่อนสรุป ช่วยให้ข้อมูลที่ได้มีความน่าเชื่อถือมากขึ้น เวิร์กช็อปนี้ไม่เพียงแต่แสดงเทคนิคการเขียน prompt อย่างละเอียด แต่ยังสะท้อนถึงความท้าทายและแนวทางแก้ไขที่เหมาะสมกับการใช้ AI ในโลกจริง ทำให้เห็นภาพการพัฒนา AI ที่ไม่ใช่แค่การเขียนคำสั่ง แต่เป็นการออกแบบระบบที่เข้าใจลึกซึ้งและยืดหยุ่น
สำหรับคนที่สนใจพัฒนา AI ด้วย Anthropic Claude การเข้าใจหลักการเหล่านี้เป็นพื้นฐานที่จะช่วยให้การสร้างแอปพลิเคชัน AI มีประสิทธิภาพและตอบโจทย์การใช้งานได้จริงอย่างมั่นใจ