
สรุปจากคลิป ดูคลิปต้นฉบับ
Deploy LLM endpoint บน RunPod ใน 5 นาที แบบที่ธุรกิจเอาไปใช้ต่อได้

ปัญหาของหลายทีมที่อยากใช้ AI ไม่ได้เริ่มจากการไม่มีไอเดีย แต่มักเริ่มจากคำถามที่น่าปวดหัวกว่า คือจะเอา model ไปวางที่ไหน ใช้ GPU แบบไหน จ่ายเงินยังไง และจะไม่เผาเวลาทีมไปกับงาน infrastructure ได้หรือเปล่า คลิปจากช่อง AI Engineer ที่ให้ Audry Hsu จาก RunPod มาเล่าและสาธิตการ deploy LLM endpoint ภายในไม่กี่นาที จึงน่าสนใจมาก เพราะมันแตะโจทย์จริงของคนที่อยากเอา AI ไปใช้ในงาน ไม่ใช่แค่ทดลองเล่น
สิ่งที่น่าสนใจไม่ได้มีแค่ความเร็วในการ deploy แต่คือแนวคิดเบื้องหลังว่า platform แบบ RunPod ช่วยลดภาระอะไรบ้าง เหมาะกับ use case แบบไหน และถ้าเอามาคิดต่อในมุมเจ้าของธุรกิจไทย เราควรดูอะไรให้มากกว่าคำว่า “เปิดใช้งานได้เร็ว” เพราะเร็วอย่างเดียวไม่พอ ถ้าต้นทุนคุมไม่ได้ latency ไม่นิ่ง หรือเลือก architecture ผิดตั้งแต่ต้น
คลิปนี้มาจากช่วงบรรยายของ AI Engineer และแก่นสำคัญคือการใช้ RunPod เพื่อสร้าง LLM API endpoint แบบ serverless ให้พร้อมใช้งานระดับ production ได้เร็วมาก
สารบัญ
- Step 1: เข้าใจก่อนว่า RunPod แก้ปัญหาอะไร
- Step 2: ประเมินว่า workload ของเราเหมาะกับ Pods, Serverless หรือ Clusters
- Step 3: ใช้ Hub เพื่อลดเวลาเริ่มต้น
- Step 4: เลือก model และตั้งค่าที่กระทบต้นทุนจริง
- Step 5: ตั้งค่า serverless ให้บาลานซ์ระหว่างความเร็วกับค่าใช้จ่าย
- Step 6: ยอมรับความจริงเรื่อง cold start ก่อนเอาไปใช้กับลูกค้า
- Step 7: ใช้ endpoint และ telemetry เพื่อตัดสินใจแบบคนทำธุรกิจ
- Step 8: แปลบทเรียนจากเดโมให้เป็นภาพใช้งานในธุรกิจไทย
- Actionable Insights
- Troubleshooting
- การต่อยอด
- สรุป Checklist ทั้งหมด
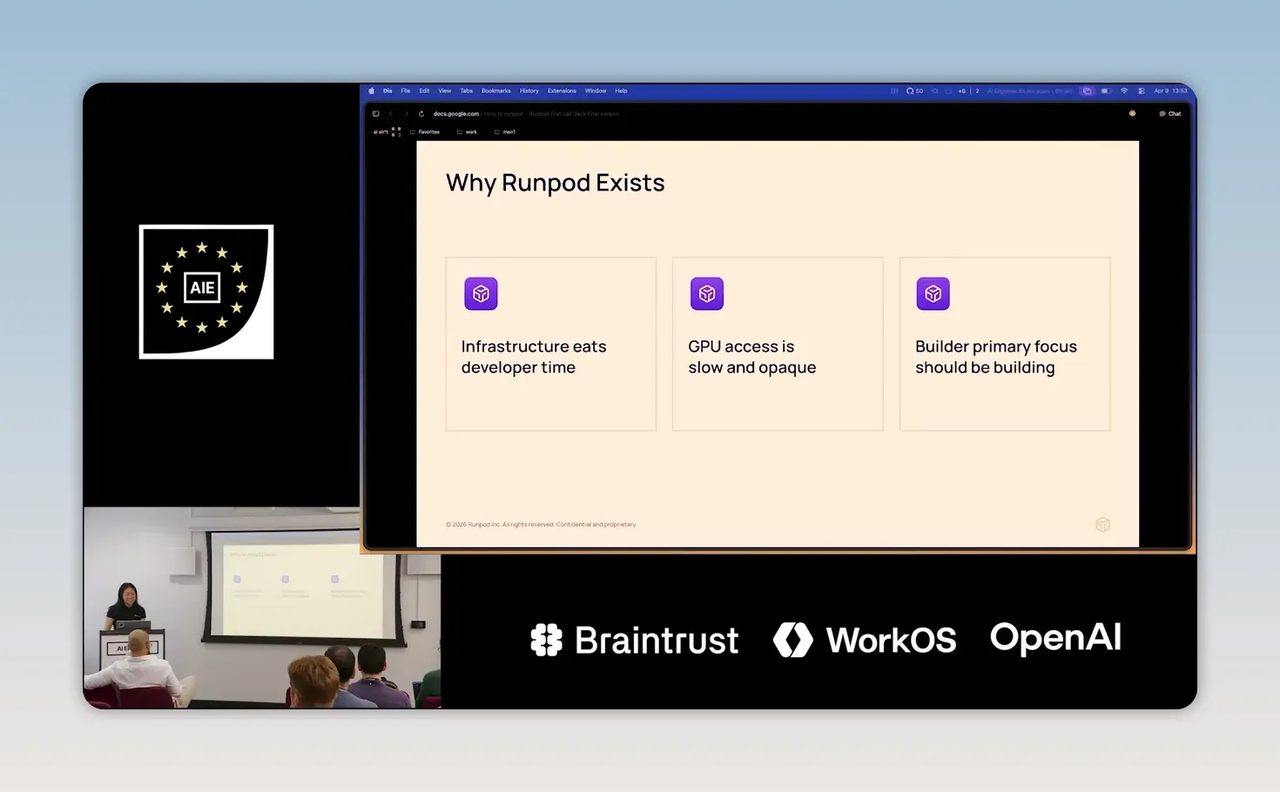
Step 1: เข้าใจก่อนว่า RunPod แก้ปัญหาอะไร
RunPod วางตัวเองเป็น cloud AI infrastructure สำหรับงานที่ต้องใช้ GPU โดยเฉพาะ จุดขายหลักคือทำให้การนำ model ไปใช้งานง่ายขึ้น ทีมไม่ต้องมานั่งจัดการเครื่อง เซิร์ฟเวอร์ หรือ setup GPU เองทั้งหมด แค่เตรียม code และ container ให้พร้อม ที่เหลือ platform ช่วยดูแลเรื่อง environment, provisioning และการรันงานให้
ถ้ามองในภาพใหญ่ สิ่งที่ RunPod พยายามแก้มี 3 เรื่อง
- Infrastructure ซับซ้อน การตั้งเครื่องเองหรือบริหาร GPU โดยตรงกินเวลาและต้องใช้ทักษะเฉพาะ
- การเข้าถึง GPU ไม่ง่าย ทั้งเรื่องของราคา ความขาดแคลน และการคาดการณ์ว่าต้องใช้ compute เท่าไร
- ทีมควรโฟกัสที่การสร้างสินค้า มูลค่าของธุรกิจอยู่ที่ workflow และประสบการณ์ที่เราสร้าง ไม่ใช่งานดูแลเครื่อง
อันนี้เป็นจุดที่น่าคิดมากสำหรับธุรกิจไทย หลายทีมยังใช้พลังงานไปกับ “การประกอบของ” มากกว่า “การขายผลลัพธ์” เช่น อยากทำ AI chatbot สำหรับฝ่ายขาย แต่กลับใช้เวลาหลายสัปดาห์ไปกับการหาเครื่องและ config ระบบ สุดท้ายยังไม่ทันได้ทดสอบว่าลูกค้าชอบหรือไม่
ถ้าเป้าหมายคือทดลอง use case ให้เร็ว เช่น AI ช่วยตอบแชต, ช่วยสรุปเอกสาร, ช่วยค้นหาความรู้ในองค์กร platform แบบนี้ลดเวลาเริ่มต้นได้เยอะ
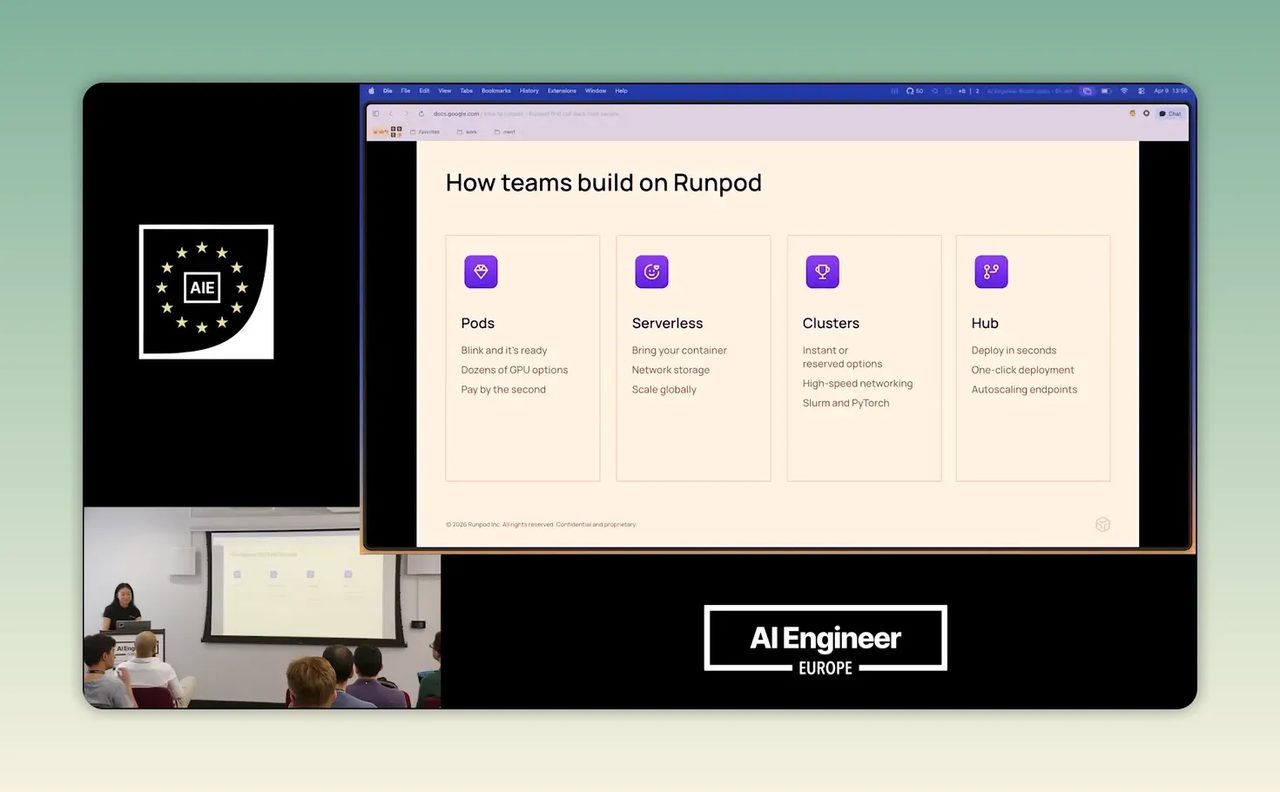
Step 2: ประเมินว่า workload ของเราเหมาะกับ Pods, Serverless หรือ Clusters
คลิปอธิบายโครงสร้างของ RunPod ไว้ค่อนข้างชัดว่ามีหลายทางเลือก ไม่ได้มีแค่ serverless อย่างเดียว
- Pods เป็น sandbox หรือ virtual environment ที่รัน container พร้อม GPU เหมาะกับงานที่อยากควบคุม environment เองมากขึ้น
- Serverless เหมาะกับ inference แบบเรียลไทม์ งานที่ปริมาณทราฟฟิกขึ้นลง หรือโหลดมาเป็นช่วง
- Clusters เหมาะกับ training หนักๆ หรือ multi-node workload
- Hub เป็นแหล่งรวม repo ที่เตรียมไว้แล้วสำหรับ deploy ได้เร็ว
สำหรับเจ้าของธุรกิจและคนทำงานทั่วไป ประเด็นสำคัญไม่ใช่ศัพท์เทคนิค แต่คือการเลือกให้ตรงงาน
ถ้าเป็น use case แบบนี้ มักเหมาะกับ serverless
- ระบบตอบคำถามลูกค้าแบบ AI ที่มีคำถามเข้ามาไม่สม่ำเสมอ
- ระบบสรุปเอกสารที่ทีมใช้เป็นบางช่วงของวัน
- งาน batch ที่รันเป็นรอบ เช่น สรุปรายงานรายวัน
แต่ถ้าเป็นงานที่โหลดคงที่ตลอดเวลา หรือมีการใช้งานภายในองค์กรต่อเนื่องทั้งวัน Pods อาจคุ้มกว่าในบางกรณี เพราะไม่ต้องเจอ cold start บ่อย
มุมที่ควรระวังคือ หลายทีมได้ยินคำว่า serverless แล้วคิดว่าถูกกว่าเสมอ ซึ่งไม่จริง ถ้างานของเรา active ตลอดเวลา การจ่ายแบบเปิดเครื่องค้างไว้อาจคุ้มกว่า เพราะ serverless จะโดดเด่นเมื่อโหลดแกว่ง หรือมี idle time เยอะ
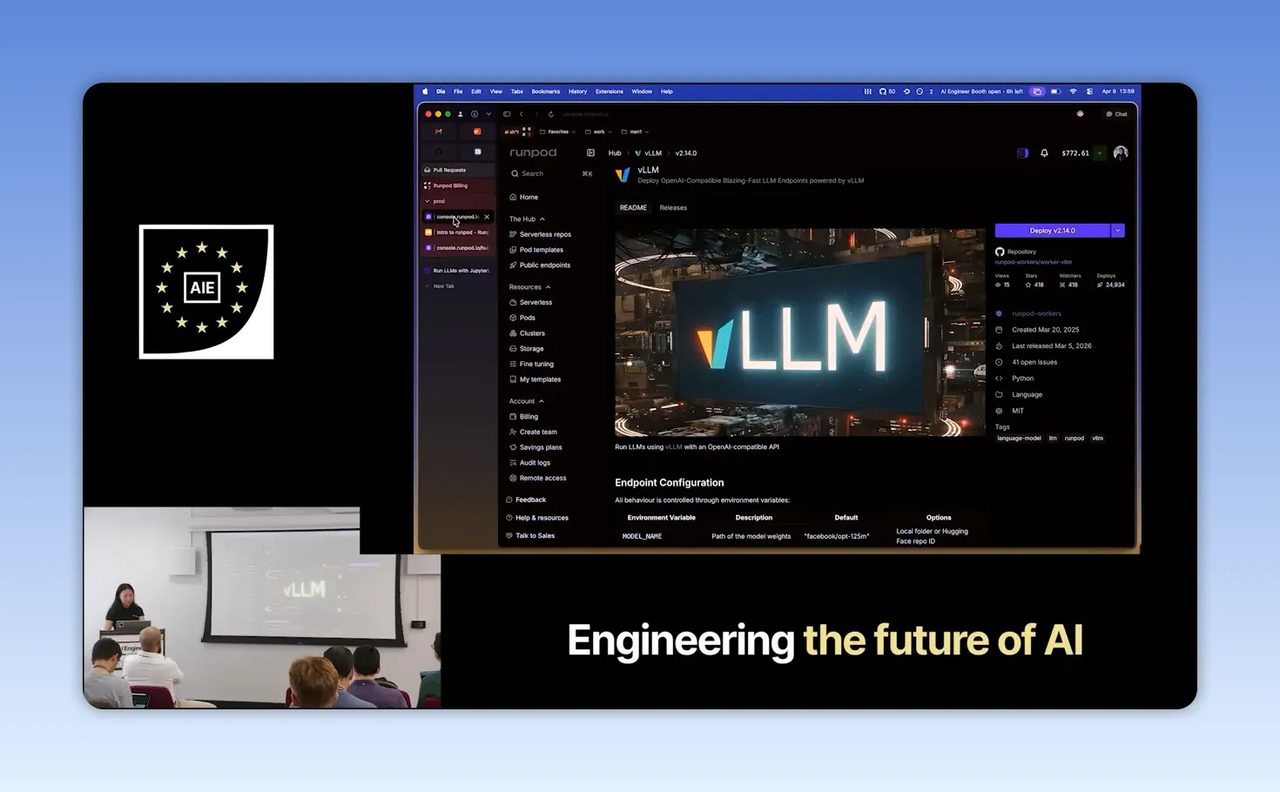
Step 3: ใช้ Hub เพื่อลดเวลาเริ่มต้น
ช่วงสาธิตในคลิปเริ่มจากการเข้า Hub ของ RunPod แล้วเลือก listing ที่เตรียมไว้แล้ว โดยตัวอย่างใช้ vLLM ซึ่งเป็นเครื่องมือยอดนิยมสำหรับ serving LLM ประสิทธิภาพสูง หากยังไม่คุ้น vLLM สามารถดูข้อมูลเพิ่มเติมได้ที่ เอกสารทางการของ vLLM
แนวคิดของ Hub เรียบง่ายแต่สำคัญมาก คือแทนที่เราจะต้องเริ่มทุกอย่างจากศูนย์ RunPod มี repo ที่ pre-configured และผ่านการคัดกรองไว้แล้วให้หยิบไปใช้ต่อได้ บางรายการมาจากทีม RunPod เอง บางส่วนมาจาก community
ในทางธุรกิจ นี่คือการลดต้นทุนของ “การลองผิดครั้งแรก” เพราะทีมไม่ต้องเสียเวลา setup พื้นฐานก่อนจะได้ทดสอบ value จริงของระบบ
ตัวอย่างที่เห็นภาพชัดคือ ถ้าเรากำลังจะทดลอง AI assistant สำหรับทีมขาย สิ่งที่ควรพิสูจน์ก่อนคือ
- คำตอบช่วยปิดการขายได้ดีขึ้นไหม
- ตอบได้เร็วพอไหม
- ลดเวลาทีมงานได้กี่ชั่วโมงต่อสัปดาห์
ไม่ใช่ไปเสียเวลา 2 สัปดาห์กับการเขียนไฟล์ config ทั้งหมดเอง ทั้งที่ยังไม่รู้เลยว่า use case จะรอดไหม
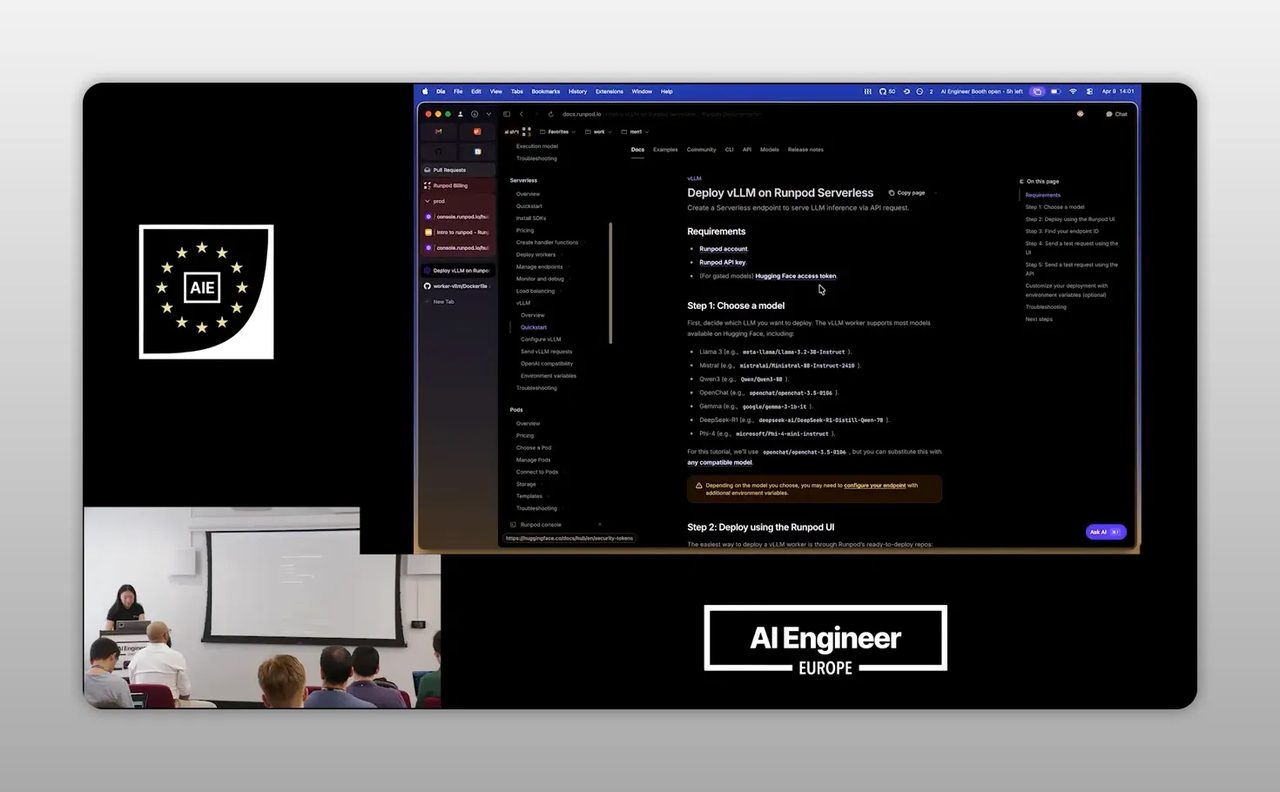
Step 4: เลือก model และตั้งค่าที่กระทบต้นทุนจริง
หลังจากเลือก listing แล้ว ขั้นตอนสำคัญคือการตั้งค่า deploy ซึ่งในเดโมมีการเลือก model ที่จะดึงมาจาก Hugging Face และขยับค่า context window หรือความยาวข้อความที่ model รองรับ
จุดนี้ดูเหมือนเป็นรายละเอียดเทคนิค แต่จริงๆ กระทบธุรกิจเต็มๆ เพราะทุกการตั้งค่าเกี่ยวข้องกับต้นทุน ความเร็ว และคุณภาพคำตอบ
ค่าที่ควรเข้าใจมีอย่างน้อย 3 ตัว
- Model ที่เลือก model ใหญ่ขึ้นมักตอบดีขึ้นในบางงาน แต่แพงขึ้นและช้าลง
- Context window ถ้าต้องป้อนเอกสารยาวมาก ก็ต้องเผื่อ context แต่ยิ่งยาวก็ยิ่งกินทรัพยากร
- GPU ที่ใช้ ในเดโมมีการ deploy บน H100 และใช้ A100 เป็นตัวสำรอง ซึ่งสะท้อนว่าระดับ hardware ก็มีผลกับ performance และราคา
ถ้าเป็นธุรกิจไทยที่กำลังเริ่มต้น คำแนะนำเชิงปฏิบัติคืออย่าเริ่มจาก model ใหญ่สุด ให้เริ่มจาก model ที่ “ดีพอสำหรับงาน” ก่อน เช่น งานสรุปข้อความภายในองค์กรอาจไม่จำเป็นต้องใช้ model แพงที่สุด แต่ถ้าเป็นงานที่กระทบลูกค้าโดยตรง เช่น ให้คำแนะนำทางการเงินหรือสรุปสัญญา อาจต้องใส่ใจคุณภาพมากขึ้น
อีกประเด็นคือหลายทีมชอบขอ context ยาวไว้ก่อน เพราะคิดว่าปลอดภัย แต่ผลคือค่าใช้จ่ายสูงโดยไม่จำเป็น ถ้างานจริงใช้เอกสารเฉลี่ย 2 ถึง 3 หน้า ก็ไม่ควรเผื่อแบบ 100 หน้า
Step 5: ตั้งค่า serverless ให้บาลานซ์ระหว่างความเร็วกับค่าใช้จ่าย
หัวใจของเดโมอยู่ที่ serverless endpoint ซึ่ง RunPod ให้เรากำหนดพฤติกรรมการ scaling ได้ เช่น จำนวน worker สูงสุด, spending cap และจำนวน worker ที่เปิดค้างไว้ตลอด
นี่คือจุดที่มีประโยชน์มากสำหรับฝั่งธุรกิจ เพราะมันแปลเป็นภาษาง่ายๆ ได้ว่า
- ถ้ามีคนใช้งานเยอะขึ้น ระบบจะขยายกำลังรองรับได้
- ถ้าไม่มีการใช้งาน ระบบหยุดกินเงินได้
- ถ้าอยากลดเวลารอคำตอบ เราสามารถเปิด worker ค้างไว้บางส่วนได้
รูปแบบนี้เหมาะกับงานที่มีความไม่แน่นอนของโหลด เช่น ช่วงเช้ามีคำถามเยอะ ช่วงดึกแทบไม่มีใครใช้ แต่ถ้าระบบของเรามีลูกค้าใช้งานตลอดทุกนาที การเปิด always-on worker หรือพิจารณาใช้อีก deployment model อาจคุ้มกว่า
ในเดโมมีการอธิบายเรื่องราคาแบบคิดเฉพาะเวลาที่ worker ทำงานกับ request จริง จุดนี้น่าสนใจมากเพราะทำให้ทีมควบคุมต้นทุนการทดลองได้ดีขึ้น โดยเฉพาะช่วง proof of concept
Step 6: ยอมรับความจริงเรื่อง cold start ก่อนเอาไปใช้กับลูกค้า
หนึ่งในข้อมูลที่มีค่าที่สุดของคลิปคือการสาธิตให้เห็นผลจริง ไม่ได้บอกแค่ว่า deploy ได้เร็ว แต่ยังโชว์ข้อจำกัดด้วย
คำขอแรกใช้เวลารอในคิวประมาณ 41 วินาที เพราะระบบต้องสร้าง container และดาวน์โหลด model ก่อน นี่คือสิ่งที่เรียกว่า cold start แต่หลังจากนั้นคำขอถัดไปใช้เวลาประมวลผลประมาณ 1.5 วินาทีเท่านั้น
นี่คือจุดที่หลายทีมมักพลาด ถ้าทดสอบเองแล้วเจอ request แรกช้า ก็รีบสรุปว่า platform ไม่ดี ทั้งที่จริงมันเป็นธรรมชาติของ serverless
คำถามที่ถูกต้องกว่าคือ งานของเรารับ cold start ได้ไหม
- ถ้าเป็นระบบหลังบ้าน เช่น สรุปรายงาน หรือประมวลผลเอกสารภายใน 41 วินาทีอาจรับได้
- ถ้าเป็น chatbot หน้าเว็บที่ลูกค้าคาดหวังคำตอบทันที 41 วินาทีนานเกินไป
วิธีรับมือคือเปิด active workers ไว้ล่วงหน้า หรือออกแบบระบบให้มี fallback เช่น แสดงข้อความแจ้งสถานะ หรือให้ระบบตอบเบื้องต้นก่อนแล้วตามด้วยผลเต็ม
สำหรับธุรกิจไทย นี่สำคัญมากเพราะประสบการณ์ผู้ใช้ไม่ให้อภัยความช้า ถ้า AI ตอบช้าเกินไป ลูกค้ามักมองว่าระบบเสีย ไม่ได้สนใจว่า backend กำลัง warm up อยู่
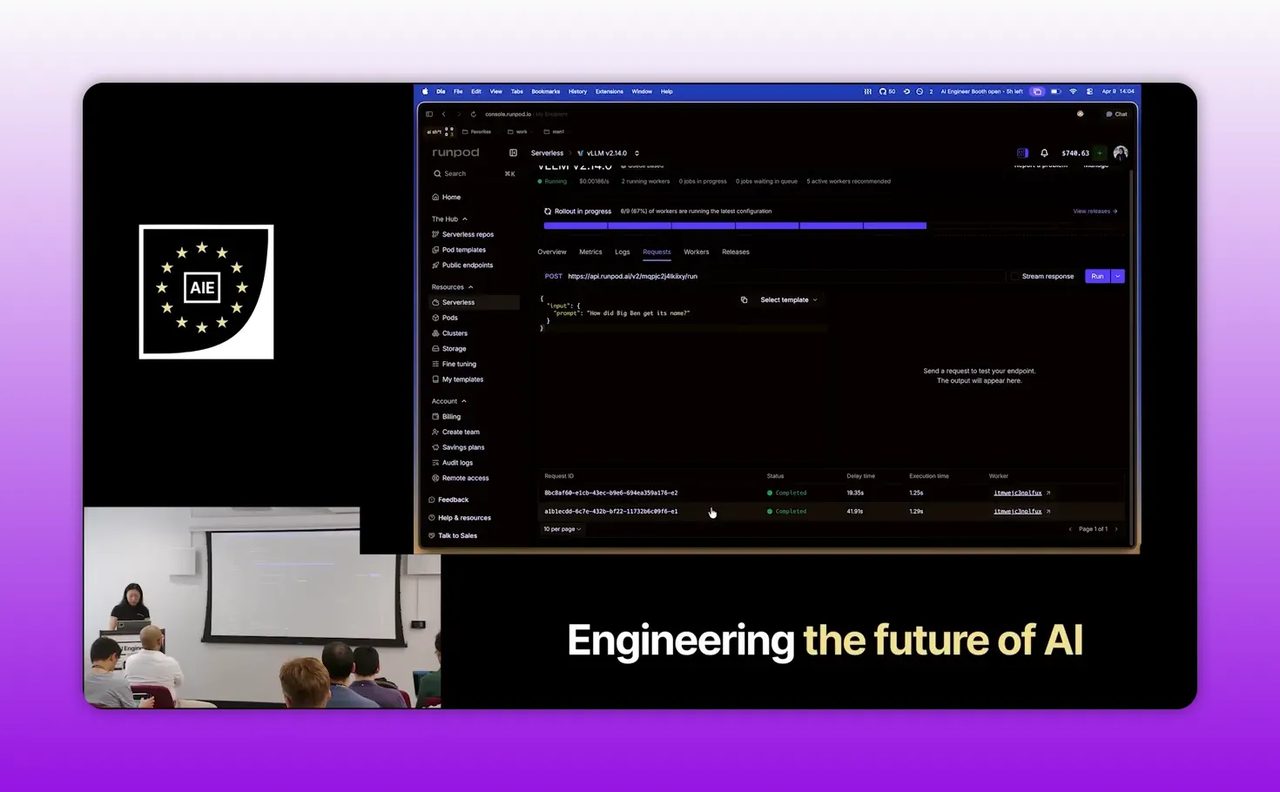
Step 7: ใช้ endpoint และ telemetry เพื่อตัดสินใจแบบคนทำธุรกิจ
เมื่อ deploy เสร็จ RunPod จะสร้าง API endpoint ให้พร้อมเรียกใช้งานผ่าน HTTP ได้ จุดนี้สำคัญเพราะหมายความว่าทีมสามารถเอา endpoint ไปเชื่อมกับเว็บ, LINE OA, CRM, หรือระบบภายในได้ต่อทันที
แต่สิ่งที่ไม่ควรมองข้ามคือ telemetry และ observability ที่ RunPod แสดงให้ดู เช่น จำนวน request, เวลาประมวลผล และเวลาที่คำขอรอคิว ข้อมูลเหล่านี้ไม่ใช่ของแถม มันคือเครื่องมือวัด ROI
ถ้าเราจะใช้ AI ในธุรกิจจริง เราควรถามจากตัวเลขพวกนี้ว่า
- ลูกค้ารอนานเกินไปหรือไม่
- มีช่วงเวลาไหนที่ระบบเริ่มคิวสะสม
- ควรเพิ่ม worker หรือปรับ workflow แทน
- ต้นทุนต่อ request อยู่ในระดับที่รับได้ไหม
พูดอีกแบบคือ AI product ที่ดีไม่ได้จบตอน model ตอบได้ แต่มันเริ่มจริงตอนเราวัดได้ว่าคำตอบนั้นเร็วพอ ถูกพอ และคุ้มพอ
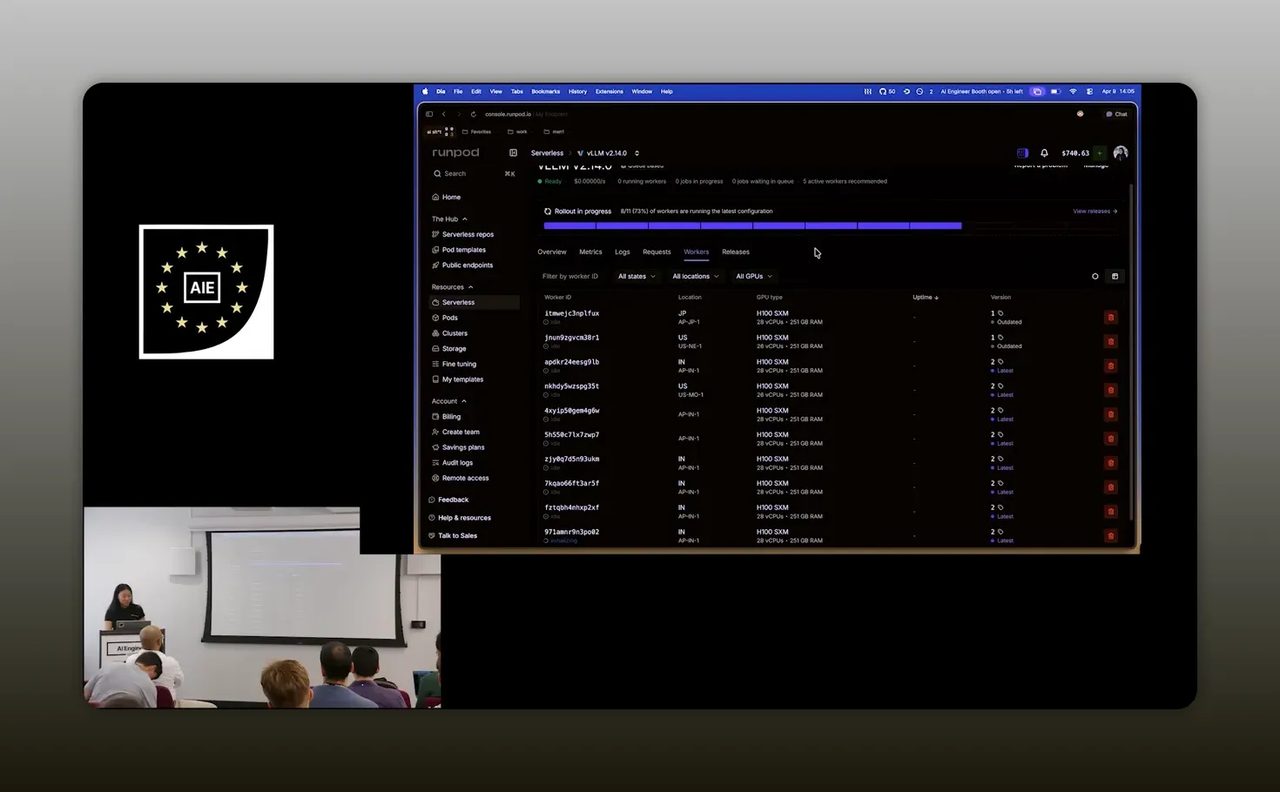
Step 8: แปลบทเรียนจากเดโมให้เป็นภาพใช้งานในธุรกิจไทย
ถ้าเอาคลิปนี้มามองในมุมธุรกิจไทย จะเห็น use case ที่ค่อนข้างชัด
ตัวอย่างที่ 1: AI ผู้ช่วยตอบแชตขาย
ใช้ LLM endpoint เป็น backend ให้ระบบตอบคำถามสินค้า โปรโมชั่น หรือช่วยร่างคำตอบให้แอดมิน ข้อควรคิดคือถ้าต้องตอบลูกค้าแบบทันที ควรเปิด active workers ค้างไว้เพื่อลด cold start
ตัวอย่างที่ 2: ระบบสรุปเอกสารภายในองค์กร
เช่น สรุปรายงานประชุม สรุปเอกสารเสนอราคา หรือสกัดประเด็นจากไฟล์ยาว งานแบบนี้เหมาะกับ serverless มาก เพราะไม่ได้มี request ตลอดเวลา
ตัวอย่างที่ 3: AI search หรือ knowledge assistant
ใช้ endpoint เชื่อมกับฐานความรู้ของบริษัทให้ทีมขายหรือฝ่ายบริการค้นหาคำตอบเร็วขึ้น งานประเภทนี้ต้องระวังเรื่อง context window และคุณภาพข้อมูลป้อนเข้า model มากกว่าการไล่ใช้ model ใหญ่ที่สุด
มุมที่เราเห็นด้วยกับคลิปคือ การลดแรงเสียดทานของ infra ทำให้ทีมเริ่มเร็วขึ้นมาก
แต่มุมที่ควรพูดตรงๆ คือ “deploy ได้ใน 5 นาที” ไม่ได้แปลว่า “พร้อมใช้กับธุรกิจใน 5 นาที” เพราะงานจริงยังมีอีกหลายชั้น เช่น prompt design, guardrails, การเชื่อมข้อมูลภายใน, การควบคุมคุณภาพคำตอบ และการติดตามต้นทุน
Actionable Insights
- เริ่มจาก use case ที่วัดผลได้ เช่น ลดเวลาสรุปเอกสาร หรือเพิ่มความเร็วตอบลูกค้า อย่าเริ่มจากโปรเจกต์ใหญ่เกินไป
- เลือก serverless เมื่อโหลดแกว่ง ถ้างานไม่ได้มี request ตลอดวัน การจ่ายตามการใช้งานมักเหมาะกว่า
- กันงบด้วย spending cap ก่อนเปิดใช้จริงควรกำหนดเพดานค่าใช้จ่ายเสมอ
- ลด cold start ด้วย active workers ถ้างานต้องตอบเร็ว ควรยอมจ่ายบางส่วนเพื่อให้พร้อมใช้งานตลอด
- วัดผลจาก request time และ queue time อย่าตัดสินระบบจากความรู้สึก ให้ดูตัวเลขจริง
Troubleshooting
- ปัญหา: คำขอแรกช้ามาก
สาเหตุ: เกิด cold start จากการสร้าง container และดาวน์โหลด model
วิธีแก้: เปิด active workers ไว้ล่วงหน้า, ลดขนาด model, ทดสอบช่วงเวลาที่มีโหลดจริง - ปัญหา: ค่าใช้จ่ายสูงกว่าที่คิด
สาเหตุ: เลือก model ใหญ่เกินงานจริง หรือเปิด worker ค้างไว้มากเกินไป
วิธีแก้: เริ่มจาก model เล็กลง, ตั้ง spending cap, ตรวจต้นทุนต่อ request เป็นรายสัปดาห์ - ปัญหา: ระบบตอบช้าช่วงคนใช้เยอะ
สาเหตุ: จำนวน worker สูงสุดน้อยเกินไป หรือ queue สะสม
วิธีแก้: ปรับ max workers, ดู telemetry, แยก workload ที่ไม่จำเป็นต้อง realtime ออกไปเป็น batch - ปัญหา: คำตอบไม่เสถียรเมื่อใส่ข้อมูลยาว
สาเหตุ: ตั้ง context window ไม่พอ หรือป้อนข้อมูลเกินความจำเป็น
วิธีแก้: คัดเฉพาะข้อมูลที่จำเป็น, ปรับ context ให้เหมาะกับงาน, แยกเอกสารเป็นช่วงก่อนส่งเข้า model - ปัญหา: deploy ได้ แต่ยังใช้กับงานจริงไม่ได้
สาเหตุ: ยังไม่มี workflow รอบข้าง เช่น prompt, validation, การเชื่อมข้อมูล, การจัดการสิทธิ์ใช้งาน
วิธีแก้: ทำ proof of concept ทีละขั้น เริ่มจาก endpoint แล้วค่อยต่อกับระบบธุรกิจทีละส่วน
การต่อยอด
- ต่อ endpoint เข้ากับ LINE OA หรือระบบแชตของบริษัท เพื่อให้ทีมขายใช้ AI ช่วยร่างคำตอบ
- เพิ่ม layer สำหรับค้นหาข้อมูลก่อนตอบ เพื่อให้ AI อ้างอิงความรู้เฉพาะขององค์กรได้ดีขึ้น
- ทำ dashboard ติดตามต้นทุนต่อ request และเวลาตอบกลับ เพื่อให้ตัดสินใจเรื่อง scale จากข้อมูลจริง
สรุป Checklist ทั้งหมด
- ☐ ระบุ use case AI ที่ต้องการทำให้ชัดก่อน
- ☐ ประเมินว่า workload เหมาะกับ Pods, Serverless หรือ Clusters
- ☐ เริ่มจาก Hub เพื่อประหยัดเวลา setup
- ☐ เลือก model ให้เหมาะกับงาน ไม่ใช่ใหญ่สุดเสมอ
- ☐ ปรับ context window เท่าที่จำเป็น
- ☐ ตั้ง max workers และ spending cap ก่อนเปิดใช้
- ☐ ตัดสินใจว่าจะเปิด active workers หรือไม่
- ☐ ทดสอบ cold start และความเร็วของ request ถัดไป
- ☐ ดู telemetry เรื่อง queue time และ execution time
- ☐ เชื่อม endpoint เข้ากับ workflow ธุรกิจจริงทีละขั้น
- ☐ วัดต้นทุนต่อ request และผลลัพธ์ทางธุรกิจอย่างสม่ำเสมอ
สรุปแล้ว คลิปนี้ไม่ได้แค่โชว์ว่า RunPod deploy LLM endpoint ได้เร็ว แต่ชี้ให้เห็นภาพชัดว่าทำไม AI infrastructure แบบสำเร็จรูปถึงมีบทบาทมากขึ้น โดยเฉพาะสำหรับทีมที่อยากเอา AI ไปใช้จริงแต่ไม่อยากจมอยู่กับงานระบบ ถ้าเรามอง RunPod เป็นเครื่องมือช่วยย่นเวลา จากไอเดียไปสู่ API มันมีประโยชน์มาก
แต่บทเรียนที่สำคัญกว่าคือ เราไม่ควรตื่นเต้นกับคำว่า “5 นาที” จนลืมถามว่าหลังจาก deploy แล้ว ธุรกิจได้อะไรต่อ AI ที่ใช้งานได้จริงต้องผ่านการเลือก use case ที่ถูก วัดผลได้ คุมต้นทุนได้ และออกแบบประสบการณ์ใช้งานให้เหมาะกับความคาดหวังของลูกค้าและทีมงาน