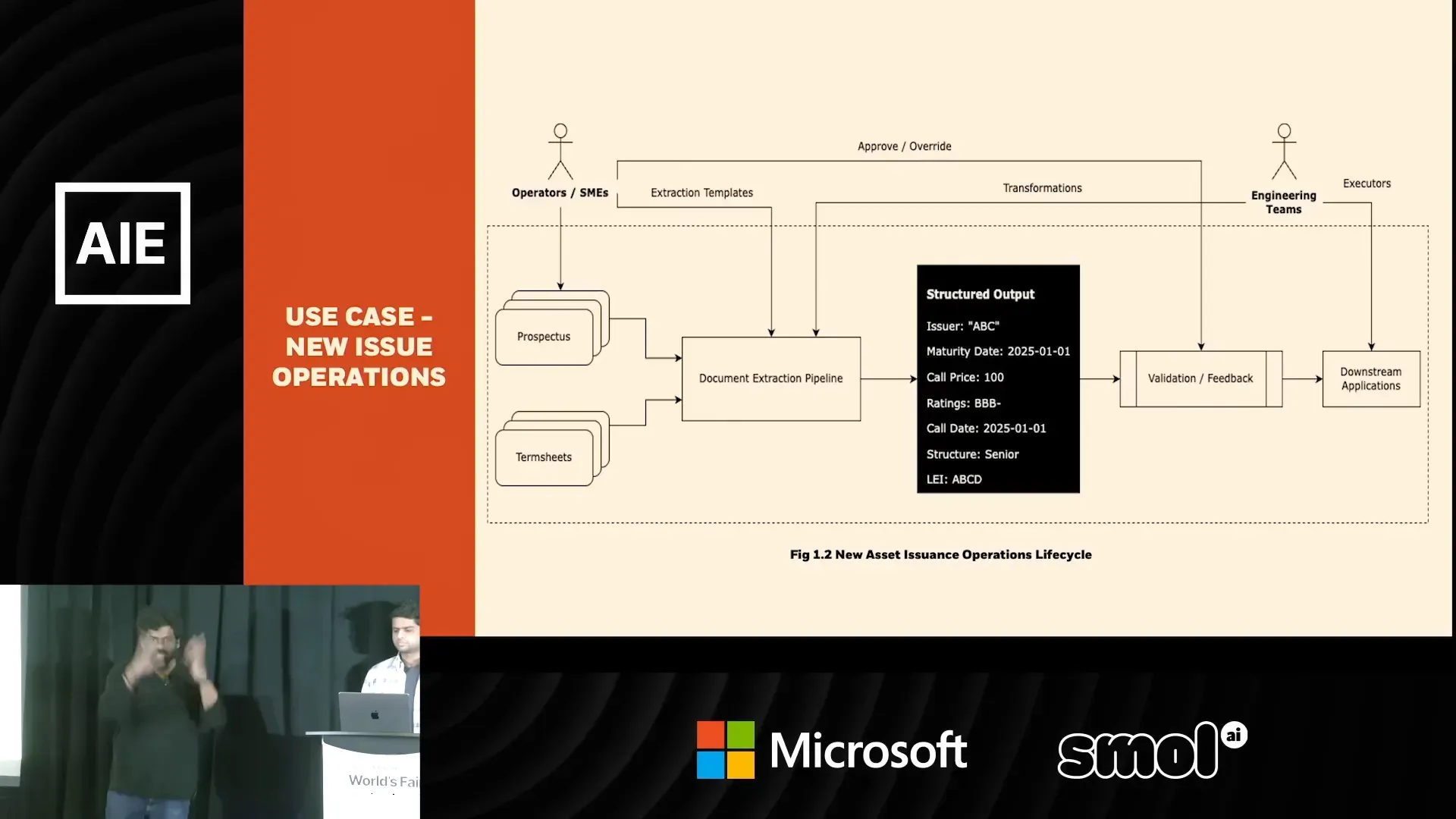
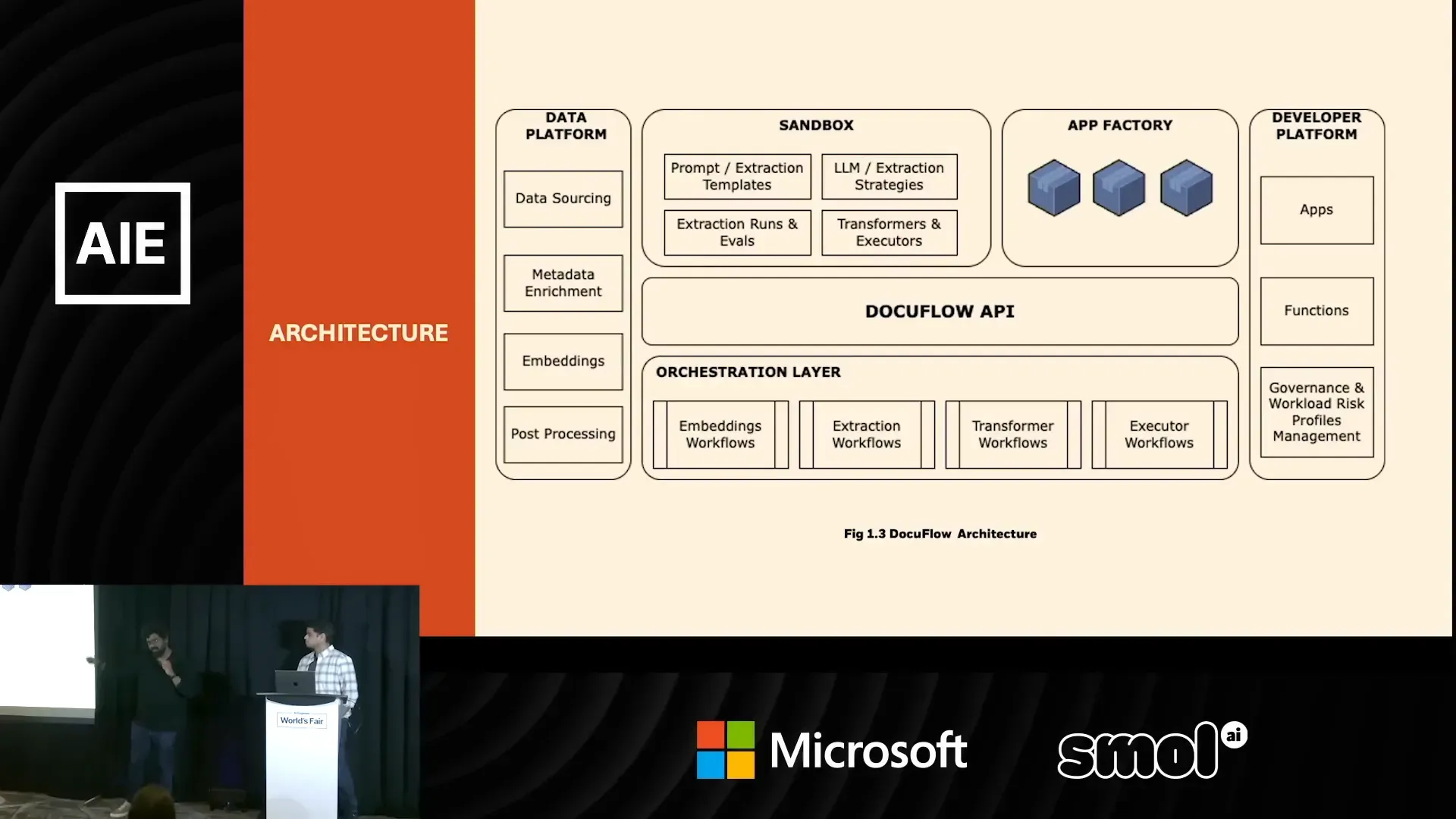
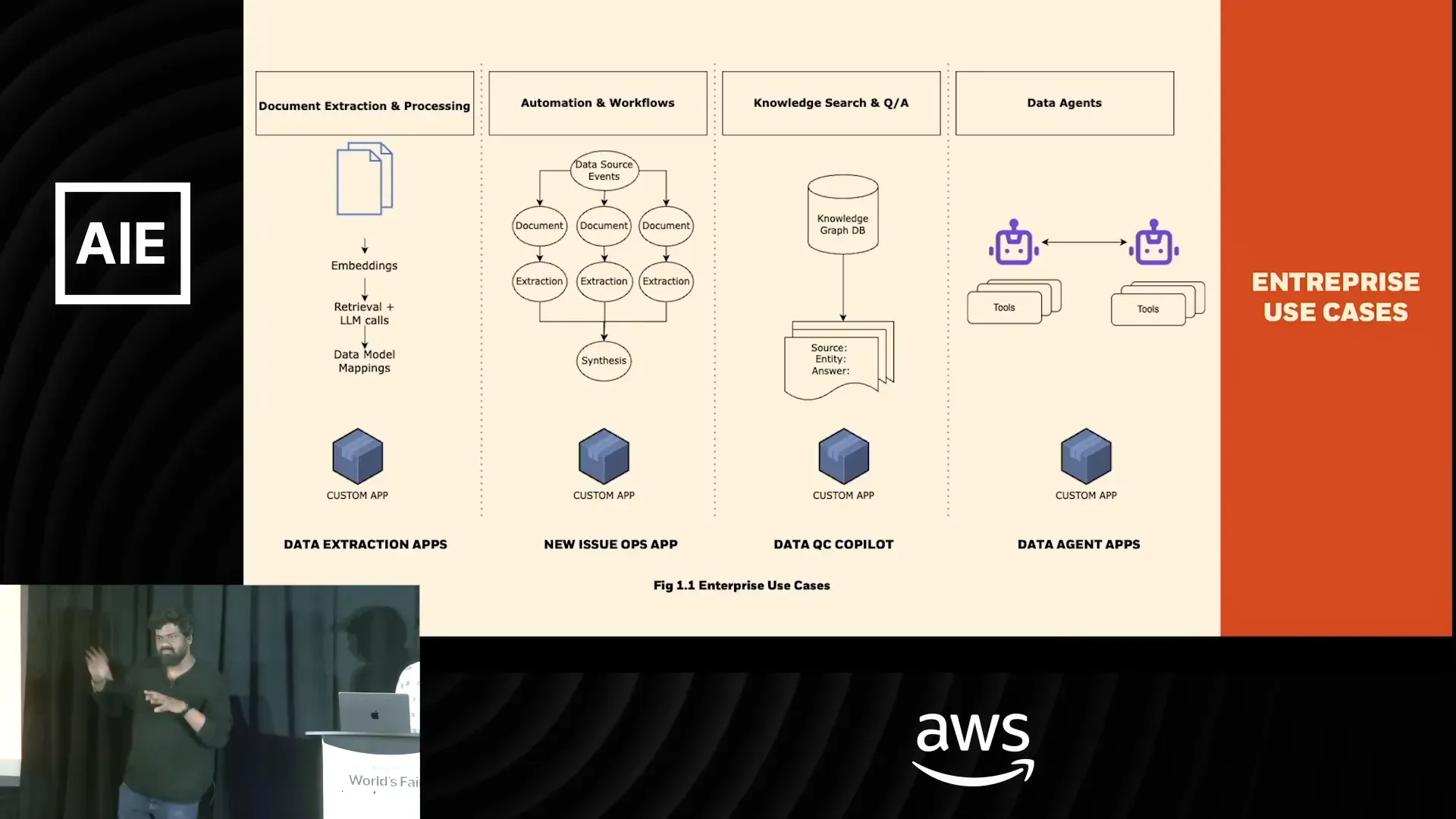
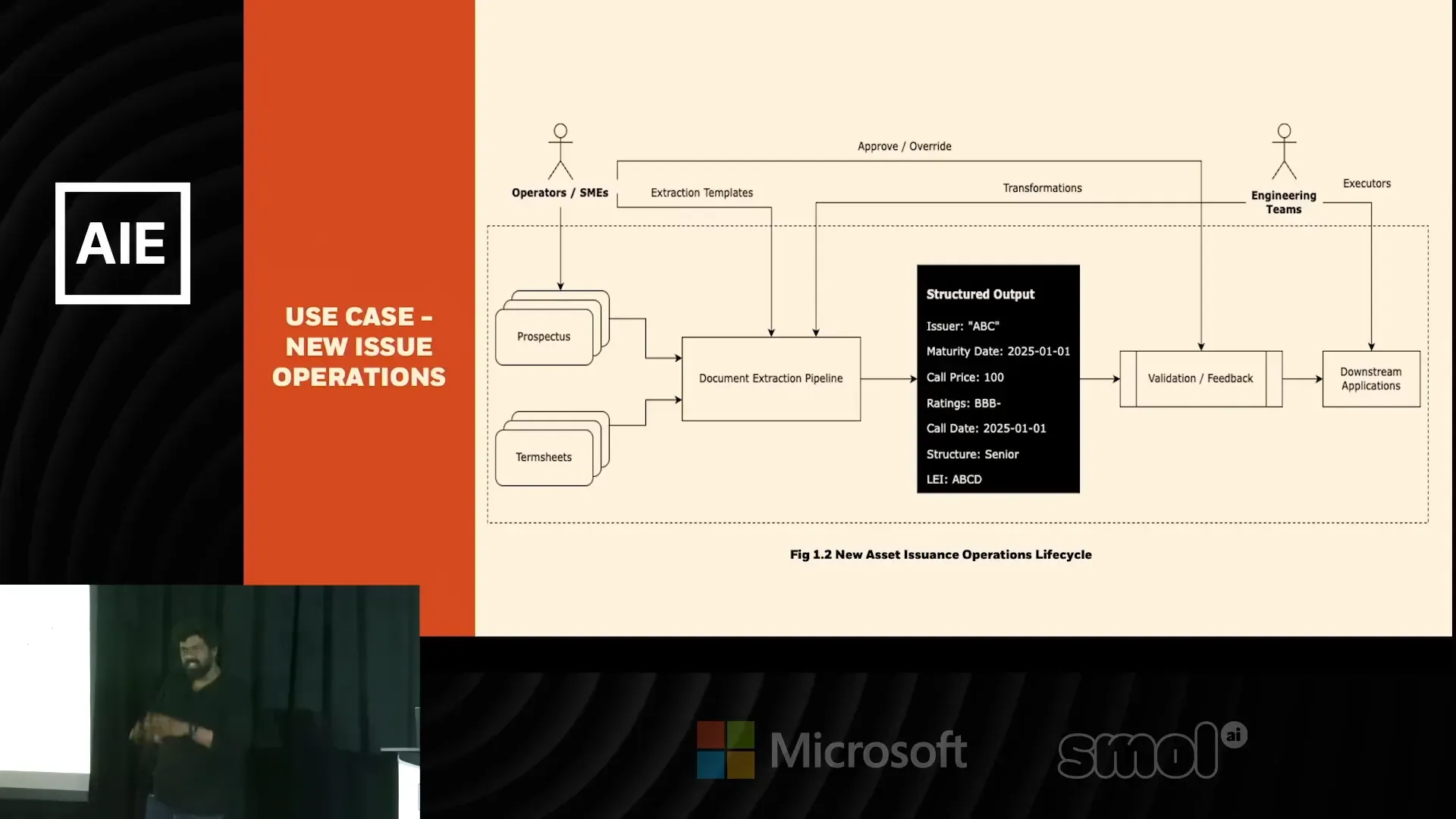
OpenAI to Z Challenge: ทีม Black Bean ใช้ Deep Learning และ OpenAI เปลี่ยนข้อมูล LiDAR เป็นแผนที่ค้นหาแหล่งโบราณคดีในผืนป่าฝนอะเมซอน
ผลงานทีม Black Bean จาก OpenAI to Z Challenge — Archaios ผสาน LiDAR, ภาพดาวเทียม และโมเดล OpenAI เพื่อค้นหาและคัดกรองไซต์โบราณในป่าฝนอะเมซอน พบประมาณ 100 จุดที่มีศักยภาพ