สรุปจากคลิป ดูคลิปต้นฉบับ
From MCP to Scale: สร้าง Pipeline เก็บข้อมูลอัตโนมัติด้วย AI
ปัญหาของการดึงข้อมูลจากเว็บไม่ใช่แค่ “ดึงได้ไหม” อีกต่อไป แต่คือ “ดูแลให้มันยังดึงได้ต่อเนื่องยังไง” ต่างหาก จุดนี้คือหัวใจของคลิป From MCP to Scale: Pipelines That Build Themselves จากช่อง AI Engineer ที่เล่าให้เห็นชัดว่า AI agent กำลังขยับจากผู้ช่วยตอบคำถาม ไปเป็นระบบที่สร้าง scraper, ซ่อม scraper และรันงานเก็บข้อมูลแทนเราได้จริง
สิ่งที่น่าสนใจมากคือมุมคิดในคลิปไม่ได้หยุดแค่การ scrape เว็บ แต่มันแตะเรื่องที่เจ้าของธุรกิจและคนทำงานต้องสนใจทันที เช่น การประหยัด token, การทำ workflow ที่ไม่ต้องเฝ้าหน้าจอ, การเข้าถึงเว็บที่มี anti-bot และการเปลี่ยนงานครั้งเดียวให้กลายเป็น pipeline ที่ใช้ซ้ำได้ ในมุมของเรา นี่เป็นแนวคิดที่สำคัญกว่าตัวเครื่องมือเสียอีก เพราะมันเปลี่ยนวิธีใช้ AI จาก “ถามทีละหน้า” เป็น “สั่งให้สร้างระบบทำงานแทน”
สารบัญ
- Step 1: เปลี่ยนวิธีคิดจากให้ LLM อ่านทุกหน้า เป็นให้มันสร้าง pipeline
- Step 2: ใช้ MCP เพื่อให้ agent เข้าถึงเว็บที่ป้องกัน bot ได้
- Step 3: ให้ agent สำรวจโครงสร้างเว็บ แล้วสร้าง scraper เอง
- Step 4: ลดค่า token ด้วยการดึงเฉพาะข้อความหรือ JSON เท่าที่จำเป็น
- Step 5: ทำให้ scraper ซ่อมตัวเองได้ แทนการปลุกคนมาตีสอง
- Step 6: มอง AI agent ให้เป็นพนักงานเก็บข้อมูล ไม่ใช่แค่คนตอบคำถาม
- Step 7: เข้าใจขอบเขตกฎหมายและจริยธรรมก่อนใช้งานจริง
- Actionable Insights
- Step 8: Troubleshooting ปัญหาที่มักเจอเมื่อเริ่มทำตามแนวคิดนี้
- Step 9: การต่อยอดสำหรับธุรกิจที่อยากใช้ AI เก็บข้อมูลจริง
- Step 10: สรุป Checklist ทั้งหมด
Step 1: เปลี่ยนวิธีคิดจากให้ LLM อ่านทุกหน้า เป็นให้มันสร้าง pipeline
หลายทีมเริ่มใช้ AI กับงานเก็บข้อมูลด้วยวิธีตรงไปตรงมา คือให้ LLM เข้าเว็บ อ่าน HTML หรืออ่านข้อความในแต่ละหน้า แล้วค่อยสรุปผล วิธีนี้ใช้ได้ตอนทดลอง แต่พอจะขยายไปหลักพันหรือหลักหมื่นรายการ ค่า token จะพุ่งเร็วมาก และยิ่งเว็บซับซ้อน ผลลัพธ์ก็ยิ่งไม่นิ่ง
แกนสำคัญจากคลิปคือ ไม่ควรใช้ LLM เป็น parser ทุกครั้ง แต่ควรใช้มันเพื่อสร้าง scraper หรือ parser ขึ้นมา 1 ครั้ง แล้วให้ script นั้นทำงานซ้ำแทนในรอบถัดไป วิธีนี้ลดต้นทุนได้มหาศาล เพราะเราไม่ได้จ่ายให้ model “คิดใหม่” กับข้อมูลเดิมทุกหน้า
สำหรับธุรกิจไทย แนวคิดนี้ใช้ได้กับหลายงานมาก เช่น
- เก็บราคาคู่แข่งจาก marketplace
- ติดตามสินค้าที่กลับมามีสต๊อก
- มอนิเตอร์ประกาศอสังหาริมทรัพย์ตามเงื่อนไขที่ตั้งไว้
- เช็กโปรโมชันหรือดีลใหม่จากหลายเว็บพร้อมกัน
ถ้าเรายังใช้วิธีให้ AI อ่านทีละหน้า งานพวกนี้จะไม่คุ้มต้นทุนและขยายต่อยาก แต่ถ้าให้ AI สร้าง workflow แล้วค่อยใช้ JSON หรือข้อมูลที่จัดโครงสร้างแล้วมาวิเคราะห์ภายหลัง มันเริ่มมีความเป็นธุรกิจทันที
Step 2: ใช้ MCP เพื่อให้ agent เข้าถึงเว็บที่ป้องกัน bot ได้
อีกประเด็นสำคัญคือเว็บจำนวนมาก โดยเฉพาะ e-commerce, อสังหาฯ และเว็บที่มีมูลค่าข้อมูลสูง มักมีระบบป้องกัน bot เช่น CAPTCHA, header checking, cookie validation หรือระบบอย่าง Cloudflare และ Akamai ถ้าใช้วิธี fetch ธรรมดา AI จะโดนบล็อกเกือบทันที
สิ่งที่คลิปอธิบายคือ MCP ทำหน้าที่เป็นสะพานให้ agent เข้าถึงเว็บได้ผ่านชุดเครื่องมือที่เตรียมไว้ เช่น การดึง HTML, การดึงเฉพาะข้อความในรูป markdown, การเรียก API ที่เตรียมไว้ล่วงหน้า และการใช้ browser infrastructure จากระยะไกล
จุดนี้สำคัญมากสำหรับคนที่ไม่ใช่ developer เพราะมันลดงานเทคนิคเบื้องหลังลงเยอะ เราไม่ต้องมานั่งคิดเองทั้งหมดว่าเว็บนี้ต้องใช้ cookie อะไร ต้องตั้ง header ยังไง หรือจะแก้ challenge แบบไหน ระบบทำส่วนยากให้ แล้ว agent เอาเวลาไปโฟกัสกับการสำรวจหน้าเว็บ หา selector และสร้าง parser แทน
อย่างไรก็ดี ในมุมของเรา เรื่องนี้มีข้อจำกัดที่ต้องพูดตรงๆ คือ เครื่องมือเก่งขึ้น ไม่ได้แปลว่าใช้ได้กับทุกกรณีโดยไม่ต้องคิดเรื่องกฎหมายและเงื่อนไขการใช้งาน คลิปก็ย้ำชัดว่าควรทำกับข้อมูลสาธารณะ และต้องระวังเว็บที่อยู่หลังการล็อกอินหรือมีข้อกำหนดห้ามดึงข้อมูล
แหล่งอ้างอิงที่ควรอ่านเพิ่มคือเรื่อง bot management และ HTTP cookies เพื่อเข้าใจว่าทำไมเว็บหลายแห่งถึงกัน bot ได้ซับซ้อนขนาดนี้
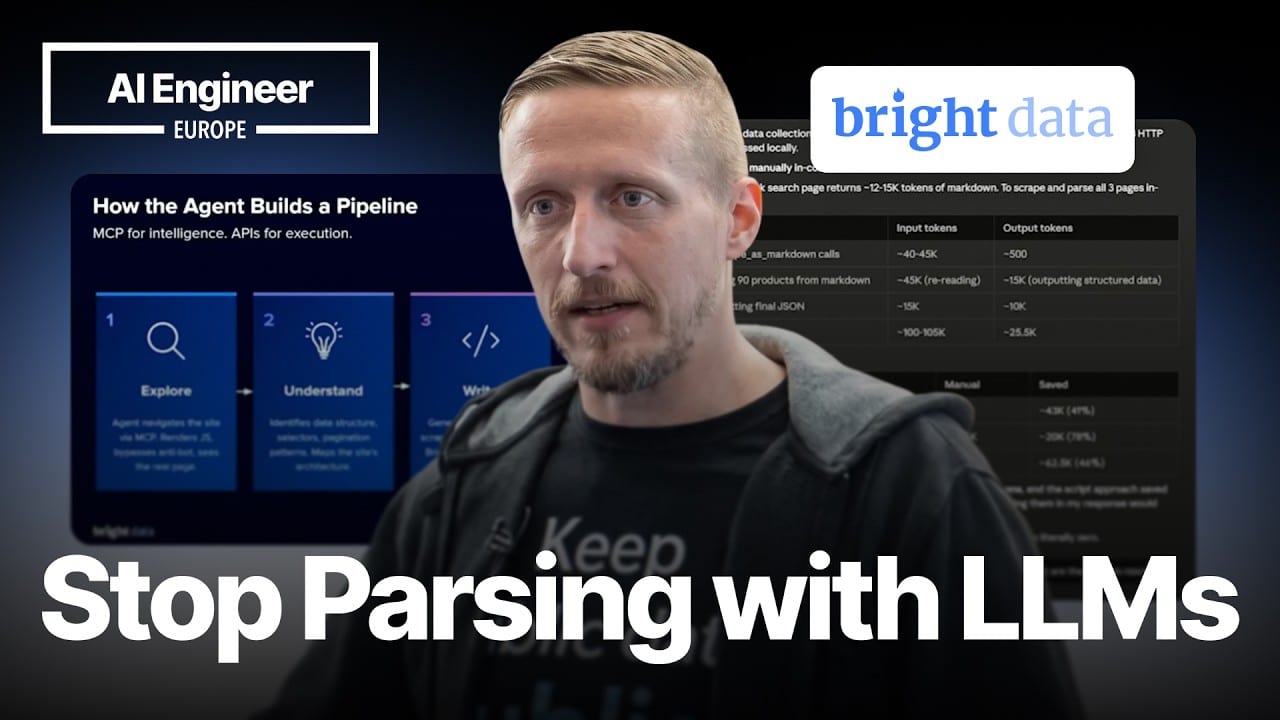
Step 3: ให้ agent สำรวจโครงสร้างเว็บ แล้วสร้าง scraper เอง
ช่วงสาธิตในคลิปน่าสนใจตรงที่ไม่ได้เขียนโค้ด scraper ด้วยมือแบบเดิม แต่เริ่มจากการสั่ง agent แบบภาษาคน เช่น ให้สร้าง scraper สำหรับค้นหาสินค้าบนเว็บหนึ่ง โดยรับ input แค่คำค้นและจำนวนหน้าที่ต้องเก็บ จากนั้น agent จะไปดึงข้อมูลที่จำเป็น หาโครงสร้างหน้า และประกอบ parser ขึ้นมาเอง
ความหมายเชิงธุรกิจของเรื่องนี้คือ เราเริ่มเห็น AI ทำหน้าที่คล้าย “พนักงานสาย operation ที่อ่านเว็บเป็น” ไม่ใช่แค่ “แชตบอต” อีกแล้ว
ถ้าเอามาใช้กับธุรกิจไทย ภาพจะออกมาประมาณนี้
- ทีมการตลาดสั่งให้ระบบเก็บชื่อสินค้า ราคา รีวิว และอันดับค้นหา
- ทีมจัดซื้อสั่งให้ระบบเช็กรายการผู้ขายในหมวดสินค้าที่สนใจทุก 30 นาที
- ทีมผู้บริหารสั่งให้ระบบตามหาโอกาสใหม่ เช่น ทำเลร้านเช่า หรือประกาศขายกิจการ
สิ่งที่เมื่อก่อนต้องอาศัยคนทำ scraping โดยเฉพาะ เริ่มถูกย่อให้เหลือการกำหนดโจทย์ให้ชัดแทน
อย่างไรก็ดี เราคิดว่าตรงนี้ยังไม่ได้แปลว่าไม่ต้องมีคนตรวจงานเลย หากเว็บเปลี่ยน layout แบบใหญ่ หรือข้อมูลที่ต้องการมีเงื่อนไขเฉพาะ เช่น ต้องแยกโปรโมชันแถม, ราคาสมาชิก, หรือสินค้าหมดชั่วคราว ก็ยังต้องมีคนช่วยกำหนดนิยามข้อมูลให้ชัด ไม่อย่างนั้น parser ที่สร้างได้อาจ “ถูกเชิงเทคนิค” แต่ “ผิดเชิงธุรกิจ”
Step 4: ลดค่า token ด้วยการดึงเฉพาะข้อความหรือ JSON เท่าที่จำเป็น
หนึ่งในจุดที่คลิปเน้นมากคือการประหยัด token เพราะต้นทุนจริงของงานประเภทนี้ไม่ได้อยู่แค่ค่าดึงเว็บ แต่อยู่ที่การให้ model อ่านข้อมูลเยอะเกินจำเป็น
แนวทางที่นำเสนอมีอยู่ 3 ชั้น
- ชั้นแรก ดึงเฉพาะข้อความของหน้าในรูป markdown แทน HTML ทั้งก้อน
- ชั้นที่สอง ใช้ agent สร้าง parser ขึ้นมา แล้วให้ script แปลงข้อมูลแทน LLM
- ชั้นที่สาม ถ้ามี API สำเร็จรูปอยู่แล้ว ให้ดึงข้อมูลเป็น JSON โดยตรง
เหตุผลที่ JSON สำคัญมาก เพราะมันเป็นข้อมูลที่จัดโครงสร้างเรียบร้อยแล้ว LLM ไม่ต้องเสีย token ไปกับ tag, script, style หรือส่วนที่ไม่เกี่ยวข้องกับงานวิเคราะห์เลย
ในเดโม มีการเปรียบเทียบให้เห็นว่าการเปลี่ยนจากการให้ model อ่านหน้าเว็บแบบเต็ม ไปใช้ scraper และ parser สามารถลดการใช้ token ได้อย่างชัดเจน แม้ตัวเลขที่ได้ในเดโมหนึ่งจะอยู่ราว 62 เปอร์เซ็นต์ แต่ประเด็นที่ควรสนใจไม่ใช่ตัวเลขเป๊ะๆ ของเว็บนั้น เป็นเรื่องของหลักคิดว่า ยิ่ง pipeline จัดข้อมูลได้เป็นระเบียบเท่าไร AI ชั้นวิเคราะห์ก็ยิ่งถูกลงเท่านั้น
นี่คือเหตุผลว่าทำไมหลายองค์กรใช้ AI แล้วรู้สึกว่าแพง ทั้งที่ปัญหาไม่ได้อยู่ที่ model แพงเสมอไป แต่อยู่ที่ workflow ยังไม่ถูกออกแบบ
Step 5: ทำให้ scraper ซ่อมตัวเองได้ แทนการปลุกคนมาตีสอง
ประโยคที่สะท้อนโลกจริงมากในคลิปคือ งานเขียน scraper อาจใช้เวลาไม่นาน แต่การดูแลมันกลับกินเวลามากกว่า โดยเฉพาะเว็บที่เปลี่ยนหน้าเรื่อยๆ หรือเป็นเว็บ React ที่องค์ประกอบขยับตลอด
สิ่งที่ถูกเสนอคือแนวคิด self-healing pipeline หรือ pipeline ที่ตรวจสอบตัวเองและซ่อมตัวเองได้เมื่อข้อมูลผิดปกติ เช่น ถ้าเดิมต้องได้ราคาสินค้าทุก record แต่รอบล่าสุดมี field หายไป agent สามารถกลับไปตรวจหน้าเว็บ หา selector ใหม่ และแก้ parser ให้กลับมาทำงานได้
สำหรับองค์กร นี่ไม่ใช่แค่เรื่องเทคนิค แต่คือเรื่องความต่อเนื่องของข้อมูล ถ้ารายงานราคาคู่แข่งหายไป 1 วัน ทีมขายอาจตัดสินใจผิด ถ้าข้อมูลสต๊อกผิด ทีมจัดซื้ออาจสั่งของพลาด ถ้าเราปล่อยให้การดึงข้อมูลเป็นงานแบบ ad hoc ระบบจะดูเหมือนฉลาด แต่จริงๆ ยังเปราะมาก
มุมที่เราเห็นด้วยมากคือ ควรตั้ง validation ไว้ตั้งแต่แรก เช่น
- สินค้าทุกชิ้นต้องมีชื่อ
- ราคาต้องเป็นตัวเลข
- จำนวนผลลัพธ์ไม่ควรลดลงผิดปกติจากรอบก่อน
- currency ต้องอยู่ในรูปแบบที่รองรับ
คลิปยกตัวอย่างว่าระบบสามารถเช็กงานเป็นรอบๆ แล้วค่อยปิดตัวถ้าทุกอย่างปกติ แนวนี้เหมาะกับธุรกิจมาก เพราะไม่ต้องใช้คนเฝ้าทุกเวลา แต่ยังมีหลักประกันว่าข้อมูลไม่พังเงียบๆ
Step 6: มอง AI agent ให้เป็นพนักงานเก็บข้อมูล ไม่ใช่แค่คนตอบคำถาม
คลิปมีตัวอย่างที่ทำให้เห็นภาพชัดว่าเทคโนโลยีแบบนี้ไม่ได้มีประโยชน์แค่ระดับองค์กรใหญ่ เช่น การตั้งระบบฟังประกาศบ้านตามพื้นที่และราคาที่สนใจ แล้วแจ้งเตือนทันทีเมื่อมีรายการใหม่ หรือการเฝ้ารอช่องว่างสำหรับการจองร้านอาหารที่เต็มตลอด
ตัวอย่างเหล่านี้สำคัญ เพราะมันสะท้อนว่า agent ที่เข้าถึงเว็บได้และรันตาม schedule ได้ มีคุณค่ากับงานส่วนตัวและงานธุรกิจขนาดเล็กพอๆ กัน
ถ้าแปลงเป็น use case แบบไทย เราอาจใช้กับงานเหล่านี้ได้
- แจ้งเตือนเมื่อคู่แข่งลดราคาในหมวดสินค้าหลัก
- ตามหาประกาศเช่าพื้นที่เปิดร้านตามเขตที่สนใจ
- มอนิเตอร์ตำแหน่งงานหรือผู้รับเหมาที่เปิดรับใหม่
- ติดตามตั๋วเดินทางหรือห้องพักในงบที่กำหนด
สิ่งที่เราชอบในมุมนี้คือ AI ไม่ได้ถูกใช้เพื่อ “ตอบแทนเรา” แต่ถูกใช้เพื่อ “เฝ้าแทนเรา” ซึ่งมีมูลค่าทางธุรกิจชัดกว่าในหลายกรณี
Step 7: เข้าใจขอบเขตกฎหมายและจริยธรรมก่อนใช้งานจริง
ช่วงท้ายของคลิปมีอีกจุดที่ไม่ควรมองข้าม คือการเก็บข้อมูลสาธารณะกับข้อมูลหลังล็อกอินไม่เหมือนกัน และการยอมรับเงื่อนไขการใช้งานของเว็บไซต์ก็มีผลตามกฎหมาย
แนวทางที่ปลอดภัยกว่าคือ
- โฟกัสที่ข้อมูลสาธารณะ
- ไม่แตะข้อมูลหลังล็อกอินหรือข้อมูลส่วนบุคคลที่อ่อนไหว
- ตรวจ terms ของเว็บก่อนเสมอ
- แยกงานวิจัยตลาดออกจากงานที่อาจละเมิดสิทธิ์หรือข้อกำหนด
สำหรับธุรกิจไทย โดยเฉพาะทีมที่อยากเอา AI ไปใช้เร็วๆ เรื่องนี้ต้องวางเป็น policy ตั้งแต่ต้น ไม่ใช่ค่อยแก้ตอนมีปัญหา เพราะเมื่อ workflow อัตโนมัติเริ่มรันต่อเนื่อง ผลกระทบก็ขยายเร็วเหมือนกัน
ถ้าต้องศึกษาเพิ่ม แนะนำให้อ่านเรื่อง data privacy และข้อกำหนดการใช้งานของแต่ละ platform ควบคู่กันไป
Actionable Insights
- เริ่มจาก 1 use case ที่วัดผลได้ เช่น เช็กราคาคู่แข่งวันละ 4 รอบ
- อย่าให้ LLM อ่านทุกหน้า ให้มันสร้าง script หรือ parser ก่อน
- เก็บข้อมูลออกมาเป็น JSON ให้เร็วที่สุด แล้วค่อยใช้ AI วิเคราะห์
- ตั้ง validation ขั้นต่ำ เช่น ชื่อสินค้า ราคา และจำนวนรายการที่คาดหวัง
- แยกชัดว่าอะไรคือข้อมูลสาธารณะ และอะไรไม่ควรแตะ
Step 8: Troubleshooting ปัญหาที่มักเจอเมื่อเริ่มทำตามแนวคิดนี้
- ปัญหา: ดึงข้อมูลได้ช่วงแรก แล้วอีกไม่กี่วันข้อมูลหาย
สาเหตุ: โครงสร้างหน้าเว็บเปลี่ยน หรือ selector ใช้ไม่ได้แล้ว
วิธีแก้: ตั้ง validation รายรอบ, ให้ agent เช็ก field ที่หาย, และเตรียม workflow สำหรับ rebuild parser อัตโนมัติ - ปัญหา: ค่า token สูงเกินคาด
สาเหตุ: ยังใช้ LLM อ่าน HTML หรือข้อความยาวเกินความจำเป็น
วิธีแก้: เปลี่ยนไปใช้ markdown เฉพาะข้อความ, ใช้ parser แยกข้อมูล, และเก็บผลลัพธ์เป็น JSON - ปัญหา: เข้าถึงบางเว็บไม่ได้ ทั้งที่ prompt ถูกต้อง
สาเหตุ: เว็บมี anti-bot, CAPTCHA, cookie checks หรือ geo restriction
วิธีแก้: ใช้ browser automation หรือ web unlocker ที่จัดการเรื่อง header, cookie และ IP ให้เหมาะกับเว็บนั้น - ปัญหา: ข้อมูลถูกเชิงเทคนิค แต่ใช้งานธุรกิจไม่ได้
สาเหตุ: นิยามข้อมูลไม่ชัด เช่น ราคาไหนคือราคาขายจริง ราคาไหนคือราคาก่อนลด
วิธีแก้: กำหนด schema ให้ชัดตั้งแต่แรก พร้อมตัวอย่างข้อมูลที่ถูกต้อง 5-10 กรณี - ปัญหา: เริ่มอัตโนมัติได้แล้ว แต่ทีมไม่มั่นใจจะใช้จริง
สาเหตุ: ไม่มี dashboard หรือรอบตรวจสอบผลลัพธ์
วิธีแก้: เริ่มจากส่งผลทางอีเมลหรือ LINE แจ้งเตือนเฉพาะสิ่งที่เปลี่ยน แล้วค่อยขยายเป็นระบบรายงาน
Step 9: การต่อยอดสำหรับธุรกิจที่อยากใช้ AI เก็บข้อมูลจริง
- ต่อยอดจาก scraper เป็นระบบแจ้งเตือนแบบ real-time เมื่อมีราคาเปลี่ยนหรือสินค้ากลับมามีสต๊อก
- เชื่อมข้อมูลที่เก็บได้เข้ากับ Google Sheets, BI dashboard หรือ CRM เพื่อให้ทีมใช้งานต่อได้ทันที
- เพิ่มชั้นวิเคราะห์หลังบ้าน เช่น ให้ AI สรุปว่าอาทิตย์นี้คู่แข่งรายไหนขยับราคาบ่อยที่สุด หรือหมวดไหนมีรีวิวดีขึ้นผิดปกติ
Step 10: สรุป Checklist ทั้งหมด
- ☐ เลือก use case ที่ต้องการเก็บข้อมูลจากเว็บให้ชัด
- ☐ ระบุ input หลัก เช่น keyword, จำนวนหน้า, พื้นที่, ช่วงราคา
- ☐ ใช้ agent เพื่อสำรวจโครงสร้างเว็บและสร้าง scraper แทนการอ่านทุกหน้า
- ☐ เลือกรูปแบบข้อมูลที่ประหยัด token เช่น markdown หรือ JSON
- ☐ ตั้ง schema ของข้อมูลที่ธุรกิจต้องใช้จริง
- ☐ เพิ่ม validation เพื่อเช็กว่าข้อมูลยังครบและถูกต้อง
- ☐ ตั้ง schedule ให้ระบบรันอัตโนมัติเป็นรอบ
- ☐ เตรียม workflow ซ่อม parser เมื่อเว็บเปลี่ยน
- ☐ ตรวจเรื่องข้อกำหนดและขอบเขตข้อมูลสาธารณะก่อนใช้งานจริง
- ☐ เชื่อมผลลัพธ์เข้ากับช่องทางที่ทีมใช้ทุกวัน เช่น ชีต รายงาน หรือระบบแจ้งเตือน
สรุปแล้ว คลิปนี้ไม่ได้ขายภาพฝันว่า AI จะทำทุกอย่างเองแบบไม่มีคนแตะ แต่ชี้ให้เห็นทิศทางที่ใช้งานได้จริงมากกว่า คือให้ AI สร้าง pipeline เก็บข้อมูลที่ใช้ซ้ำได้ ประหยัด token และดูแลตัวเองได้บางส่วน จุดเปลี่ยนไม่ได้อยู่ที่ scrape ได้หรือไม่ได้ แต่อยู่ที่เราจะออกแบบ workflow ยังไงให้ข้อมูลไหลเข้าธุรกิจได้ต่อเนื่อง
สำหรับเจ้าของธุรกิจและคนทำงาน ถ้าจะหยิบบทเรียนจากคลิปนี้ไปใช้ สิ่งที่ควรเริ่มไม่ใช่การหาว่า model ไหนเก่งที่สุด แต่คือการถามว่า “งานเก็บข้อมูลชิ้นไหนในธุรกิจที่ควรถูกเปลี่ยนจาก prompt ครั้งเดียว เป็นระบบที่รันเองทุกวัน” ถ้าตอบคำถามนี้ได้ AI จะเริ่มสร้างผลลัพธ์ที่จับต้องได้มากขึ้นทันที