
สรุปจากคลิป ดูคลิปต้นฉบับ
Deploy งาน AI ขึ้น GPU Cloud จาก IDE ได้เลยแบบไม่ต้องวุ่นกับ Infra

ปัญหาของหลายทีมที่อยากใช้ AI ไม่ได้อยู่ที่การคิด use case แต่อยู่ที่ขั้นตอนจุกจิกก่อนจะได้ลองจริง ตั้งแต่ commit โค้ด push ขึ้น GitHub สร้าง Docker image ดึงลง server จอง GPU แล้วค่อยรู้ว่ามันรันได้หรือพัง คลิปจากช่อง AI Engineer หยิบปัญหานี้มาขยายให้เห็นชัด ผ่านเดโมของ Audrey Hsu จาก RunPod ว่าจะลดวงจรนี้ให้เหลือการใส่ decorator ใน Python ได้อย่างไร
สิ่งที่น่าสนใจไม่ได้มีแค่เรื่องเทคนิค แต่คือแนวคิดเรื่องความเร็วในการทดลอง ถ้าทีมเปลี่ยน model หรือแก้ logic แล้วทดสอบบน GPU ได้ทันทีจาก IDE ต้นทุนที่หายไปไม่ใช่แค่ค่าเครื่อง แต่คือเวลาตัดสินใจของธุรกิจด้วย สำหรับเจ้าของธุรกิจและคนทำงานที่อยากเอา AI ไปใช้จริง ประเด็นสำคัญจากคลิปนี้คือ เราไม่จำเป็นต้องเริ่มจากระบบใหญ่เสมอไป แต่ควรเริ่มจาก workflow ที่ทำให้ลองได้เร็วที่สุดก่อน
สารบัญ
- Step 1: เข้าใจก่อนว่าคอขวดของงาน AI มักไม่ใช่ model แต่คือ infrastructure
- Step 2: เลือกโหมดการใช้งานให้ตรงกับลักษณะงาน ไม่ใช่เลือกจากของที่ดูเท่
- Step 3: ลดรอบการทดลองด้วยแนวคิด deploy จาก IDE ตรงขึ้น GPU
- Step 4: ดูโครงสร้าง endpoint ให้เป็น เพราะนี่คือจุดที่คุมทั้งความเร็วและต้นทุน
- Step 5: ทดลอง use case ง่ายก่อนด้วย image generation แล้วดูว่ารอบแก้ไขเร็วขึ้นแค่ไหน
- Step 6: อย่าหยุดที่ model เดียว เพราะคุณค่าจริงของ AI งานธุรกิจอยู่ที่ orchestration
- Step 7: คิดเรื่องราคาแบบต่อคำขอ ไม่ใช่แบบเช่าเครื่องทั้งวัน
- Step 8: ประเมินผลลัพธ์แบบคนทำธุรกิจ ไม่ใช่ดูแค่เดโมว่าสวยหรือไม่
- Step 9: แปลงบทเรียนจากเดโมให้เข้ากับธุรกิจไทย
- Actionable Insights
- Troubleshooting
- การต่อยอด
- Step 10: สรุป Checklist ทั้งหมด
Step 1: เข้าใจก่อนว่าคอขวดของงาน AI มักไม่ใช่ model แต่คือ infrastructure
RunPod วางตัวเองเป็น AI cloud infrastructure platform ที่ช่วยให้ทีมเอาโค้ดและ model ไปใช้งานบน GPU ได้เร็ว โดยไม่ต้องเสียเวลากับการจัดการ infra มากเกินไป จุดขายหลักไม่ใช่แค่มี GPU ให้เช่า แต่คือช่วยลดภาระเรื่อง version ที่เข้ากันได้ การตั้งค่า CUDA การเลือก PyTorch ให้ตรงกับ GPU และปัญหาจุกจิกที่ทำให้ทีมเสียรอบทดลองไปเรื่อยๆ
นี่เป็น insight ที่สำคัญมากสำหรับธุรกิจไทย หลายทีมเข้าใจว่าการทำ AI ต้องเริ่มจากจ้าง data scientist หรือซื้อ model ดีๆ แต่ในความจริงทีมมักสะดุดที่เรื่อง deployment และการทดสอบมากกว่า ถ้า workflow ช้า ต่อให้ model ดีแค่ไหนก็ไปต่อยาก เพราะทุกการทดลองมีต้นทุนแฝง
มุมที่ควรคิดเพิ่มคือ ธุรกิจไม่ได้ชนะเพราะมี model ที่ล้ำที่สุดเสมอไป แต่ชนะเพราะสามารถลอง use case ใหม่ๆ ได้เร็วกว่า เช่น ทีมการตลาดอยากทดลองสร้างภาพสินค้าอัตโนมัติ ทีมบริการลูกค้าอยากทดลองระบบตอบแชต หรือทีมขายอยากสร้าง proposal อัตโนมัติ ถ้าการทดลองแต่ละครั้งต้องรอทีม infra นานหลายวัน ความอยากทดลองก็หายไปเอง
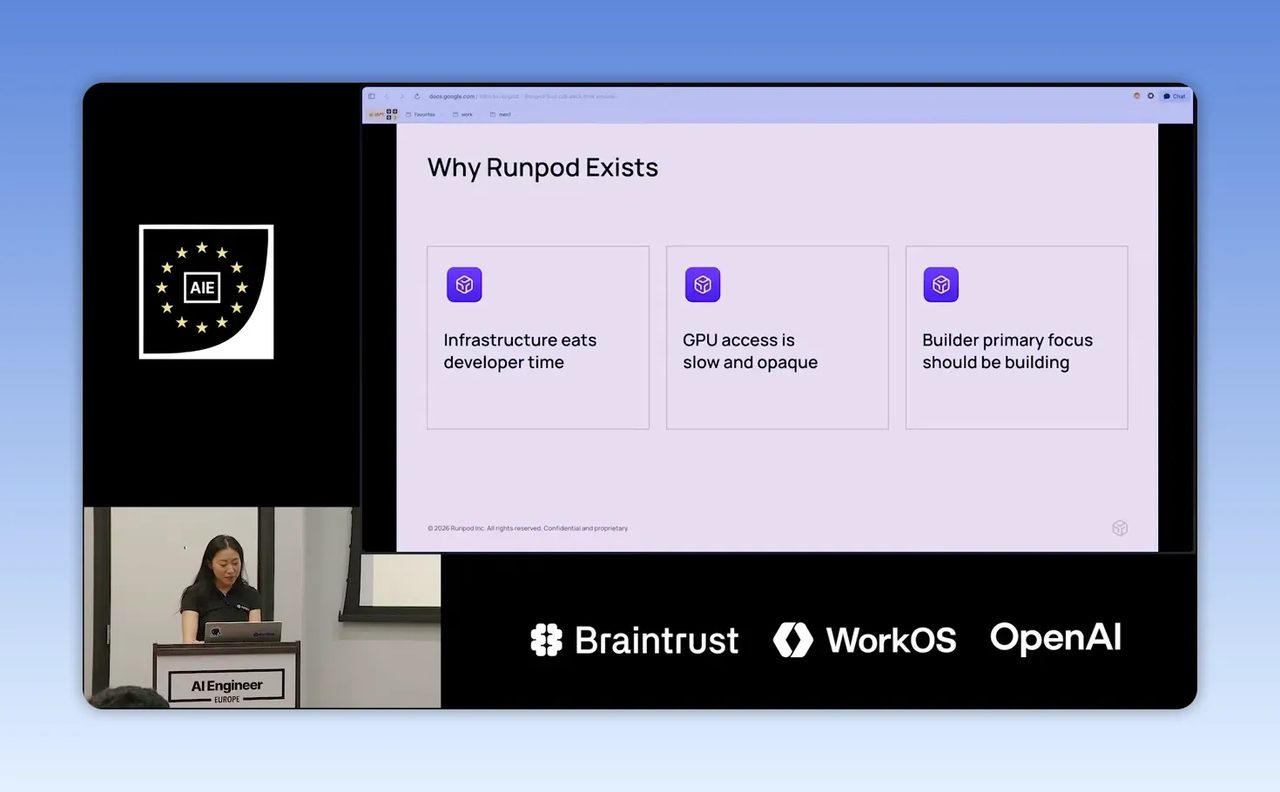
Step 2: เลือกโหมดการใช้งานให้ตรงกับลักษณะงาน ไม่ใช่เลือกจากของที่ดูเท่
ในคลิปมีการอธิบายสินค้าหลักของ RunPod แบบคร่าวๆ ซึ่งแบ่งได้เป็น 4 แบบที่เข้าใจง่ายมาก
- Pods เหมาะกับงานที่ต้องการเครื่องแบบคงอยู่ต่อเนื่อง คล้ายเช่า VM ที่มี GPU ประจำ
- Serverless เหมาะกับงานที่โหลดขึ้นลง ไม่อยากจ่ายค่า idle time และอยากให้ระบบ scale อัตโนมัติ
- Clusters เหมาะกับงานฝึก model หลาย node
- Hub เหมาะกับการเริ่มต้นจาก open source repo ที่เตรียมไว้แล้ว
คำแนะนำจากเดโมถือว่าตรงไปตรงมาดี คือถ้ายังอยู่ช่วงทดลอง ไม่จำเป็นต้องรีบกระโดดไป serverless เต็มรูปแบบ เริ่มจาก pods หรือจำกัด worker ให้น้อยก่อนจะคุมต้นทุนง่ายกว่า พอโหลดเริ่มจริง มี request มากขึ้น ค่อยขยับไป serverless
มุมนี้สำคัญกับธุรกิจไทยมาก เพราะหลายทีมชอบเริ่มจากสถาปัตยกรรมที่เผื่อโตไว้เกินจริง สุดท้ายระบบซับซ้อนก่อนจะมีลูกค้าหรือ use case ที่พิสูจน์ได้จริง ถ้าเรากำลังทำ AI สำหรับงานภายในองค์กร เช่น สร้างรูป social post หรือช่วยสรุปรายงาน เริ่มจากของง่ายและชัดเจนจะดีกว่า
Step 3: ลดรอบการทดลองด้วยแนวคิด deploy จาก IDE ตรงขึ้น GPU
หัวใจของคลิปอยู่ตรงนี้ Audrey ชี้ให้เห็น workflow แบบเดิมที่หลายทีมเจอ คือแก้โค้ดหนึ่งจุด แต่ต้องผ่านหลายขั้นก่อนจะรู้ผลลัพธ์จริงบน GPU ทำให้การ iterate ช้าและเสียแรงแบบไม่จำเป็น
สิ่งที่ Flash ซึ่งเป็น Python SDK ของ RunPod พยายามแก้ คือให้เราเขียน async Python function ปกติ แล้วใส่ decorator ของ endpoint จากนั้นส่วนที่ต้องใช้ GPU จะถูกแพ็กและส่งขึ้น cloud โดยตรง ขณะที่โค้ดส่วนอื่นยังรันจากเครื่อง local ได้ตามเดิม
ถ้ามองจากมุมธุรกิจ ประเด็นนี้แปลเป็นภาษาใช้งานได้ว่า ทีมสามารถลดเวลาจาก “คิดไอเดีย” ไปสู่ “เห็นผลลัพธ์จริง” ลงได้มาก ยิ่ง use case ไหนต้องลองหลาย prompt ลองหลาย model หรือลองปรับ parameter บ่อยๆ ความต่างจะชัดมาก
ตัวอย่างในโลกธุรกิจไทย เช่น
- เอเจนซีที่ทำภาพคอนเทนต์ให้ลูกค้าหลายแบรนด์ ต้องลองสไตล์ภาพหลายแบบในวันเดียว
- ทีม e-commerce ที่ต้องเทียบ model หลายตัวเพื่อสร้างภาพสินค้า
- ทีม innovation ในองค์กรที่กำลังทดสอบ prototype หลาย use case พร้อมกัน
ถ้าทุกครั้งที่เปลี่ยน model ต้อง rebuild ทั้งระบบ ความเร็วในการเรียนรู้จะตกทันที
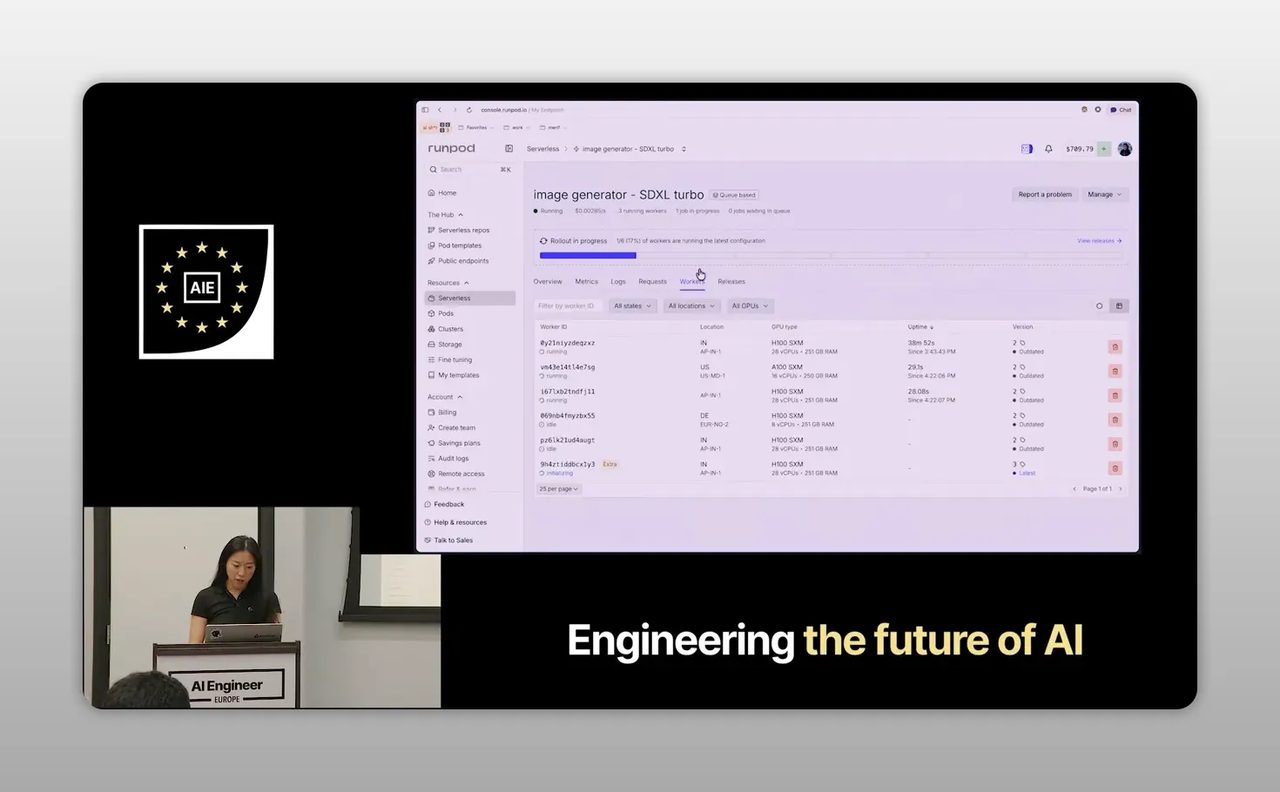
Step 4: ดูโครงสร้าง endpoint ให้เป็น เพราะนี่คือจุดที่คุมทั้งความเร็วและต้นทุน
เดโมในคลิปแสดงให้เห็นว่า decorator ไม่ได้เป็นแค่ปุ่มลัดส่งโค้ดขึ้น cloud แต่ยังเป็นจุดกำหนดพฤติกรรมของระบบด้วย เช่น ชื่อ endpoint, GPU family, จำนวน worker สูงสุด, จำนวน active worker ที่เปิดค้างไว้ และ timeout ของ worker
นี่คือจุดที่คนทำธุรกิจควรเข้าใจในเชิงแนวคิด แม้จะไม่ได้เขียนโค้ดเอง เพราะพารามิเตอร์พวกนี้ผูกกับต้นทุนและประสบการณ์ใช้งานโดยตรง
- Max workers คือเพดานการขยายเมื่อมีงานเข้ามาพร้อมกัน
- Active workers คือจำนวน worker ที่พร้อมทำงานตลอดเวลา ช่วยลดการรอ แต่ก็มีค่าใช้จ่ายมากขึ้น
- Timeout ช่วยคุมว่าถ้าไม่มีงานเข้าแล้ว worker จะถูกปิดเมื่อไร
- GPU family มีผลต่อทั้งความเร็วและราคาต่อคำขอ
ถ้าเป็นธุรกิจไทยที่เพิ่งเริ่มใช้ AI เราไม่จำเป็นต้อง optimize ทุกอย่างตั้งแต่วันแรก แต่ควรตั้งคำถามให้ถูกก่อนว่า use case ของเราคืออะไร เช่น งานสร้างภาพหน้าปกสินค้าอาจรับการรอได้ 10 ถึง 20 วินาที แต่ระบบตอบลูกค้าในแชตอาจต้องเร็วกว่า 2 วินาที การเลือก worker และ GPU จึงไม่เหมือนกัน
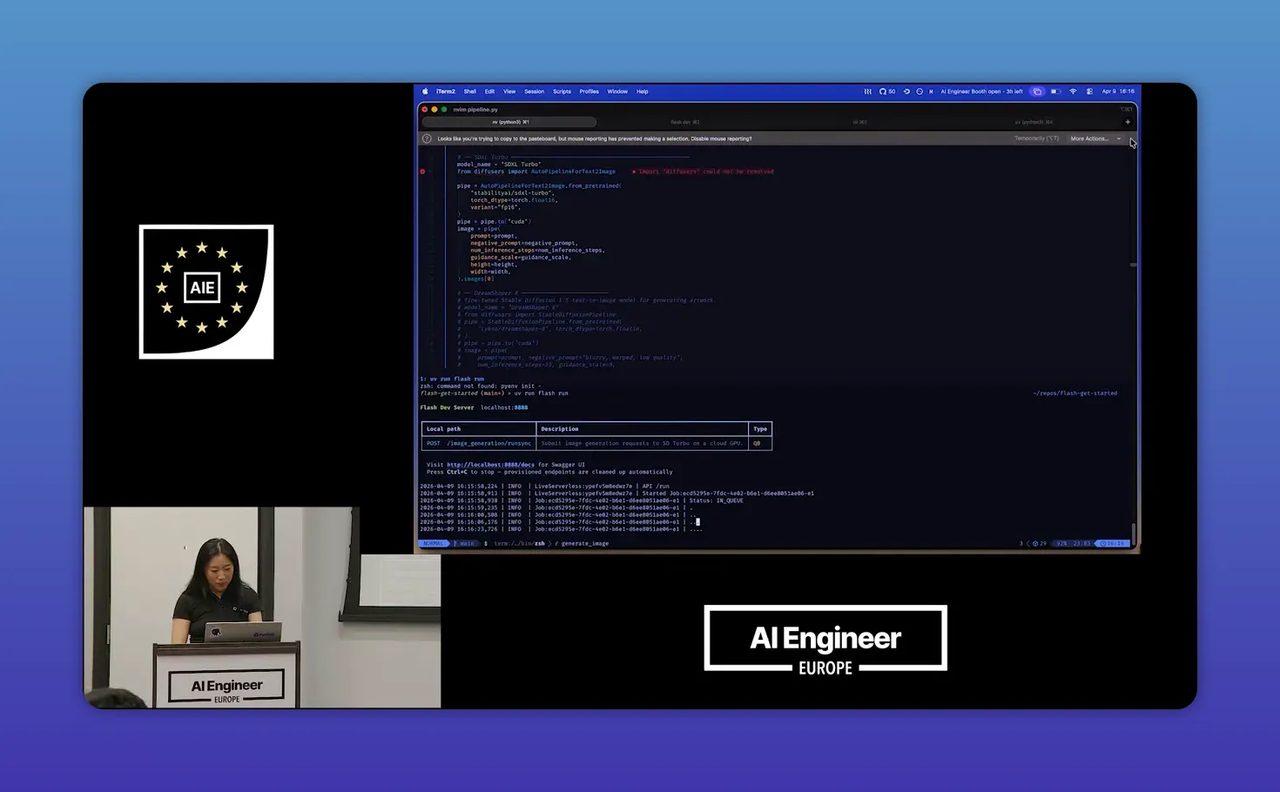
Step 5: ทดลอง use case ง่ายก่อนด้วย image generation แล้วดูว่ารอบแก้ไขเร็วขึ้นแค่ไหน
เดโมแรกในคลิปคือการสร้างภาพด้วย Stable Diffusion XL Turbo ผ่าน function สำหรับ generate image โดยโหลด model ที่ฝึกไว้ล่วงหน้า สร้างภาพ และส่งผลลัพธ์กลับมาในรูป base64 เพื่อให้แสดงผลได้ง่าย
ช่วงแรกผลลัพธ์ออกมาไม่ดีนัก ภาพที่ควรจะเป็นแมวลอยอยู่บนท้องฟ้ากลับกลายเป็นอะไรที่เพี้ยนไปมาก ตรงนี้กลับเป็นส่วนที่ดีของเดโม เพราะสะท้อนโลกจริง งาน AI ไม่ได้ให้ผลลัพธ์สวยตั้งแต่ครั้งแรกเสมอไป
จุดสำคัญคือ เมื่อผลลัพธ์ไม่ดี Audrey ไม่ได้ต้องกลับไปทำขั้นตอน deploy ใหม่ทั้งชุด แต่แค่สลับ model ในโค้ดจากตัวที่เน้นความเร็ว ไปเป็น DreamShaper ซึ่งเป็น model ที่เหมาะกับภาพแนวศิลป์มากกว่า ปรับ inference step เพิ่มขึ้น แล้วส่งคำขอเดิมอีกครั้ง ผลลัพธ์ก็ดีขึ้นทันที
นี่คือบทเรียนที่มีค่ามากสำหรับคนทำงานทั่วไป เราไม่ควรวัด AI จากผลลัพธ์ครั้งแรก แต่ควรวัดจากความเร็วในการแก้ครั้งที่สองและสาม ถ้าองค์กรมี workflow ที่เอื้อให้แก้ได้เร็ว โอกาสเจอผลลัพธ์ดีจะสูงขึ้นมาก
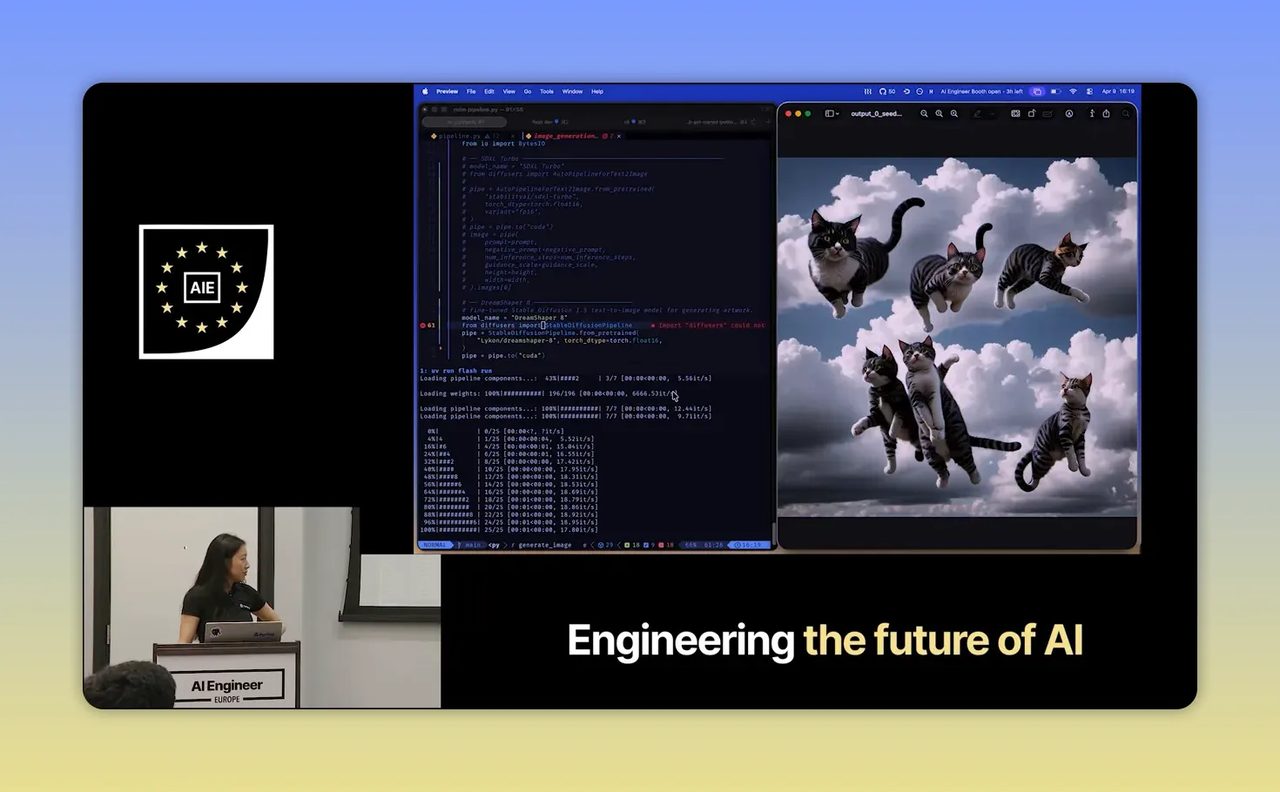
Step 6: อย่าหยุดที่ model เดียว เพราะคุณค่าจริงของ AI งานธุรกิจอยู่ที่ orchestration
ส่วนที่ดีที่สุดของคลิปไม่ใช่การสร้างภาพเดี่ยว แต่คือเดโม pipeline ที่ต่อ model หลายตัวเข้าด้วยกัน Audrey ชี้ให้เห็นว่าความยากของงาน AI ในโลกจริง มักไม่ได้อยู่ที่เรียก model ตัวเดียว แต่คือการจัดลำดับงานรอบๆ model เหล่านั้น
pipeline ที่เดโมมี 3 ชั้น
- ใช้ Qwen 3 สร้าง prompt ที่ละเอียดขึ้นจากคำสั่งตั้งต้น
- ส่ง prompt ที่ปรับดีแล้วไปให้ DreamShaper สร้างภาพ
- ส่งผลลัพธ์ต่อไปยัง Nano Banana 2 ของ Google เพื่อ compose ภาพให้สมบูรณ์ขึ้น
นี่คือภาพสะท้อนของ AI ในโลกธุรกิจอย่างชัดเจน งานจริงมักเป็น workflow หลายตอน เช่น รับข้อมูลเข้า จัดรูปแบบ วิเคราะห์ ตัดสินใจ แล้วค่อยสร้าง output ไม่ใช่ยิง prompt เดียวแล้วจบ
ถ้าแปลงเป็น use case ของไทย เราอาจนึกภาพได้แบบนี้
- รับ brief สินค้าจากทีมการตลาด แล้วให้ model แรกช่วยเขียน prompt สำหรับภาพหลายแนว
- ให้ model ที่สองสร้างภาพตาม prompt
- ให้ model ที่สามช่วยคัดเลือกรูปที่ตรงแบรนด์ที่สุด หรือ compose เป็นชิ้นงาน final
หรือในงานเอกสาร
- model แรกสรุปข้อมูลจากไฟล์ประชุม
- model ที่สองเขียนอีเมลหรือรายงาน
- model ที่สามตรวจสำนวนให้เหมาะกับผู้บริหารหรือคู่ค้า
ตรงนี้คือจุดที่หลายองค์กรยังประเมิน AI ต่ำไป เพราะมัวถามว่า “model ไหนดีที่สุด” ทั้งที่คำถามที่สำคัญกว่าคือ “เราจะออกแบบ workflow ให้ model หลายตัวช่วยกันทำงานได้อย่างไร”
Step 7: คิดเรื่องราคาแบบต่อคำขอ ไม่ใช่แบบเช่าเครื่องทั้งวัน
ในเดโมมีการพูดถึงราคา H100 สำหรับ serverless ว่าคิดค่าบริการตามเวลาที่ worker ทำงานจริงต่อ request และมีความต่างด้านราคากับ pods เพราะ serverless มีความสามารถเรื่อง autoscaling และการกระจายโหลดเพิ่มเข้ามา
ประเด็นนี้สำคัญกับเจ้าของธุรกิจมาก เพราะช่วยเปลี่ยนวิธีคิดงบประมาณ AI จากค่าเครื่องรายเดือน มาเป็นต้นทุนต่อการใช้งานจริง ตัวอย่างเช่น ถ้าเรารู้ว่าการสร้างภาพหนึ่งครั้งใช้เวลากี่วินาที เราก็พอคำนวณต้นทุนต่อภาพได้คร่าวๆ แล้วเอาไปเทียบกับมูลค่าทางธุรกิจได้
อย่างไรก็ตาม มีข้อจำกัดที่ควรพูดตรงๆ คือ serverless ไม่ได้เหมาะกับทุกสถานการณ์ ถ้างานของเราคงที่มาก รันต่อเนื่องยาวๆ หรือยังอยู่ในช่วงทดลองโดยมีคนใช้น้อย การเช่า pods อาจคุ้มกว่า การเลือกให้ถูกจังหวะจึงสำคัญกว่าการเลือกของใหม่เสมอ
ถ้าอยากอ่านแนวคิดเรื่อง serverless เพิ่มในมุมกว้าง สามารถดูคำอธิบายจาก AWS Serverless และถ้าอยากทำความเข้าใจเรื่อง container เพิ่มเติม Docker มีบทสรุปที่อ่านง่าย
Step 8: ประเมินผลลัพธ์แบบคนทำธุรกิจ ไม่ใช่ดูแค่เดโมว่าสวยหรือไม่
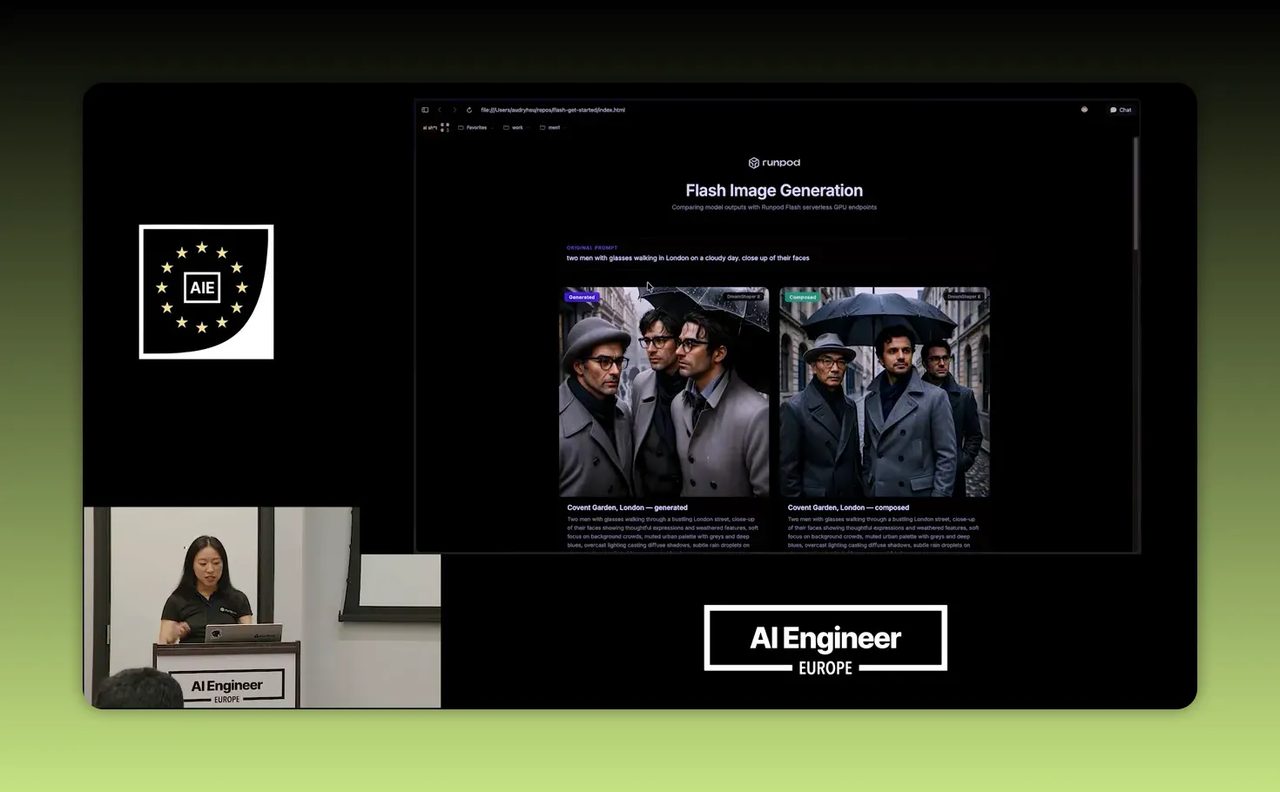
ตอนท้ายมีการโชว์ผลลัพธ์ที่ได้จาก prompt เรื่องชายสองคนใส่แว่นเดินในลอนดอนวันที่ฟ้าครึ้ม ฝั่งหนึ่งคือภาพที่สร้างจาก prompt ที่ถูกปรับให้ดีขึ้นโดย model อีกตัว และอีกฝั่งคือภาพ compose ขั้นสุดท้ายจาก pipeline ทั้งหมด
สิ่งที่ควรสังเกตไม่ใช่แค่ว่าภาพออกมาสวยไหม แต่คือระบบสามารถปรับ input ที่หยาบมากให้กลายเป็น output ที่ใช้ได้จริงมากขึ้น นี่เป็น pattern ที่ใช้ได้กับแทบทุกสายงาน
- input สั้นๆ จากทีมขาย กลายเป็น proposal ที่อ่านรู้เรื่อง
- brief หยาบๆ จากทีมการตลาด กลายเป็นชุดภาพที่มี mood ชัดขึ้น
- โน้ตประชุมกระจัดกระจาย กลายเป็นสรุปงานที่พร้อมส่งต่อ
มุมที่เราคิดเพิ่มจากคลิปคือ ความสำเร็จของ AI ในองค์กรไม่ได้แปลว่าต้องทำทุกอย่างอัตโนมัติ แต่คือทำให้ input ที่ยังไม่สมบูรณ์ ถูกขยายให้พร้อมใช้งานเร็วขึ้นต่างหาก
Step 9: แปลงบทเรียนจากเดโมให้เข้ากับธุรกิจไทย
ถ้าจะสรุปคลิปนี้ในภาษาของคนทำธุรกิจ ประเด็นไม่ได้อยู่ที่ว่าจะใช้ RunPod หรือไม่ แต่อยู่ที่เราควรออกแบบการทดลอง AI ให้เร็วพอจะเรียนรู้จริง ยิ่งทีมเล็ก ยิ่งต้องให้ค่ากับความเร็วในการลองมากกว่าความสมบูรณ์แบบของระบบ
สำหรับธุรกิจไทย แนวทางใช้งานที่เป็นรูปธรรมอาจมีลักษณะนี้
- ร้านค้าออนไลน์ เริ่มจาก pipeline สร้างภาพสินค้าหลายแบบเพื่อช่วยทีมครีเอทีฟ
- บริษัทบริการ ใช้ workflow หลาย model เพื่อสรุปข้อมูลลูกค้าและร่างเอกสารติดตามงาน
- เอเจนซี ใช้ AI ช่วยแตก brief เป็น prompt แล้วสร้าง draft แรกให้ทีมออกแบบแก้ต่อ
- องค์กรขนาดกลาง สร้าง internal tool ที่รันเป็นช่วงเวลา ไม่ต้องเปิดเครื่อง GPU ค้างทั้งวัน
ข้อควรระวังคือ อย่ารีบทำ platform ใหญ่ก่อนเจอ use case ที่ชัด เพราะจะติดกับดัก infra-first แทนที่จะเป็น outcome-first
Actionable Insights
- เริ่มจาก use case ที่ต้องทดลองบ่อย เช่น สร้างภาพ สรุปเอกสาร หรือร่างคอนเทนต์ ไม่ใช่งาน production ใหญ่ทันที
- วัดรอบการทดลองให้ได้ว่า จากแก้โค้ดหนึ่งครั้งถึงเห็นผลจริงใช้เวลากี่นาที ถ้าช้าเกินไป AI จะไม่โตในองค์กร
- แยกให้ชัดว่าเมื่อไรควรใช้ pods และเมื่อไรควรใช้ serverless อย่าจ่ายแพงเกินจำเป็น
- ออกแบบ workflow หลาย model ตั้งแต่ต้น แทนการหวังพึ่ง model ตัวเดียวทำทุกอย่าง
- คำนวณต้นทุนต่อ output เช่น ต่อภาพ ต่อเอกสาร ต่อคำตอบ เพื่อคุยกับทีมธุรกิจได้ง่ายขึ้น
Troubleshooting
- ปัญหา: ผลลัพธ์ AI ออกมาแย่ตั้งแต่รอบแรก
สาเหตุ: ใช้ model ที่เหมาะกับความเร็วมากกว่าคุณภาพ หรือ prompt ยังหยาบเกินไป
วิธีแก้: เปลี่ยน model ให้เหมาะกับงาน ปรับ inference step และเพิ่มชั้น prompt refinement ก่อนสร้าง output - ปัญหา: ต้นทุน GPU สูงกว่าที่คิด
สาเหตุ: เปิด worker ค้างไว้มากเกินจำเป็น หรือเลือก serverless ทั้งที่งานยังเป็นช่วงทดลอง
วิธีแก้: ลด active worker เริ่มจากจำนวนน้อย และพิจารณาใช้ pods ก่อนเมื่อโหลดงานยังต่ำ - ปัญหา: ทีมลอง AI ได้ช้ามากแม้มี model พร้อมแล้ว
สาเหตุ: workflow deploy ยังต้องผ่านหลายขั้น เช่น Docker registry และการจองเครื่องใหม่ทุกครั้ง
วิธีแก้: ออกแบบ flow ให้แก้โค้ดแล้วทดสอบบน GPU ได้เร็วขึ้นจาก IDE หรือ environment ที่ใกล้กับการพัฒนา - ปัญหา: ใช้ model หลายตัวแล้วระบบซับซ้อนจนงง
สาเหตุ: ไม่มีการแยกบทบาทแต่ละ model ให้ชัด
วิธีแก้: นิยามหน้าที่แต่ละตัวให้ชัด เช่น ตัวแรกขยาย prompt ตัวที่สองสร้างภาพ ตัวที่สาม compose หรือคัดเลือก - ปัญหา: เดโมสวยแต่ใช้ในงานจริงไม่ได้
สาเหตุ: ไม่มีการผูก output เข้ากับงานธุรกิจจริง
วิธีแก้: เริ่มจากโจทย์ที่มี owner ชัด มี KPI ชัด และมีขั้นตอนนำผลลัพธ์ไปใช้ต่อได้ทันที
การต่อยอด
- ต่อ pipeline จาก image generation ไปสู่ระบบสร้างชุดคอนเทนต์ครบชุด เช่น ภาพ โพสต์ และแคปชันใน workflow เดียว
- สร้าง internal AI tool สำหรับทีมงานที่ไม่เขียนโค้ด โดยให้ backend ใช้แนวคิด orchestration แบบเดียวกับในเดโม
- เก็บข้อมูลต้นทุนต่อ request และคุณภาพผลลัพธ์ เพื่อนำไปตัดสินใจว่า use case ไหนควร scale ต่อจริง
Step 10: สรุป Checklist ทั้งหมด
- ระบุ use case ที่ต้องทดลองบ่อยและเห็นมูลค่าทางธุรกิจชัด
- แยกให้ออกว่างานนี้เหมาะกับ pods หรือ serverless
- ลดรอบการ deploy ให้สั้นที่สุด เพื่อให้แก้แล้วเห็นผลเร็ว
- กำหนดค่า endpoint ที่ผูกกับต้นทุนและความเร็วให้เหมาะกับงาน
- ทดลอง model มากกว่าหนึ่งตัว อย่าตัดสินจากผลครั้งแรก
- ออกแบบ workflow หลายขั้น ถ้างานจริงไม่ได้จบที่ model ตัวเดียว
- คำนวณต้นทุนต่อคำขอหรือต่อ output เพื่อคุยกับทีมธุรกิจได้
- ตรวจว่าผลลัพธ์ถูกนำไปใช้ต่อในงานจริงได้ ไม่ใช่แค่โชว์เดโม
- เริ่มเล็กก่อน แล้วค่อย scale เมื่อมี demand จริง
บทเรียนที่ชัดที่สุดจากคลิป GPU Cloud Deployment Without Leaving Your IDE คือ AI ที่ใช้งานได้จริงไม่ได้เริ่มจากระบบซับซ้อนที่สุด แต่เริ่มจากการทำให้ทีมลอง แก้ และเรียนรู้ได้เร็วที่สุดก่อน ถ้าเราลด friction ตรงจุดนี้ได้ การเอา AI ไปใช้ในธุรกิจจะไม่ใช่เรื่องไกลตัวอีกต่อไป