
สรุปจากคลิป ดูคลิปต้นฉบับ
Beyond Transcription: ถอดบทเรียน Voice AI ที่เข้าใจบทสนทนาจริง

ปัญหาของ Voice AI ไม่ได้อยู่แค่แปลงเสียงเป็นข้อความได้หรือไม่ แต่อยู่ที่ว่า ระบบเข้าใจบทสนทนาได้แค่ไหน ต่างหาก เพราะในโลกการทำงานจริง การรู้เพียงว่ามีคำอะไรถูกพูดออกมา ยังไม่พอสำหรับการสรุปประชุม การบริการลูกค้า การแปลเสียง หรือการวิเคราะห์คุณภาพการสนทนา
คลิปนี้จากช่อง AI Engineer เป็นเซสชันของ Hervé Bredin จาก pyannoteAI ที่อธิบายชัดมากว่า ทำไมระบบ speech-to-text แบบเดิมถึงยังไม่ตอบโจทย์งานธุรกิจจำนวนมาก และอะไรคือชิ้นส่วนสำคัญที่ต้องเติมเข้าไปให้ AI เข้าใจ “การคุยกัน” ไม่ใช่แค่ “คำพูด” ประเด็นที่น่าสนใจคือ เขาไม่ได้ขายฝัน แต่ชี้ให้เห็นทั้งศักยภาพ ข้อจำกัด และจุดที่ benchmark ในตลาดมักทำให้เราเข้าใจผิด
สารบัญ
- Step 1: เริ่มจากเข้าใจก่อนว่า transcription ไม่เท่ากับ understanding
- Step 2: เพิ่มชั้นความเข้าใจด้วย speaker diarization หรือการรู้ว่าใครพูดตอนไหน
- Step 3: อย่ามองข้ามเรื่องเวลา เพราะ timestamp เปลี่ยนความหมายของบทสนทนา
- Step 4: เข้าใจว่าคนพูด “อย่างไร” ก็สำคัญไม่แพ้ “พูดอะไร”
- Step 5: รู้ข้อจำกัดของ benchmark ก่อนตัดสินว่าโมเดลไหน “ดี”
- Step 6: รู้จัก metric ที่ใช้วัด diarization เพื่อไม่หลงกับคำว่าแม่น
- Step 7: จุดยากจริงไม่ใช่แค่ถอดเสียงหรือแยกคนพูด แต่คือการเอาสองอย่างมาประกบกัน
- Step 8: ดู use case ที่ได้ประโยชน์จริงจากการเข้าใจบทสนทนา
- Step 9: ประเมินความพร้อมก่อนเอาไปใช้ในธุรกิจไทย
- Step 10: แปลงแนวคิดนี้เป็น Actionable Insights สำหรับธุรกิจ
- Step 11: Troubleshooting ปัญหาที่มักเจอเมื่อเริ่มทำตามแนวทางนี้
- Step 12: การต่อยอดที่น่าทำต่อ
- Step 13: สรุป Checklist ทั้งหมด
Step 1: เริ่มจากเข้าใจก่อนว่า transcription ไม่เท่ากับ understanding
หลายองค์กรเริ่มต้นใช้ AI กับเสียงด้วยการเอาไฟล์ประชุม ไฟล์คอลเซ็นเตอร์ หรือไฟล์สัมภาษณ์ไปถอดเป็นข้อความ แล้วหวังว่าจะใช้ต่อได้ทันที แต่นั่นเป็นแค่ชั้นแรกของงานเท่านั้น
การถอดเสียงตอบคำถามว่า “พูดว่าอะไร” แต่ธุรกิจส่วนใหญ่ต้องการมากกว่านั้น เช่น
- ใครเป็นคนพูด
- พูดตอนไหน
- ขัดจังหวะกันหรือไม่
- ตอบรับ เห็นด้วย ลังเล หรือกดดันอยู่หรือเปล่า
- กำลังพูดกับใครในวงสนทนา
ถ้าระบบตอบไม่ได้ว่าใครพูดอะไร ข้อความที่ถอดมาอาจอ่านออก แต่ใช้งานต่อยากมาก โดยเฉพาะในการประชุมหลายคน หรือการคุยกับลูกค้าที่มีการพูดทับกันบ่อย
สำหรับเจ้าของธุรกิจไทย เรื่องนี้สำคัญมาก เพราะหลายทีมกำลังใช้ AI ทำ meeting summary, QA call center, sales coaching และ customer insight ถ้าฐานข้อมูลต้นทางยังแยกคนพูดไม่ออก สรุปสุดท้ายก็มักผิดคน ผิดเจตนา และผิด action item
Step 2: เพิ่มชั้นความเข้าใจด้วย speaker diarization หรือการรู้ว่าใครพูดตอนไหน
หัวใจของคลิปนี้คือแนวคิดเรื่อง speaker diarization ซึ่งตอบคำถามว่า “ใครพูดเมื่อไหร่” ไม่ใช่แค่แปลงเสียงเป็นตัวอักษร
งานนี้มีหลายชั้นย่อย เช่น
- ตรวจว่าช่วงไหนมีคนกำลังพูด
- แบ่งช่วงเสียงยาวออกเป็นช่วงย่อยตามจังหวะการพูด
- หาให้เจอว่าจุดไหนมีการเปลี่ยนคนพูด
- จับช่วงที่มีการพูดทับกัน
- รวมช่วงเสียงที่น่าจะเป็นคนเดียวกันเข้าด้วยกัน
จุดที่น่าสนใจคือ ระบบประเภทนี้มักไม่ได้รู้ชื่อจริงของคนพูดตั้งแต่ต้น ผลลัพธ์ที่ได้จึงมักออกมาเป็น speaker 1, speaker 2, speaker 3 มากกว่า ซึ่งเพียงพอสำหรับหลายงาน เช่น การสรุปประชุมหรือการวิเคราะห์สายสนทนา
ในมุมธุรกิจ นี่คือสิ่งที่ช่วยให้เราปรับจาก “มีข้อความ” ไปเป็น “มีโครงสร้างบทสนทนา” และโครงสร้างนี่เองที่ทำให้ AI รุ่นถัดไปทำงานต่อได้ดีขึ้น
Step 3: อย่ามองข้ามเรื่องเวลา เพราะ timestamp เปลี่ยนความหมายของบทสนทนา
อีกจุดที่คลิปนี้อธิบายได้คมมากคือ การรู้แค่ว่าใครพูดอะไรยังไม่พอ ต้องรู้ด้วยว่า พูดเมื่อไหร่ และสัมพันธ์กับคำพูดของคนอื่นอย่างไร
เหตุผลคือบทสนทนาไม่ได้เป็นข้อความเรียงตรงแบบเอกสาร แต่เต็มไปด้วยสัญญาณย่อย เช่น
- การขัดจังหวะ
- การพยักหน้ารับด้วยเสียงสั้นๆ
- การเว้นช่วงก่อนตอบ
- การพูดแทรกระหว่างอีกฝ่ายยังไม่จบ
รายละเอียดพวกนี้แปลความหมายได้ต่างกันมาก ตัวอย่างเช่น เสียงตอบรับสั้นๆ อาจหมายถึงเห็นด้วย รับทราบ หรือแค่พยายามรักษาจังหวะสนทนา ถ้าระบบพลาดช่วงสั้นเหล่านี้ การวิเคราะห์ความรู้สึกหรือเจตนาของคู่สนทนาก็เพี้ยนทันที
สำหรับงานขายและบริการลูกค้าในไทย ประเด็นนี้ใช้ได้จริงมาก เช่น สายที่ลูกค้าพูดแทรกบ่อย อาจสะท้อนความไม่พอใจ สายที่พนักงานเว้นจังหวะนานก่อนตอบ อาจสะท้อนว่าหาข้อมูลไม่เจอ หรือไม่มั่นใจในคำตอบ สิ่งเหล่านี้มีค่ากับทีมเทรนงานมากกว่าการอ่านคำพูดอย่างเดียว
Step 4: เข้าใจว่าคนพูด “อย่างไร” ก็สำคัญไม่แพ้ “พูดอะไร”
คลิปยังชี้ให้เห็นอีกชั้นว่า ถ้าจะทำ Voice AI ให้เก่งขึ้นจริง ระบบควรเก็บสัญญาณเพิ่ม เช่น การหัวเราะ การไอ ความตึงเครียด ความติดขัดในการพูด และน้ำหนักเสียงในบางคำ
ทำไมเรื่องนี้ถึงสำคัญ เพราะประโยคเดียวกันอาจมีความหมายต่างกันตามน้ำเสียง ตัวเน้น และจังหวะพูด ตัวอักษรอย่างเดียวจับไม่ได้ทั้งหมด
ในโลกธุรกิจ นี่คือประเด็นที่ทำให้ AI สามารถพัฒนาไปสู่ use case ที่มีมูลค่าสูงขึ้น เช่น
- วัดความมั่นใจของพนักงานขาย
- จับสัญญาณความไม่พอใจของลูกค้าก่อนจะบานปลาย
- วิเคราะห์คุณภาพการสัมภาษณ์งาน
- สรุปว่าใครกำลังตอบเชิงป้องกันหรือเลี่ยงประเด็น
อย่างไรก็ตาม ตรงนี้เองที่เราควรระวังไม่ให้คาดหวังเกินจริง เพราะการตีความอารมณ์จากเสียงเป็นเรื่องละเอียดและขึ้นกับภาษา วัฒนธรรม และสถานการณ์มาก ระบบอาจจับสัญญาณได้ แต่ไม่ได้แปลว่าจะตีความถูกเสมอไป โดยเฉพาะในภาษาไทยที่มีโทนเสียงและบริบททางสังคมเข้ามาเกี่ยวข้องเยอะ
Step 5: รู้ข้อจำกัดของ benchmark ก่อนตัดสินว่าโมเดลไหน “ดี”
หนึ่งใน insight ที่แรงที่สุดของคลิปคือการตั้งคำถามกับ benchmark ในวงการ ASR และ Voice AI หลายครั้งตัวเลขที่สวยมากเกิดจากการทดสอบบนข้อมูลที่ง่ายกว่างานจริง เช่นเสียงจากไมค์ใกล้ปาก คนพูดคนเดียว สภาพแวดล้อมเงียบ
แต่พอเอา model เดียวกันไปใช้กับไมค์กลางโต๊ะในการประชุมหลายคน ผลลัพธ์กลับแย่ลงมาก แม้จะเป็นชุดข้อมูลเดียวกันก็ตาม นี่สะท้อนว่าเราไม่ควรดู leaderboard แบบผิวเผิน
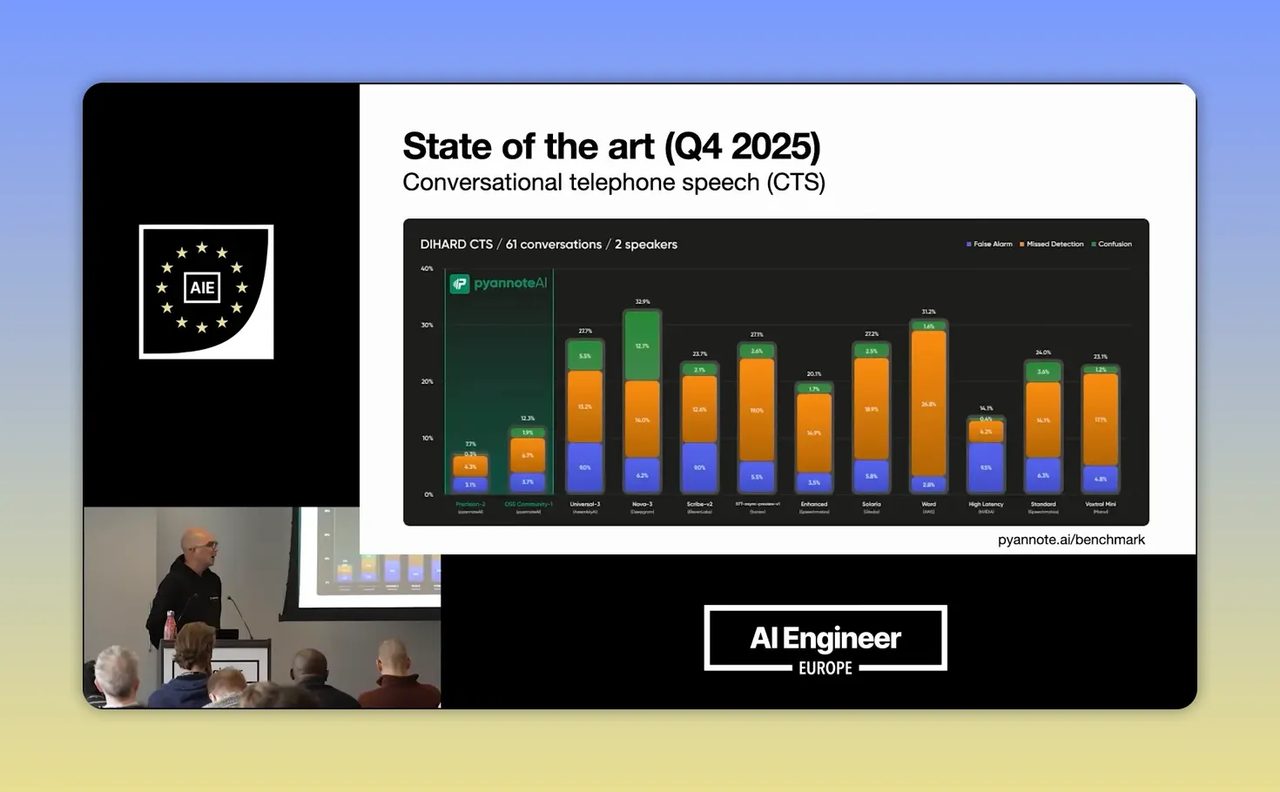
สิ่งที่องค์กรไทยควรถามก่อนเลือกเครื่องมือมีอย่างน้อย 4 ข้อ
- ทดสอบกับเสียงจากอุปกรณ์แบบไหน
- เป็นเสียงคนเดียวหรือหลายคน
- มีเสียงรบกวนมากน้อยแค่ไหน
- มีการพูดทับกันจริงหรือไม่
ถ้า use case ของเราเป็นประชุมในห้อง สายบริการลูกค้า หรือการคุยหน้าร้าน ตัวเลขจาก benchmark ที่เน้น clean speech อาจไม่ได้ช่วยตัดสินใจมากนัก
สำหรับข้อมูลเพิ่มเติมเรื่องการประเมินระบบรู้จำเสียง สามารถดูแนวทางพื้นฐานได้จาก Hugging Face Audio Course ซึ่งอธิบาย metric และข้อควรระวังได้ดี
Step 6: รู้จัก metric ที่ใช้วัด diarization เพื่อไม่หลงกับคำว่าแม่น
ในการประเมิน speaker diarization มักใช้ตัวชี้วัดชื่อว่า DER หรือ Diarization Error Rate ซึ่งรวมความผิดพลาดหลัก 3 แบบ
- Confusion คือจับคนพูดผิด
- False alarm คือคิดว่ามีคนพูดทั้งที่จริงไม่มี
- Missed detection คือมีคนพูดจริงแต่ระบบไม่จับ
ในเดโมของคลิป มีการเปรียบเทียบโมเดล open source กับโมเดลที่แม่นขึ้น โดยผลต่างอยู่ในระดับไม่กี่เปอร์เซ็นต์ แต่เปอร์เซ็นต์เล็กๆ นี้มีผลมากในงานจริง เพราะเมื่อเอาไปต่อกับระบบสรุปประชุมหรือวิเคราะห์การสนทนา ความผิดพลาดเล็กน้อยอาจสะสมจนผลลัพธ์ปลายทางผิดสาระสำคัญ
มุมที่ควรคิดต่อคือ ถ้างานของเราเป็น internal productivity เช่นช่วยจดโน้ตประชุม อัตราผิดพลาดระดับหนึ่งอาจยอมรับได้ แต่ถ้าใช้ในงาน compliance, การเงิน, กฎหมาย หรือ medical support ความแม่นระดับนี้อาจยังไม่พอ
Step 7: จุดยากจริงไม่ใช่แค่ถอดเสียงหรือแยกคนพูด แต่คือการเอาสองอย่างมาประกบกัน
ส่วนที่มีประโยชน์มากสำหรับคนทำธุรกิจคือการอธิบายว่า แม้จะมี transcription แล้ว และมี diarization แล้ว ก็ไม่ได้แปลว่าจะรวมกันเป็นผลลัพธ์ที่ใช้งานได้โดยอัตโนมัติ
ปัญหาใหญ่คือ การจับคู่คำแต่ละคำกับคนพูดที่ถูกต้อง โดยเฉพาะเมื่อมีการพูดทับกัน หรือ timestamp ของสองระบบไม่ตรงกันเป๊ะ
ตัวอย่างที่เขาโชว์ชัดมากคือ คำบางคำตกอยู่ตรงกลางระหว่างขอบเขตของคนพูดสองคนพอดี ทำให้ตอบยากว่าควรนับว่าเป็นคำของใคร และในบางช่วงมีคนพูดสองคนพร้อมกัน แต่ระบบถอดเสียงออกมาได้เพียงชุดคำเดียว
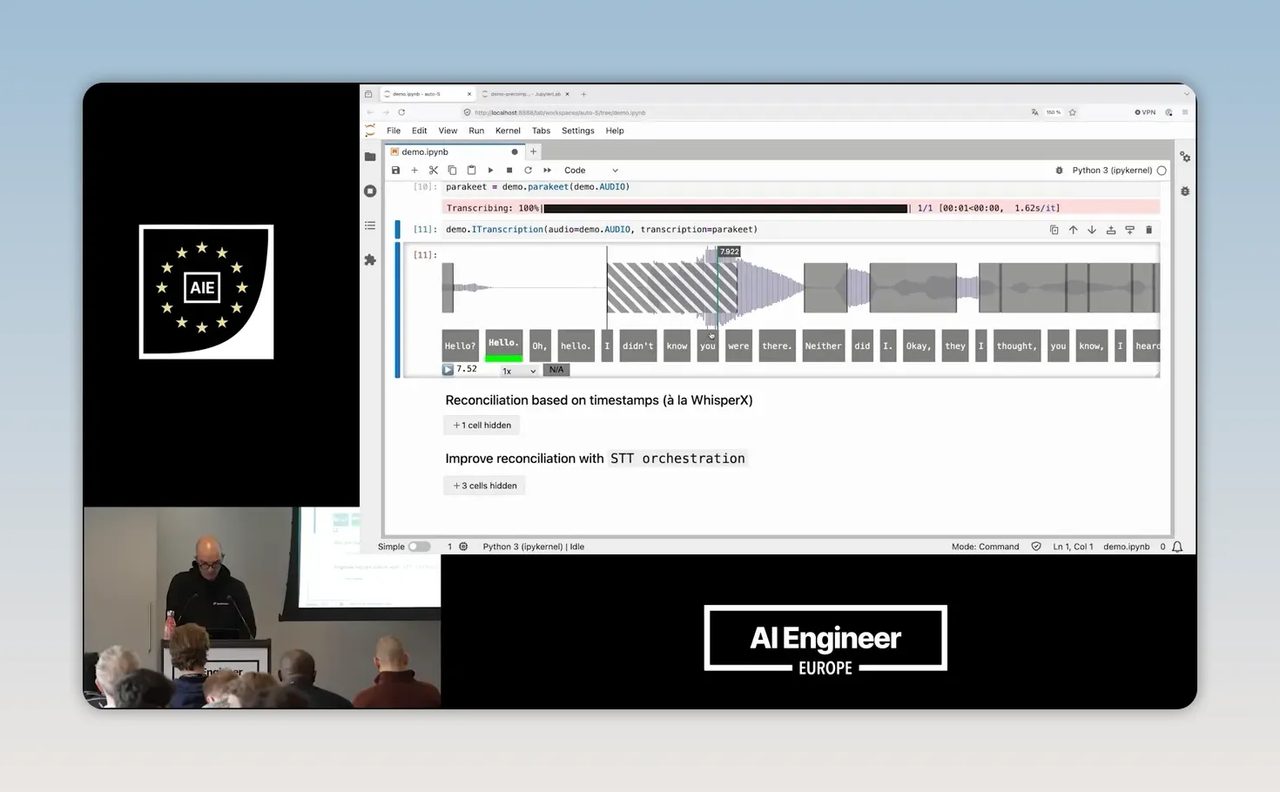
นี่คือเหตุผลที่หลายทีมลองเอา STT กับ speaker labeling มาต่อกันเองแล้วรู้สึกว่า “ก็พอได้” แต่พอใช้จริงกลับเจอปัญหาเยอะกว่าที่คิด เพราะสิ่งที่ยากที่สุดอยู่ตรงรอยต่อ
สำหรับองค์กรไทย ถ้าเรากำลังจะทำระบบสรุปประชุมอัตโนมัติหรือ call analytics ด้วยการประกอบหลาย tool เข้าด้วยกัน ควรทดสอบจุดนี้หนักเป็นพิเศษ อย่าดูแค่ demo ที่มีคนพูดทีละคนชัดๆ
Step 8: ดู use case ที่ได้ประโยชน์จริงจากการเข้าใจบทสนทนา
คลิปยก use case หลายแบบที่น่าสนใจ และถ้าแปลเป็นภาษาธุรกิจจะเห็นภาพชัดขึ้นมาก
1. การสรุปประชุมและจัด action item
ถ้าระบบรู้ว่าใครพูดอะไร ก็สามารถโยนงานต่อให้คนที่เกี่ยวข้องได้ถูกคนมากขึ้น ไม่ใช่สรุปมั่วว่าทุกประโยคเป็นของคนเดียว
2. การแปลเสียงหรือพากย์อัตโนมัติ
ถ้าระบบแยกคนพูดได้ การแปลและเปลี่ยนเสียงจะมีความต่อเนื่อง เช่น คนเดิมควรได้เสียงเดิมตลอด ไม่ใช่สลับไปมา ทำให้ประสบการณ์ฟังดีขึ้นมาก
3. Podcast intelligence
ระบบสามารถตามหาว่าแขกรับเชิญคนเดียวกันไปโผล่ในรายการไหนบ้าง หรือใช้ทำคลังความรู้จากรายการเสียงจำนวนมากได้
4. Contact center analytics
อันนี้น่าจะใกล้ธุรกิจไทยที่สุด เพราะเราสามารถวิเคราะห์สัดส่วนเวลาพูดของลูกค้ากับพนักงาน ช่วงที่ลูกค้าพูดแทรก ความถี่ของความเงียบ และรูปแบบการตอบรับได้
ถ้าจะมองแบบตรงไปตรงมา use case ที่ทำเงินได้เร็วสุดน่าจะยังเป็นฝั่ง ประชุม, คอลเซ็นเตอร์, งานขาย, และ media processing มากกว่างานวิเคราะห์อารมณ์ที่ซับซ้อนเกินไป
Step 9: ประเมินความพร้อมก่อนเอาไปใช้ในธุรกิจไทย
แม้เทคโนโลยีนี้น่าตื่นเต้น แต่ก็ยังไม่ใช่ของที่เสียบปลั๊กแล้วจบทุกเคส สิ่งที่เราควรประเมินก่อนมีดังนี้
- แหล่งเสียงของเราคุณภาพแค่ไหน
- การคุยส่วนใหญ่เป็น 1 ต่อ 1 หรือหลายคน
- มีการพูดทับกันบ่อยหรือไม่
- ต้องการความแม่นระดับไหน
- ผลลัพธ์จะถูกใช้ตัดสินใจเรื่องสำคัญหรือแค่ช่วยงานเบื้องต้น
อีกเรื่องที่ต้องคิดคือภาษาและสำเนียง คลิปนี้โฟกัสที่หลักการและเดโมภาษาอังกฤษ ซึ่งใช้ได้กับแนวคิดโดยรวม แต่เมื่อลงมาที่ภาษาไทย เราต้องทดสอบกับข้อมูลจริงของเราเอง เพราะลักษณะการสนทนาไทยมีทั้งการพูดแทรกแบบสุภาพ คำลงท้าย คำอุทาน และ code switching อังกฤษไทยที่เกิดขึ้นบ่อยในที่ทำงาน
ถ้าองค์กรไหนอยากเรียนรู้ภาพรวมด้าน speech recognition เพิ่มเติม Whisper เป็นจุดเริ่มต้นที่ดีในการเข้าใจว่าทำไม STT ถึงถูกใช้อย่างแพร่หลาย แต่ก็ต้องรู้ด้วยว่ามันยังไม่พอสำหรับการเข้าใจบทสนทนาแบบครบมิติ
Step 10: แปลงแนวคิดนี้เป็น Actionable Insights สำหรับธุรกิจ
- เริ่มจาก use case ที่คุ้มก่อน เช่น สรุปประชุมและวิเคราะห์คอลเซ็นเตอร์ เพราะเห็นผลต่อทีมงานเร็ว
- ทดสอบกับเสียงจริงขององค์กร อย่าตัดสินจาก benchmark หรือ demo เพียงอย่างเดียว
- วัดทั้ง STT และ speaker accuracy เพราะถอดคำถูกแต่จับคนผิดก็ใช้งานต่อยาก
- ดูปัญหาช่วงพูดทับกันเป็นพิเศษ เพราะมักเป็นจุดที่ข้อมูลสำคัญหล่นหาย
- อย่ารีบตีความอารมณ์เกินข้อมูล ใช้สัญญาณจากเสียงเป็นตัวช่วย ไม่ใช่คำตัดสินสุดท้าย
Step 11: Troubleshooting ปัญหาที่มักเจอเมื่อเริ่มทำตามแนวทางนี้
ปัญหา: ถอดเสียงได้ แต่สรุปว่าใครพูดผิดคน
สาเหตุ: diarization ผิด หรือจังหวะเวลาระหว่าง STT กับการแยกคนพูดไม่ตรงกัน
วิธีแก้: ทดสอบไฟล์ตัวอย่างจริงหลายแบบ, ตรวจช่วง speaker change, และประเมิน word-to-speaker alignment แยกจากความแม่นของ transcription
ปัญหา: ผลลัพธ์บนเดโมดีมาก แต่พอใช้กับประชุมจริงกลับแย่
สาเหตุ: สภาพเสียงจริงมีไมค์ไกล เสียงก้อง และพูดพร้อมกันหลายคน
วิธีแก้: เก็บข้อมูลตัวอย่างจากอุปกรณ์จริงขององค์กร และเลือก benchmark ที่ใกล้เคียงงานจริงที่สุด
ปัญหา: ระบบพลาดคำสั้นๆ เช่น คำตอบรับหรือเสียงแทรก
สาเหตุ: ช่วงเสียงสั้นและการพูดทับกันเป็นเคสยากของโมเดล
วิธีแก้: ตรวจช่วง overlap โดยเฉพาะ และอย่ามองข้ามคำสั้นเพราะมักมีผลต่อความหมายของบทสนทนา
ปัญหา: ตัวเลข word error rate ดูดี แต่ผลใช้งานจริงยังไม่น่าพอใจ
สาเหตุ: วัดแค่คุณภาพการถอดคำ แต่ไม่ได้วัดความเข้าใจบทสนทนา
วิธีแก้: เพิ่มการวัด DER, speaker attribution quality และความถูกต้องของ summary ปลายทาง
ปัญหา: ทีมคาดหวังว่าจะใช้ AI วิเคราะห์อารมณ์ได้ทันที
สาเหตุ: มองข้ามข้อจำกัดของน้ำเสียง ภาษา และสถานการณ์
วิธีแก้: เริ่มจากงานเชิงโครงสร้างก่อน เช่น ใครพูดอะไร เมื่อไหร่ แล้วค่อยขยับไปงานวิเคราะห์เชิงพฤติกรรม
Step 12: การต่อยอดที่น่าทำต่อ
- ต่อเข้ากับระบบประชุมอัตโนมัติ เพื่อสร้าง meeting summary ที่มี owner ของแต่ละงานชัดเจน
- ทำ dashboard คุณภาพการสนทนา สำหรับทีมขายหรือคอลเซ็นเตอร์ โดยดูจังหวะการพูด สัดส่วนการฟัง และการขัดจังหวะ
- สร้างคลังความรู้จากเสียง โดยค้นหาประเด็นสำคัญตามผู้พูด หัวข้อ และช่วงเวลาในไฟล์เสียงจำนวนมาก
Step 13: สรุป Checklist ทั้งหมด
- แยกให้ออกก่อนว่า transcription กับ conversation understanding คนละเรื่อง
- ประเมินว่าธุรกิจต้องรู้แค่คำพูด หรือจำเป็นต้องรู้ว่าใครพูดเมื่อไหร่
- ใช้ speaker diarization เป็นชั้นพื้นฐานก่อนทำงานวิเคราะห์ขั้นต่อไป
- ให้ความสำคัญกับ timestamp และช่วงพูดทับกัน
- อย่าเชื่อ benchmark ถ้ายังไม่รู้ว่าใช้ไมค์และสภาพแวดล้อมแบบไหน
- วัดทั้ง word accuracy และ diarization accuracy
- ทดสอบการจับคู่คำกับผู้พูดจริงในไฟล์ขององค์กร
- เริ่มจาก use case ที่คุ้ม เช่น ประชุม คอลเซ็นเตอร์ และงานขาย
- ระวังการตีความอารมณ์เกินกว่าที่ข้อมูลรองรับ
- สร้าง workflow ที่ใช้ผลลัพธ์เสียงไปต่อกับระบบสรุป วิเคราะห์ และค้นหา
สรุปแล้ว แก่นของคลิปนี้ไม่ใช่แค่เรื่องเทคนิคของ Voice AI แต่คือการเตือนว่า การเข้าใจบทสนทนาเป็นปัญหาที่ใหญ่กว่าการถอดเสียงมาก ถ้าเรากำลังจะเอา AI ไปใช้จริงในธุรกิจ เราควรเลิกถามแค่ว่า “ถอดได้ไหม” แล้วเริ่มถามใหม่ว่า “เข้าใจพอจะเอาไปตัดสินใจต่อได้หรือยัง” คำถามนี้ต่างหากที่จะทำให้ลงทุนกับ AI ได้ฉลาดขึ้น