
สรุปจากคลิป ดูคลิปต้นฉบับ
Evals Are Broken แต่ยังต้องใช้ ถ้าอยากให้ AI ทำงานได้จริง

ปัญหาใหญ่ของการใช้ AI ในธุรกิจไม่ใช่แค่เลือก model ไหน แต่คือเราไม่มีวิธีวัดที่ดีพอว่า AI ที่ใช้อยู่นั้น “ดีจริง” สำหรับงานของเราหรือเปล่า ตัวเลข benchmark ที่สวยมากอาจหลอกได้ง่าย ขณะเดียวกันการตัดสินจากความรู้สึกล้วนๆ ก็พาให้หลงทางได้เหมือนกัน
คลิป Evals Are Broken, Use Them Anyway จากช่อง AI Engineer โดย Ara Khan จาก Cline พูดประเด็นนี้ได้คมมาก แก่นของคลิปคือ Evals มีปัญหาเยอะ แต่ถ้าไม่ใช้เลย เราก็แทบไม่มีระบบในการปรับปรุง AI ให้ดีขึ้น บทความนี้สรุปพร้อมวิเคราะห์ต่อในมุมที่เจ้าของธุรกิจและคนทำงานเอาไปใช้ได้จริง โดยเฉพาะถ้าเรากำลังทำ workflow ที่มี AI เข้ามาช่วยงานขาย งานบริการลูกค้า งานเอกสาร หรือ agent ที่ต้องลงมือทำหลายขั้นตอน
สารบัญ
- Step 1: เริ่มจากเข้าใจก่อนว่า Evals พังตรงไหน
- Step 2: ใช้ 3 กฎตีความ benchmark ก่อนตัดสินใจเปลี่ยน model
- Step 3: แยกให้ออกว่า eval เป็นทั้งปัญหาเชิงวิศวกรรมและเชิงความคิด
- Step 4: ถ้าไม่มี eval ที่ใช่ จงสร้างของตัวเองจากงานจริง
- Step 5: เข้าใจความต่างระหว่าง single-turn eval กับ agent eval
- Step 6: ใช้ benchmark ที่ใกล้งานจริง และรันใน environment ที่ควบคุมได้
- Step 7: หลังรัน eval แล้ว อย่าดูแค่คะแนนรวม ให้ไล่สาเหตุของความล้มเหลว
- Step 8: วัดให้ครบ 3 ชั้น คือ model, harness และโจทย์
- Step 9: ปรับปรุงตาม 3 โซน และระวังการ overfit
- Step 10: สุดท้ายต้องผ่านทั้ง score และ vibe check
- Step 11: Actionable Insights สำหรับเจ้าของธุรกิจและคนทำงาน
- Step 12: Troubleshooting ปัญหาที่มักเจอเวลาทำ evals
- Step 13: การต่อยอด
- Step 14: สรุป Checklist ทั้งหมด
Step 1: เริ่มจากเข้าใจก่อนว่า Evals พังตรงไหน
Ara Khan เริ่มจากการชี้ว่าคนส่วนใหญ่เข้าใจ Evals ผิดอยู่สองฝั่ง และทั้งสองฝั่งก็อันตรายพอๆ กัน
- ฝั่งแรกคือเชื่อตัวเลขมากเกินไป เห็นคะแนนบน dashboard หรือ benchmark แล้วสรุปทันทีว่า model A พอๆ กับ model B หรือดีกว่าแบบขาดลอย
- อีกฝั่งคือไม่เชื่อตัวเลขเลย ใช้แค่ความรู้สึกว่าอันไหน “ถูกจริต” หรือ “คุยแล้วลื่น” แล้วตัดสินทั้งหมดจากประสบการณ์ส่วนตัว
สิ่งที่น่าสนใจคือเขาไม่ได้บอกให้ทิ้ง benchmark และไม่ได้บอกให้เชื่อคะแนนเต็มร้อย เขาบอกว่าความจริงอยู่ตรงกลาง Evals ไม่ใช่คำตอบทั้งหมด แต่ก็ไม่ใช่ของไร้ค่า
สำหรับธุรกิจไทย นี่เป็นประเด็นที่สำคัญมาก เพราะหลายทีมมักพลาดอยู่สองแบบชัดเจน แบบแรกคือเห็นโพสต์รีวิว model ใหม่แล้วรีบย้ายทั้งระบบ แบบที่สองคือเลือกจากความรู้สึกของคนในทีมไม่กี่คน เช่น “อันนี้ตอบสุภาพกว่า” หรือ “อันนี้เขียนเก่งกว่า” แต่ไม่มีหลักฐานว่ามันช่วยให้ปิดการขายเร็วขึ้น ลดเวลาทำงาน หรือแก้ปัญหาลูกค้าได้ดีขึ้นจริง

มุมมองที่เราควรเก็บไว้คือ ตัวเลขเป็นเพียงสัญญาณ ไม่ใช่ข้อสรุป และ ความรู้สึกเป็นเพียง feedback ไม่ใช่ระบบวัดผล
Step 2: ใช้ 3 กฎตีความ benchmark ก่อนตัดสินใจเปลี่ยน model
ในคลิปมี heuristic หรือกฎง่ายๆ 3 ข้อที่เอาไปใช้ได้ทันที แม้ไม่ได้เป็น developer ก็ใช้กรอบคิดนี้ได้
1) อย่าเพิ่งเชื่อตัวเลขจากผู้ผลิต model ตรงๆ
คะแนนที่ผู้ให้บริการ AI ปล่อยออกมามักเป็นการวัดแบบเฉพาะสนาม บางครั้งถูกออกแบบมาให้เด่นในโจทย์บางประเภท แต่ไม่สะท้อนงานจริงทั้งหมด นี่ไม่ใช่การกล่าวหาว่าตัวเลขปลอมทุกครั้ง แต่เป็นการเตือนว่าอย่าตีความเกินสิ่งที่มันวัด
ในโลกธุรกิจ ถ้าเราเห็นว่า model ใหม่ได้คะแนนสูงด้าน reasoning ไม่ได้แปลว่าเอามาใช้ตอบแชตลูกค้าแล้วจะดีขึ้นทันที เพราะงานบริการจริงมีเรื่องน้ำเสียง ความต่อเนื่องของข้อมูล นโยบายบริษัท และการเชื่อมกับระบบภายในเข้ามาเกี่ยวด้วย
2) ตามให้ทัน แต่ไม่ต้องเป็นคนลองก่อนสุด
อีกประเด็นที่คมมากคือ model frontier เปลี่ยนเร็วมากจนทีมส่วนใหญ่ไม่จำเป็นต้องไล่ทันทุกอัน การรีบย้ายทันทีมีต้นทุนซ่อนอยู่เยอะ เช่น prompt เดิมใช้ไม่ได้ workflow เดิมพัง response time เปลี่ยน หรือค่าใช้จ่ายบาน
คำแนะนำที่ใช้งานได้คือ รอให้ตลาดทดสอบสักระยะ ให้คนอื่นเจอปัญหาก่อน แล้วค่อยเปลี่ยนเมื่อเห็นว่า model นั้นยืนระยะได้จริง วิธีนี้เหมาะกับเจ้าของธุรกิจมากกว่าการวิ่งตามกระแสทุกสัปดาห์
3) มองหา evals ที่ใหม่และตรงงานมากพอ
Ara ยกตัวอย่างว่า benchmark บางชุดเก่าจนไม่สะท้อนความสามารถของ model รุ่นล่าสุดแล้ว นี่เป็นเรื่องที่หลายทีมมองข้าม เพราะชื่อ benchmark ดังมากจนคิดว่ายังใช้ได้เสมอ
บทเรียนสำคัญคือ ถ้าโจทย์เปลี่ยนเร็ว benchmark ก็ต้องเปลี่ยนเร็วเหมือนกัน โดยเฉพาะงานที่เป็น agent หรือ workflow หลายขั้นตอน
ถ้าเราเป็นธุรกิจไทย ให้ถามตัวเองแบบนี้
- eval นี้วัดงานที่คล้ายงานของเราจริงหรือไม่
- โจทย์ยังทันกับวิธีใช้ AI ล่าสุดหรือไม่
- คะแนนนี้ทำนายผลลัพธ์ทางธุรกิจได้แค่ไหน
ถ้าตอบไม่ได้ คะแนนนั้นก็มีประโยชน์จำกัด
Step 3: แยกให้ออกว่า eval เป็นทั้งปัญหาเชิงวิศวกรรมและเชิงความคิด
หนึ่งในประโยคที่ทรงพลังที่สุดในคลิปคือการมองว่า eval ไม่ใช่แค่เรื่องเทคนิค แต่เป็นเรื่องของวิธีคิดด้วย
เหตุผลคือ ในงานจริง เราไม่สามารถกำหนดเส้นทางความผิดพลาดทั้งหมดล่วงหน้าได้ โดยเฉพาะงาน agent ที่ต้องอ่านไฟล์ ค้นเอกสาร รันคำสั่ง ตัดสินใจหลายรอบ และอาจพังได้หลายจุดมาก การประเมินจึงไม่มีทางสมบูรณ์แบบ
นี่แปลว่าเป้าหมายของ eval ไม่ใช่การจำลองโลกจริงให้ครบ 100 เปอร์เซ็นต์ แต่คือการสร้าง ภาพแทนที่ใกล้พอ เพื่อช่วยให้เราปรับปรุงระบบได้อย่างมีทิศทาง
ถ้าแปลเป็นภาษาธุรกิจ เช่น เราทำ AI ช่วยตอบแชตขาย การวัดผลไม่จำเป็นต้องจำลองลูกค้าทุกประเภทบนโลก แต่ควรครอบคลุมเคสหลักที่เจอบ่อย เช่น
- ลูกค้าถามราคาหลายแพ็กเกจพร้อมกัน
- ลูกค้าลังเลและเปรียบเทียบคู่แข่ง
- ลูกค้าต้องการข้อมูลที่เชื่อมกับสต๊อกหรือเงื่อนไขจัดส่ง
- ลูกค้าใช้ภาษาพูด ไม่พิมพ์เป็นระเบียบ
ถ้า eval สะท้อนเคสพวกนี้ได้พอประมาณ เราก็เริ่มปรับปรุงระบบอย่างมีหลักได้แล้ว
Step 4: ถ้าไม่มี eval ที่ใช่ จงสร้างของตัวเองจากงานจริง
Cline เคยอยู่ในจุดที่ benchmark ที่มีอยู่ยังหยาบเกินไป และไม่ได้วัดสิ่งที่ผู้ใช้ทำจริงในงานเขียนโค้ด ทีมจึงตัดสินใจสร้าง eval ของตัวเองจากข้อมูลปัญหาจริงที่ผู้ใช้เจอ แล้วคัด แยก และทำความสะอาดจนกลายเป็นชุดโจทย์ที่ใช้วัดได้
แม้กรณีในคลิปจะเป็น coding agent แต่แนวคิดนี้ใช้กับธุรกิจทั่วไปได้ดีมาก เพราะหลายองค์กรมัวแต่ถามว่า “ใช้ benchmark ไหนดี” ทั้งที่คำตอบอาจเป็น “ยังไม่มี benchmark ไหนตรงพอ”
วิธีคิดที่นำมาใช้ได้คือ
- รวบรวมงานจริงที่ AI ต้องช่วยทำ
- เลือกเฉพาะเคสที่สำคัญต่อธุรกิจ
- ทำโจทย์ให้วัดซ้ำได้
- กำหนดเกณฑ์ผ่านและไม่ผ่านให้ชัด
ตัวอย่างสำหรับธุรกิจไทย
- ทีมขาย สร้างชุดคำถามลูกค้า 50 แบบ แล้ววัดว่า AI สรุปข้อเสนอได้ครบหรือไม่
- ทีมบริการลูกค้า สร้างเคสร้องเรียนจริง แล้ววัดว่า AI ตอบถูกนโยบายหรือไม่
- ทีม HR สร้างชุด resume และ job description แล้ววัดว่า AI คัดกรองได้สอดคล้องกับเกณฑ์หรือไม่
- ทีมบัญชีหรือแอดมิน สร้างเอกสารหลายรูปแบบ แล้ววัดว่า AI ดึงข้อมูลสำคัญได้ครบไหม
นี่คือจุดที่หลายองค์กรได้ผลลัพธ์ต่างกันมหาศาล แม้จะใช้ model เดียวกัน เพราะสิ่งที่ต่างจริงๆ ไม่ใช่ model อย่างเดียว แต่คือวิธีออกแบบโจทย์และวิธีวัด
Step 5: เข้าใจความต่างระหว่าง single-turn eval กับ agent eval
Ara อธิบายไว้ชัดว่าโจทย์แบบ single-turn ประเมินง่ายกว่า เพราะมีคำตอบค่อนข้างชัด เช่นถามหนึ่งครั้งแล้วตอบหนึ่งครั้ง ถูกหรือผิดค่อนข้างตัดสินได้
แต่เมื่อเป็น agent ทุกอย่างยากขึ้นมาก เพราะระบบอาจต้องทำหลายอย่างต่อเนื่อง เช่น อ่านไฟล์ ค้นเอกสาร ติดตั้ง environment ทดลองแก้ รัน test แล้วค่อยสรุปผล ปัญหาคือ AI อาจได้ผลลัพธ์สุดท้ายที่ดูเหมือนถูก แต่ระหว่างทางอาจทำพังอย่างอื่น หรือใช้เวลาเกินจริง หรือวนลูปเปลือง token
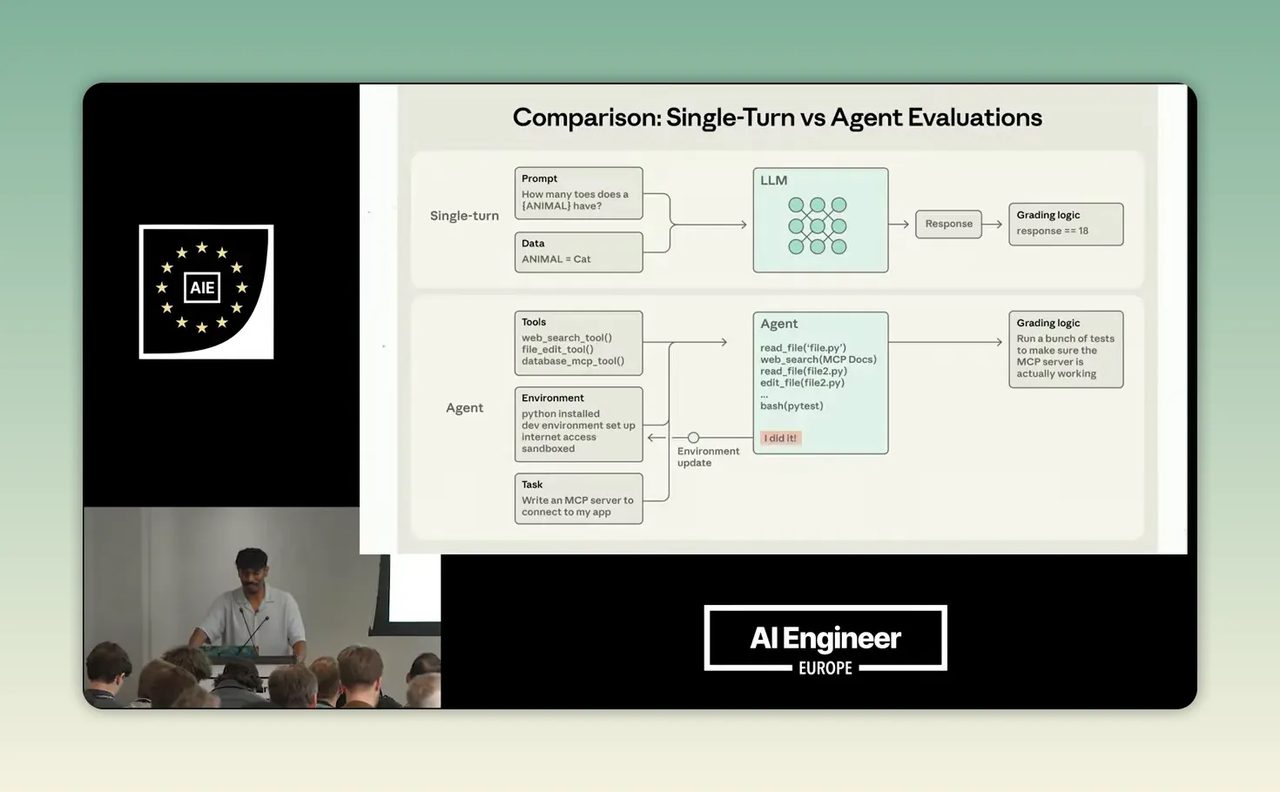
นี่เป็นบทเรียนสำคัญสำหรับคนทำธุรกิจที่กำลังใช้ AI agent เช่น agent ช่วยตอบอีเมล ช่วยทำเอกสาร หรือช่วยคัดกรอง lead เพราะการวัดแค่คำตอบสุดท้ายไม่พอ ควรวัดอย่างน้อย 3 มิติ
- คุณภาพผลลัพธ์ ได้คำตอบที่ใช้ได้จริงหรือไม่
- กระบวนการ ใช้ขั้นตอนสมเหตุสมผลไหม
- ผลกระทบข้างเคียง ทำให้ข้อมูลผิด หรืองานส่วนอื่นพังหรือเปล่า
แนวคิดนี้ใกล้กับสิ่งที่หลายองค์กรใช้ใน quality assurance และ operations อยู่แล้ว จึงไม่ใช่เรื่องใหม่ เพียงแต่ย้ายมาใช้กับ AI ให้จริงจังขึ้น
Step 6: ใช้ benchmark ที่ใกล้งานจริง และรันใน environment ที่ควบคุมได้
ในคลิปมีการพูดถึง Terminal Bench ซึ่งเป็น benchmark สำหรับ AI agents ที่ทำงานใน terminal environment จุดเด่นคือโจทย์ไม่ใช่คำถามสั้นๆ แต่เป็นปัญหาที่ใกล้โลกจริงมากขึ้น เช่น race condition ปัญหาฐานข้อมูล หรือปัญหา infra ที่ต้องไล่หลายขั้นตอน
สาระสำคัญไม่ได้อยู่ที่ชื่อ Terminal Bench อย่างเดียว แต่อยู่ที่หลักการว่า การประเมิน AI ต้องรันใน environment ที่แยกขาดและควบคุมได้ เพื่อให้รู้ว่าแต่ละรอบเทียบกันได้จริง
สำหรับธุรกิจนอกสายเทคนิค หลักการนี้แปลได้ง่ายมาก เช่น ถ้าเราจะเทียบ AI ช่วยตอบลูกค้า อย่าทดสอบคนละวัน คนละข้อมูล คนละ prompt แล้วเอาผลมาเทียบกัน ควรล็อกเงื่อนไขให้ใกล้กันที่สุด
- ใช้ชุดคำถามเดียวกัน
- ใช้ข้อมูลอ้างอิงชุดเดียวกัน
- ใช้เกณฑ์ตัดสินแบบเดียวกัน
- บันทึกผลลัพธ์และเหตุผลที่ให้คะแนน
ถ้าทำได้เท่านี้ เราก็เริ่มมี “สนามทดสอบ” ขององค์กรตัวเองแล้ว
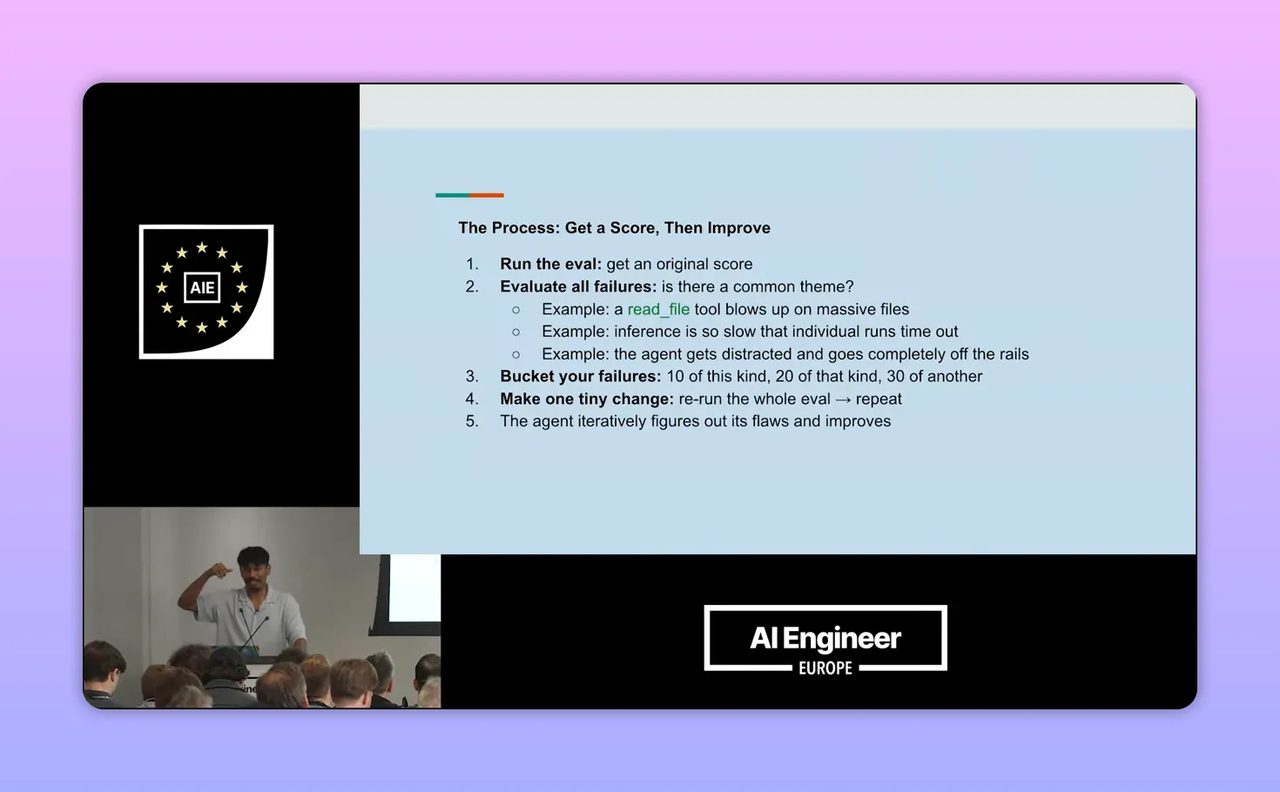
Step 7: หลังรัน eval แล้ว อย่าดูแค่คะแนนรวม ให้ไล่สาเหตุของความล้มเหลว
อีกช่วงที่มีประโยชน์มากคือแนวคิด portfolio allocate the failures หรือการแยกประเภทความล้มเหลวหลังทดสอบ แทนที่จะดูแค่ว่าได้ 43 เปอร์เซ็นต์ หรือ 60 เปอร์เซ็นต์
เขาเสนอให้ใช้ระบบอีกชั้นหนึ่งเข้าไปไล่ trace ของงานที่ล้มเหลว แล้วจัดหมวดว่าพังเพราะอะไร เช่น ไม่รัน test, tool พัง, timeout สั้นไป, prompt ไม่เหมาะ หรือทรัพยากรเครื่องไม่พอ
สำหรับธุรกิจ นี่คือวิธีเปลี่ยนคะแนนให้กลายเป็นแผนปรับปรุง ตัวอย่างเช่น ถ้า AI ตอบแชตขายพลาด 30 เคส เราไม่ควรสรุปแค่ว่า model ไม่ดี แต่ควรแยกให้ออกว่า
- พลาดเพราะไม่มีข้อมูลสินค้าอัปเดต
- พลาดเพราะ prompt สั่งไม่ชัด
- พลาดเพราะ policy ห้ามตอบบางอย่างแต่ AI ไม่เข้าใจ
- พลาดเพราะ context ยาวเกินจนลืมต้นเรื่อง
- พลาดเพราะระบบเชื่อม CRM ไม่ครบ
ตรงนี้คือจุดที่องค์กรเริ่ม “โต” ในการใช้ AI เพราะเลิกโทษ model อย่างเดียว แล้วหันมามองระบบทั้งชุด
Step 8: วัดให้ครบ 3 ชั้น คือ model, harness และโจทย์
ในคลิปมีกรอบคิดที่เอาไปใช้ได้กว้างมาก เขาบอกว่าการทดสอบจริงๆ กำลังวัด 3 อย่างพร้อมกัน
- Model ตัว model ดีแค่ไหน
- Harness ระบบครอบที่ใช้ model นั้นดีแค่ไหน เช่น prompt, tools, orchestration, timeout, memory
- Problems โจทย์ที่ใช้วัดมันมีคุณภาพหรือไม่
นี่คือเหตุผลที่ model ดีมากตัวหนึ่งอาจทำงานไม่ดีในองค์กรหนึ่ง แต่เวิร์กมากในอีกองค์กรหนึ่ง เพราะ harness ต่างกัน
ถ้าเอามาใช้กับธุรกิจไทย คำว่า harness อาจมองเป็นชุดการตั้งค่าการใช้งานทั้งหมด เช่น
- system prompt
- ลำดับ workflow
- ฐานความรู้ที่ป้อนให้
- สิทธิ์เข้าถึงข้อมูล
- เวลารอ response
- รูปแบบการส่งต่อให้มนุษย์เมื่อ AI ไม่มั่นใจ
หลายครั้งสิ่งที่ทำให้ AI ใช้งานไม่ได้จริงไม่ใช่ model แย่ แต่เป็น harness ที่ออกแบบไม่ดี
Step 9: ปรับปรุงตาม 3 โซน และระวังการ overfit
Ara แบ่งการปรับปรุงเป็น 3 โซน ซึ่งเป็นกรอบที่เอาไปใช้ได้ดีมาก

Zone 1: จุดพังชัดๆ
เช่น bug ตรงๆ ระบบ crash, timeout สั้นเกิน, memory ไม่พอ, rate limit พัง จุดนี้ต้องรีบแก้ก่อน เพราะเป็นของที่ทำให้คะแนนตกแบบไม่จำเป็น
Zone 2: การปรับแบบละเอียด
นี่คือโซนที่สำคัญที่สุด เช่น prompt แบบไหนเหมาะกับ model ตระกูลไหน การสั่งให้คิดมากขึ้นช่วยจริงไหม หรือทำให้หลงทางกว่าเดิม การตั้งค่าที่เหมาะกับ Anthropic อาจใช้กับ Gemini หรือ Codex ไม่ได้
ในคำอธิบายคลิปยังชี้ชัดว่า Cline เริ่มต้นที่ 43 เปอร์เซ็นต์บน Terminal Bench และสิ่งที่ช่วยให้ดีขึ้นไม่ใช่แค่เปลี่ยนไปใช้ model ที่เก่งกว่า แต่เป็นการปรับ CPU, memory, timeout และเทคนิค prompt ที่ตรงกับแต่ละ model family
Zone 3: เขตอันตราย
คือการไล่คะแนนจนเริ่มโกง benchmark หรือปรับให้ชนะโจทย์ชุดเดิม แต่ไม่ได้ดีขึ้นในงานจริง อันนี้อันตรายมากสำหรับธุรกิจ เพราะจะได้ dashboard สวยแต่ของจริงไม่ดีขึ้น
ถ้าเราสร้าง AI สำหรับองค์กร โซน 3 มักมาในรูปแบบนี้
- สอน AI ให้จำคำตอบเฉพาะชุดทดสอบ
- ลดความหลากหลายของเคสเพื่อให้คะแนนดี
- เลือกเฉพาะตัวอย่างง่ายๆ มาอวดผล
- วัดเฉพาะ metric ที่ตัวเองชนะ
ถ้าเจอแบบนี้ ต้องหยุดและกลับมาถามว่า “งานจริงดีขึ้นหรือยัง”
Step 10: สุดท้ายต้องผ่านทั้ง score และ vibe check
ตอนจบของคลิปสรุปได้ดีมากว่า เราไม่ควรพอใจกับคะแนนเพียงอย่างเดียว และก็ไม่ควรใช้ความรู้สึกล้วนๆ ต้องมีทั้งสองอย่าง
พูดอีกแบบคือ AI ที่ดีสำหรับธุรกิจต้องผ่าน 2 ด่านพร้อมกัน
- มีคะแนนที่พอเชื่อถือได้ แปลว่ามีระบบวัดผลและดีขึ้นอย่างติดตามได้
- ใช้งานแล้วรู้สึกดีจริง แปลว่าคนในทีมยอมรับ เอาไปใช้ต่อ และไม่สร้าง friction เกินจำเป็น
เรามองว่านี่คือจุดสมดุลที่องค์กรส่วนใหญ่ควรยึดไว้ เพราะถ้ามีแต่ score ระบบอาจแข็งแต่ใช้งานจริงไม่รอด ถ้ามีแต่ vibe ระบบอาจดูดีแค่ช่วงทดลองแต่ขยายไม่ได้
ถ้าอยากอ่านเพิ่มเติมเรื่องการประเมินระบบ AI ในเชิงใช้งานจริง สามารถดูแนวคิดใกล้เคียงได้จาก HELM และเอกสารจาก OpenAI Evals เพื่อเห็นภาพว่าทำไมการวัด AI จึงต้องออกแบบให้ตรงโจทย์มากกว่าการพึ่งคะแนนกว้างๆ
Step 11: Actionable Insights สำหรับเจ้าของธุรกิจและคนทำงาน
- เริ่มจากการเก็บเคสงานจริง 20 ถึง 50 เคสก่อน ไม่ต้องรอระบบสมบูรณ์
- อย่าตัดสิน AI จาก demo หรือคะแนน benchmark เพียงอย่างเดียว
- ทุกครั้งที่ AI พลาด ให้แยกสาเหตุว่าเป็นปัญหา model, prompt, ข้อมูล หรือ workflow
- ก่อนเปลี่ยน model ใหม่ ให้ทดสอบในชุดงานเดิมเสมอ เพื่อเทียบผลแบบยุติธรรม
- ตั้ง KPI ที่โยงกับงานจริง เช่น เวลาที่ลดลง อัตราปิดงาน ความถูกต้อง หรืออัตราส่งต่อให้มนุษย์
Step 12: Troubleshooting ปัญหาที่มักเจอเวลาทำ evals
ปัญหา: คะแนนดี แต่คนในทีมบอกว่าใช้งานไม่ได้
สาเหตุ: eval วัดไม่ตรงงานจริง หรือวัดแค่ผลลัพธ์ปลายทาง
วิธีแก้: เพิ่มเคสจริงจากหน้างาน วัดทั้งคุณภาพ ขั้นตอน และผลข้างเคียง
ปัญหา: เปลี่ยน model แล้วผลลัพธ์แย่ลงทั้งที่ benchmark ดีกว่า
สาเหตุ: harness เดิมไม่เหมาะกับ model ใหม่
วิธีแก้: ปรับ prompt, timeout, workflow, รูปแบบ context ให้เหมาะกับ model family นั้นก่อนสรุปผล
ปัญหา: ทีมเถียงกันไม่จบว่า AI ตัวไหนดีกว่า
สาเหตุ: ไม่มีสนามทดสอบร่วมกัน
วิธีแก้: สร้างชุดโจทย์เดียวกัน กติกาเดียวกัน และตัดสินจากทั้ง score กับ feedback ใช้งานจริง
ปัญหา: คะแนนดีขึ้นช่วงแรกแล้วตัน
สาเหตุ: แก้จุด obvious หมดแล้ว เหลือแต่ nuance improvements
วิธีแก้: วิเคราะห์ failure traces เพิ่ม แยกสาเหตุละเอียดขึ้น และทดลองปรับทีละตัวแปร
ปัญหา: คะแนนสูงขึ้นเรื่อยๆ แต่ผลธุรกิจไม่ดีขึ้น
สาเหตุ: เริ่ม overfit กับ benchmark
วิธีแก้: เติมเคสใหม่สม่ำเสมอ และตรวจผลกับงานจริงทุกระยะ
Step 13: การต่อยอด
- สร้าง AI scorecard ขององค์กรเอง แยกตาม use case เช่น sales, support, back office
- ทำ human-in-the-loop eval เพื่อดูว่าเมื่อ AI พลาด คนในทีมแก้งานต่อได้ง่ายแค่ไหน
- เชื่อม eval เข้ากับการตัดสินใจลงทุน เช่น model ไหนคุ้มสุดเมื่อเทียบค่าใช้จ่าย เวลา และคุณภาพ
Step 14: สรุป Checklist ทั้งหมด
- ☐ เลิกเชื่อทั้งฝั่งตัวเลขล้วนๆ และความรู้สึกล้วนๆ
- ☐ ใช้ 3 กฎตีความ benchmark ก่อนเปลี่ยน model
- ☐ ยอมรับว่า eval เป็นการประมาณ ไม่ใช่ภาพจริงทั้งหมด
- ☐ รวบรวมเคสงานจริงขององค์กรเพื่อสร้าง eval ของตัวเอง
- ☐ แยก single-turn task ออกจากงานแบบ agent
- ☐ ทดสอบในเงื่อนไขที่ควบคุมได้และเทียบกันได้
- ☐ หลังรัน eval ให้ไล่สาเหตุของ failure ไม่ใช่ดูแค่คะแนนรวม
- ☐ วิเคราะห์ให้ครบทั้ง model, harness และโจทย์
- ☐ ปรับปรุงตาม 3 โซน และระวัง overfitting
- ☐ ใช้ทั้ง score และ vibe check ก่อนตัดสินว่า AI พร้อมใช้งานจริง
สรุปให้สั้นที่สุด คลิปนี้ไม่ได้บอกว่า benchmark สำคัญที่สุด และไม่ได้บอกให้เชื่อความรู้สึกล้วนๆ สิ่งที่ Ara Khan พยายามย้ำคือ Evals are broken, use them anyway เพราะถึงมันไม่สมบูรณ์ แต่มันยังดีกว่าการใช้ AI แบบไม่มีระบบวัดอะไรเลย สำหรับเจ้าของธุรกิจและคนทำงาน นี่คือแนวคิดที่นำไปใช้ได้ทันที ถ้าเราอยากให้ AI กลายเป็นเครื่องมือทำงานจริง ไม่ใช่แค่ของใหม่ที่ดูน่าตื่นเต้นช่วงสั้นๆ