

Introducing GPT-5: ก้าวใหม่ของ AI ที่ฉลาดและเก่งกว่าเดิม
พบกับ GPT-5 รุ่นล่าสุดจาก OpenAI ที่พัฒนา AI ให้ฉลาดขึ้น รวดเร็วขึ้น และน่าเชื่อถือมากกว่าเดิม พร้อมความสามารถ reasoning, การสร้างซอฟต์แวร์ และใช้งานฟรีผ่าน ChatGPT
พบกับ GPT-5 รุ่นล่าสุดจาก OpenAI ที่พัฒนา AI ให้ฉลาดขึ้น รวดเร็วขึ้น และน่าเชื่อถือมากกว่าเดิม พร้อมความสามารถ reasoning, การสร้างซอฟต์แวร์ และใช้งานฟรีผ่าน ChatGPT

เรียนรู้วิธีใช้ ChatGPT Agent ระบบ AI อัจฉริยะในการวิจัยข้อมูล สร้างแผนธุรกิจ และวิเคราะห์ตลาดอีคอมเมิร์ซสายสุขภาพและฟิตเนสอย่างครบถ้วน รวดเร็วและแม่นยำในเวลาไม่ถึง 10 นาที
สำรวจวิวัฒนาการ AI ในการพัฒนาโปรแกรมและเหตุผลที่ CLI จะเป็นเครื่องมือหลักแห่งอนาคต ช่วยสร้าง workflow AI agents ให้ vibe coding มีความมั่นใจและคุณภาพสูงขึ้น
AI กำลังก้าวสู่ขั้นใหม่ด้วย Language Concept Models (LCMs) เรียนรู้ว่าโมเดลภาษาเชิงแนวคิดนี้ทำงานอย่างไร แตกต่างจาก LLM เดิมอย่างไร และจะทำให้ AI เข้าใจและคิดได้เหมือนมนุษย์มากขึ้นได้อย่างไร

ช่วงหลายปีที่ผ่านมา เราได้เห็นความสามารถของ AI ในการสร้างสรรค์ข้อความหรือรูปภาพที่น่าทึ่งจนแทบแยกไม่ออกกับสิ่งที่มนุษย์ทำได้ ใช่ครับ กำลังพูดถึง Generative AI ที่มีโมเดลภาษาใหญ่ๆ หรือ LLMs เป็นหัวใจสำคัญนั่นแหละ
LLMs เก่งมากๆ ในการเดาคำถัดไปจากประโยคที่เราให้ไป ลองนึกภาพว่า AI เหมือนนักเดาคำอัจฉริยะที่อ่านมามหาศาลจนรู้ว่าคำไหนควรจะมาต่อจากคำไหน แต่ในอีกแง่หนึ่ง มันก็ยังทำงานอยู่บนพื้นฐานของการเชื่อมโยงคำศัพท์เป็นหลัก ยังไม่ใช่การ "เข้าใจ" ในระดับแนวคิดจริงๆ จังๆ เหมือนสมองคนเรา
แล้วถ้า AI ไม่ได้แค่เดาคำ แต่สามารถ "คิด" และ "เข้าใจ" ในระดับแนวคิดของประโยคได้ล่ะ? นั่นแหละคือสิ่งที่นักวิจัยกำลังมุ่งหน้าไปสู่ กับเทคโนโลยีที่เรียกว่า Language Concept Models หรือ LCMs นี่คือก้าวสำคัญถัดไปที่จะปลดล็อกศักยภาพของ Generative AI ให้ฉลาด ลึกซึ้ง และมีความเข้าใจโลกได้ใกล้เคียงกับมนุษย์มากขึ้น

ลองจินตนาการว่า LLMs ทำงานเหมือนเรากำลังต่อจิ๊กซอว์ตัวอักษร มันมองชิ้นส่วน (โทเค็น) ที่มีอยู่ แล้วก็เดาว่าชิ้นต่อไปที่เป็นไปได้มากที่สุดคือชิ้นไหน ทำไปเรื่อยๆ ก็ได้ข้อความยาวๆ ออกมา
แต่โลกนี้ซับซ้อนกว่าแค่ตัวอักษร ความหมายจริงๆ มักจะอยู่ในระดับที่สูงกว่านั้น เช่น ประโยค "ฉันรักการอ่านหนังสือ" กับ "การอ่านหนังสือคือความสุขของฉัน" สองประโยคนี้ใช้คำต่างกัน แต่มี "แนวคิด" หลักๆ คล้ายกัน คือ "การอ่านหนังสือ" กับ "ความรู้สึกเชิงบวก/ความสุข"
นี่คือจุดที่ LCMs แตกต่างออกไป แทนที่จะเดา โทเค็น ถัดไปจากชุดโทเค็นที่ได้รับ LCMs จะพยายามทำนาย แนวคิด ถัดไปจากชุดประโยคหรือข้อมูลที่ได้รับ
พูดง่ายๆ คือ LCMs ไม่ได้มองแค่ก้อนอิฐทีละก้อน (โทเค็น) แต่พยายามทำความเข้าใจภาพรวมของอาคาร (แนวคิด) ที่กำลังจะสร้าง ทำให้ AI สามารถคิดในเชิงนามธรรม และมีความเข้าใจที่ลึกกว่าแค่พื้นผิวของคำศัพท์
หัวใจสำคัญที่ทำให้ AI ทั้ง LLMs และ LCMs ทำงานได้ คือการแปลงภาษาให้กลายเป็นสิ่งที่คอมพิวเตอร์เข้าใจได้ นั่นคือ Embeddings
ลองนึกภาพว่าโลกของคำศัพท์และประโยคถูกแปลงให้กลายเป็น "แผนที่ความคิด" ที่มีหลายมิติ (เหมือนแผนที่โลก 3 มิติ หรือมากกว่านั้น) แต่ละคำหรือแต่ละประโยคจะกลายเป็นจุดหนึ่งบนแผนที่นี้
การมี "แผนที่ความคิด" หรือ Embeddings ที่ดีนี่เอง ที่ทำให้ AI ไม่ได้มองแค่คำว่า "apple" เป็นแค่ตัวอักษร 5 ตัว แต่เข้าใจว่ามันเป็นผลไม้ชนิดหนึ่ง เป็นบริษัทเทคโนโลยี หรืออาจหมายถึงลูกตา ขึ้นอยู่กับว่า "apple" ตัวนั้นอยู่ใกล้กับคำว่าอะไรบนแผนที่ความคิด (อยู่ใกล้ "fruit," "pie," "tree" หรืออยู่ใกล้ "iPhone," "MacBook")
วิวัฒนาการของ "แผนที่ความคิด" (Embeddings): จากนับคำ สู่เข้าใจบริบท
การสร้างแผนที่ความคิด หรือ Embeddings ก็มีพัฒนาการมาเรื่อยๆ
โมเดลดังๆ ในกลุ่ม Prediction-Based Embeddings ที่เราอาจเคยได้ยินชื่อ เช่น:
ถ้าเปรียบเทียบ LLM เป็นโรงงานผลิตข้อความ Embeddings ก็เหมือนวัตถุดิบชั้นดีที่ถูกส่งเข้าโรงงานนี้
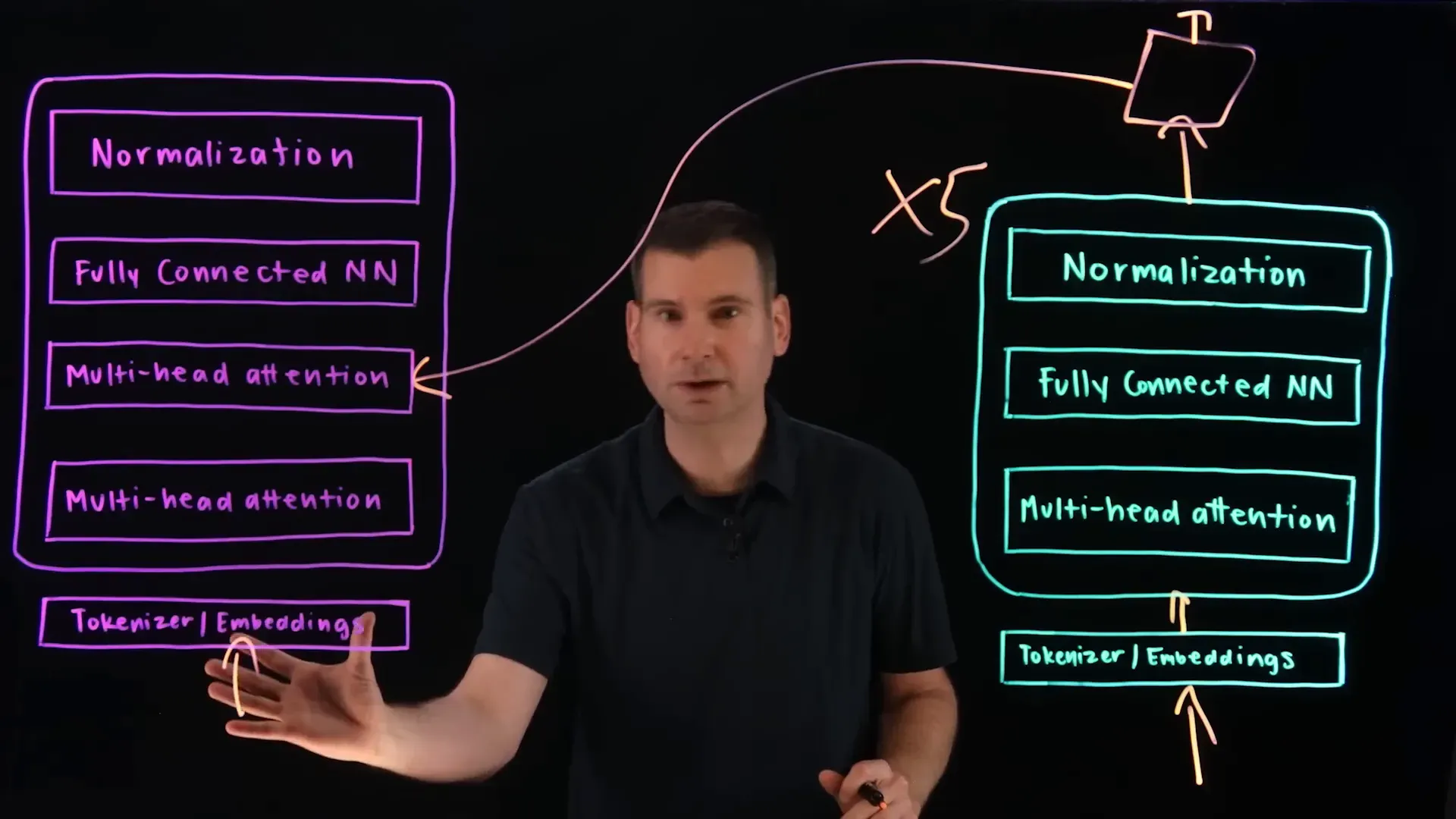
สถาปัตยกรรมแบบ Encoder-Decoder ที่มี Attention นี่แหละ คือหัวใจสำคัญของโมเดลภาษาขนาดใหญ่ยุคปัจจุบันหลายๆ ตัว รวมถึง Transformer Models อันโด่งดังที่เป็นรากฐานของ LLMs อย่าง ChatGPT
อย่างที่เกริ่นไป LLMs เก่งในการทำนายโทเค็นถัดไปจากโทเค็นก่อนหน้า ซึ่งทำให้มันสร้างข้อความได้ดีมาก แต่ LCMs ต้องการไปไกลกว่านั้น ด้วยการทำนาย "แนวคิด" หรือ "ประโยค" ถัดไป
"แนวคิด" ในที่นี้ไม่ใช่แค่คำศัพท์ แต่เป็นตัวแทนของความคิด ไอเดีย หรือสาระสำคัญในระดับที่สูงขึ้น และที่สำคัญคือ:
การทำงานของ LCMs ก็คือการใช้ Embeddings ที่เป็นตัวแทนของแนวคิด (ไม่ใช่แค่คำ) มาประมวลผล

โมเดลอย่าง SONAR ที่กล่าวถึงก่อนหน้านี้ ถูกออกแบบมาโดยเฉพาะเพื่อแปลงประโยคหรือข้อความให้กลายเป็น Embeddings ที่ "จับ" เอาแนวคิดของข้อความนั้นๆ ไว้ได้อย่างมีประสิทธิภาพ
กระบวนการทำงานเบื้องต้นของ LCM ที่ใช้ SONAR อาจเป็นแบบนี้:
การทำงานในระดับแนวคิดแบบนี้ ช่วยให้ AI เข้าใจลำดับขั้นของข้อมูลที่ซับซ้อน และคิดในเชิงนามธรรมได้ดีขึ้น
หนึ่งในแนวทางที่น่าสนใจในการพัฒนา LCMs คือการนำเทคนิคที่เรียกว่า Diffusion Model มาใช้ ซึ่งเทคนิคนี้โด่งดังมากจากการสร้างรูปภาพ AI ที่สมจริง
ลองนึกภาพการสร้างภาพ AI ด้วย Diffusion: มันมักจะเริ่มจากภาพที่มี Noise หรือความเบลอมากๆ แล้วค่อยๆ ลด Noise ลงทีละน้อย จนได้ภาพที่คมชัดสมจริง
แนวคิดนี้ถูกนำมาปรับใช้กับ LCMs โดย:
การใช้ Diffusion Model ช่วยให้ LCMs สามารถทำนายแนวคิดได้อย่างแม่นยำและน่าเชื่อถือมากขึ้น โดยมักจะใช้สถาปัตยกรรมแบบ two-tower architecture โดยมีส่วนหนึ่งทำหน้าที่ ลด Noise (denoiser) และอีกส่วนทำหน้าที่ "ถอดรหัส" (decoder) แนวคิดที่ได้ออกมา
การก้าวจาก LLMs ที่เน้นโทเค็น มาสู่ LCMs ที่เน้นแนวคิดนี้ เปิดประตูสู่ความสามารถใหม่ๆ ที่น่าตื่นเต้นของ AI:
การเกิดขึ้นและการพัฒนาของ Language Concept Models หรือ LCMs ถือเป็นวิวัฒนาการที่สำคัญของ Generative AI อย่างแท้จริง เรากำลังเปลี่ยนผ่านจากการมี AI ที่เก่งกาจในการเลียนแบบรูปแบบภาษา ไปสู่ AI ที่เริ่มมีความสามารถในการ "เข้าใจ" และ "คิด" ในระดับที่ลึกซึ้งและเป็นนามธรรมมากขึ้น
การทำงานในระดับแนวคิดนี้ ไม่เพียงแต่ทำให้ AI จัดการกับความซับซ้อนของภาษาและข้อมูลได้ดีขึ้น แต่ยังปูทางไปสู่ระบบ AI ที่มีความยืดหยุ่น สามารถเรียนรู้และปรับตัวเข้ากับข้อมูลรูปแบบใหม่ๆ ได้ง่ายขึ้น ความสามารถในการเชื่อมโยงแนวคิดข้ามรูปแบบข้อมูล (Modality-Agnostic) จะเป็นกุญแจสำคัญในการสร้าง AI ที่สามารถโต้ตอบและช่วยเหลือมนุษย์ในโลกแห่งความเป็นจริงที่เต็มไปด้วยข้อมูลหลากหลายรูปแบบ
LCMs เป็นสัญญาณที่ชัดเจนว่า AI กำลังก้าวเข้าใกล้การมีความเข้าใจโลกในแบบที่เราเป็นอยู่ ซึ่งจะนำไปสู่แอปพลิเคชันและนวัตกรรมใหม่ๆ ที่เราอาจยังนึกไม่ถึง เป็นอนาคตของ AI ที่น่าจับตาอย่างยิ่ง และจะทำให้ AI กลายเป็นผู้ช่วยที่ชาญฉลาดและพึ่งพาได้มากขึ้นในทุกๆ ด้านของชีวิต

พบกับ GPT-5 รุ่นล่าสุดจาก OpenAI ที่พัฒนา AI ให้ฉลาดขึ้น รวดเร็วขึ้น และน่าเชื่อถือมากกว่าเดิม พร้อมความสามารถ reasoning, การสร้างซอฟต์แวร์ และใช้งานฟรีผ่าน ChatGPT

เจาะลึกแนวโน้มการประเมินผล AI ในปี 2025 ที่จะเปลี่ยนวิธีการบริหารและตัดสินใจในองค์กร ด้วยบทวิเคราะห์จาก John Dickerson ซีอีโอ Mozilla AI ถึงบทบาทสำคัญของ Agentic AI และความจำเป็นของการประเมินผล AI อย่างละเอียด

เจาะลึกการใช้ AI Claude Code และเครื่องมือจัดการ Workflow Roast ในการเพิ่มประสิทธิภาพทีมวิศวกรและการพัฒนาระบบขนาดใหญ่ที่ Shopify พร้อมวิเคราะห์ความท้าทายและโอกาสในยุคซอฟต์แวร์สมัยใหม่

เจาะลึกไดเรกทอรีเครื่องมือที่เชื่อมต่อ Claude กับ Notion, Canva, Figma และ Stripe ช่วยจัดการโปรเจกต์และงานร่วมกันได้สะดวก รวดเร็ว และมีประสิทธิภาพมากขึ้น