
สรุปจากคลิป ดูคลิปต้นฉบับ
Why More Context Makes Your Agent Dumber และวิธีออกแบบ AI Agent ให้ฉลาดขึ้น

ปัญหาของ AI agent จำนวนมากไม่ใช่มีข้อมูลน้อยเกินไป แต่เป็นมีข้อมูลมากเกินไปจนจับประเด็นไม่อยู่ คลิปจากช่อง AI Engineer ที่ชวน Nupur Sharma จาก Qodo มาพูดเรื่องนี้ ทำให้เห็นชัดว่า context window ที่ใหญ่ขึ้นไม่ได้แปลว่า agent จะตัดสินใจดีขึ้นเสมอไป บางครั้งมันกลับทำให้ระบบหลงทาง ใช้ token เปลือง และพลาดสิ่งสำคัญกลางทางไปแบบเงียบๆ
ประเด็นนี้สำคัญมากสำหรับเจ้าของธุรกิจและคนทำงานที่อยากเอา AI ไปใช้จริง เพราะหลายทีมมักเริ่มจากความคิดง่ายๆ ว่า “ยัดข้อมูลทั้งหมดเข้าไปก่อน เดี๋ยว AI คงจัดการเอง” แต่ของจริงไม่เป็นแบบนั้น บทความนี้สรุปแนวคิดหลักจากคลิป พร้อมวิเคราะห์ต่อว่า ถ้าเราอยากใช้ AI agent ในงานธุรกิจไทย ไม่ว่าจะเป็นรีวิวเอกสาร ตรวจงานภายใน วิเคราะห์เคสลูกค้า หรือช่วยทีม operation เราควรออกแบบ workflow แบบไหนถึงจะคุ้ม
สารบัญ
- Step 1: เข้าใจก่อนว่าทำไม context เยอะขึ้นไม่ได้ทำให้ agent เก่งขึ้น
- Step 2: เลิกยัดทุกอย่าง แล้วเริ่มคิดเรื่อง context optimization
- Step 3: ระวัง orchestration paradox เมื่อ agent ฉลาดขึ้นแต่งานกลับไม่เดิน
- Step 4: ใช้แนวคิด 80/20 แยกงานค้นหาออกจากงานตัดสินแบบชัดเจน
- Step 5: อย่าทำ one big agent ถ้างานมีหลายเป้าหมาย
- Step 6: ใช้ judge agent เพื่อรวมคำตอบให้สอดคล้องกัน
- Step 7: ใส่ calibration และ feedback loop เพื่อให้ agent เข้าใจองค์กรของเรา
- Actionable Insights
- Troubleshooting
- การต่อยอด
- สรุป Checklist ทั้งหมด
Step 1: เข้าใจก่อนว่าทำไม context เยอะขึ้นไม่ได้ทำให้ agent เก่งขึ้น
Nupur เริ่มจากวิวัฒนาการของ agent ตั้งแต่ยุค prompt แบบตรงๆ ที่ต้องใส่ข้อมูลสำคัญลงในช่อง context ที่ค่อนข้างจำกัด ไปจนถึงยุคที่ model รับข้อมูลได้มากขึ้นและเริ่มใช้เครื่องมือหลายแบบ เช่น search, document lookup หรือ workflow แบบหลายขั้นตอน
ฟังดูเหมือนเป็นพัฒนาการที่ดี แต่ปัญหาคือเมื่อเราให้ model เข้าถึงข้อมูลมากขึ้น เรากลับคาดหวังให้มันรู้เองว่าอะไรสำคัญ ซึ่งในความเป็นจริง LLM ยังไม่ได้เก่งเรื่อง “จัดลำดับความสำคัญ” แบบที่หลายทีมคิด
สิ่งที่น่าสนใจมากคือแนวคิดที่เธอเรียกว่า U curve กล่าวคือ เมื่อโยน context จำนวนมากให้ agent ระบบมักให้ความสนใจกับข้อมูลช่วงต้นและช่วงท้าย แต่ละเลยข้อมูลตรงกลางไปพอสมควร ผลลัพธ์คือ agent ดูเหมือนตอบได้ดี เพราะมันยังหยิบต้นเรื่องและปลายเรื่องมาใช้ได้ แต่รายละเอียดกลางทางที่อาจสำคัญที่สุดกลับหายไป
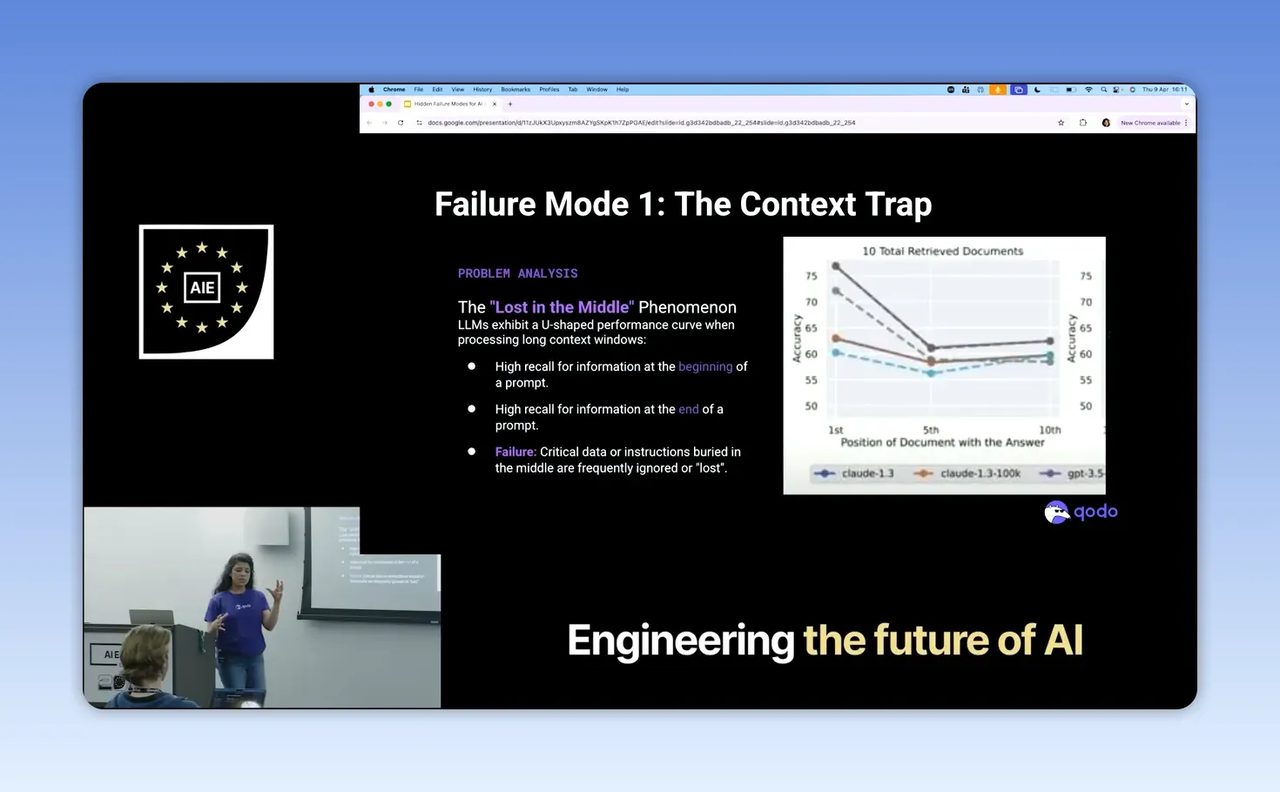
ถ้าแปลงเป็นภาษาธุรกิจไทย ภาพนี้เหมือนเราให้ AI อ่าน policy บริษัท, ข้อมูลลูกค้า, ข้อกำหนดกฎหมาย, ประวัติ ticket, และสรุปประชุมยาวหลายหน้า แล้วหวังให้มันสรุปคำตอบแบบแม่นยำ แต่ AI อาจจำแค่โจทย์แรกกับโน้ตล่าสุด แล้วมองข้ามข้อยกเว้นสำคัญกลางเอกสาร เช่น เงื่อนไขเครดิต, ขั้นตอนอนุมัติ, หรือข้อจำกัดเฉพาะอุตสาหกรรม
มุมที่ควรเห็นต่างเล็กน้อยกับความเชื่อในตลาดคือ context window ที่ใหญ่ขึ้นยังมีประโยชน์ แต่ประโยชน์นั้นไม่ได้มาจากการใส่ทุกอย่างแบบไม่คัด มันมีค่าก็ต่อเมื่อเรามีวิธีจัด context ให้ model เห็นสิ่งที่ควรเห็นจริงๆ
Step 2: เลิกยัดทุกอย่าง แล้วเริ่มคิดเรื่อง context optimization
หัวใจของคลิปนี้คือการเปลี่ยนจากแนวคิด “ใส่ข้อมูลทั้งหมด” ไปเป็น “คัดข้อมูลที่เหมาะกับงานนั้นจริงๆ” ซึ่ง Nupur เรียกมันว่า strategic solution for context optimization
ความหมายแบบง่ายที่สุดคือ เราไม่ควรให้ AI เป็นคนคุ้ยกองเอกสารเองทั้งหมด แต่ควรมีชั้นกรองก่อน เพื่อส่งเฉพาะข้อมูลที่เกี่ยวข้องกับ task นั้นเข้าไป
ในคลิปมีการพูดถึงแนวทางหลักหลายแบบ ซึ่งแต่ละแบบมีต้นทุนและข้อแลกเปลี่ยนต่างกัน
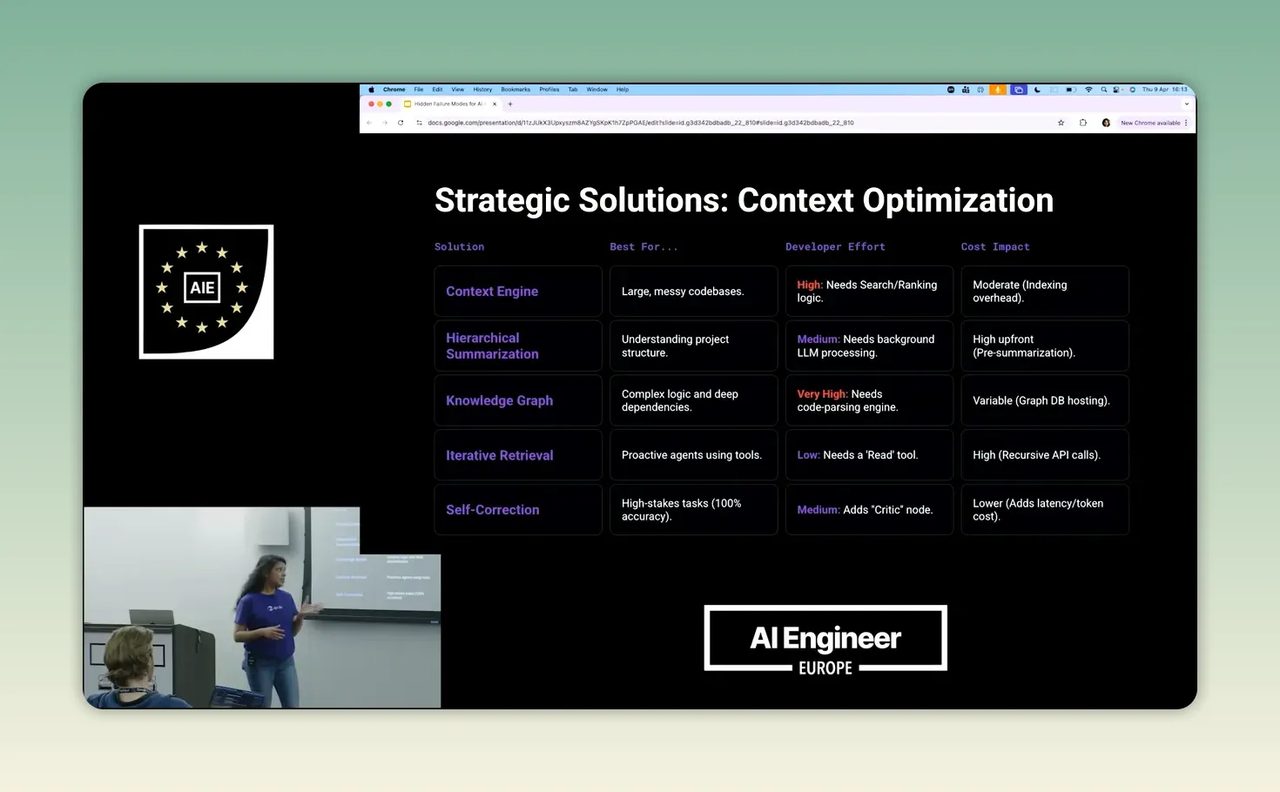
1. Context engine
แนวคิดนี้ทำหน้าที่เหมือนด่านคัดคนเข้าประตู มันช่วยจัดอันดับว่าอะไรสำคัญกับ task ที่ถามอยู่ เช่น ถ้าถามเรื่อง security ก็ไปดึงไฟล์หรือข้อมูลที่เกี่ยวข้องขึ้นมาก่อน
ข้อดีคือเหมาะกับระบบที่มี code base ยุ่งมากหรือมีแหล่งข้อมูลเยอะ แต่ข้อเสียคือยิ่งข้อมูลโตมาก เช่น หลายร้อย repository หรือเอกสารจำนวนมาก การทำ indexing และ mapping จะเริ่มช้าและดูแลยาก
สำหรับธุรกิจไทย ถ้าเรามีเอกสารไม่กี่หมวด เช่น SOP, FAQ, คู่มือขาย, สัญญา, และ policy ภายใน การทำ context engine แบบเบาๆ อาจคุ้ม แต่ถ้ายังอยู่ช่วงทดลอง ไม่จำเป็นต้องเริ่มจากของหนักขนาดนั้น
2. Hierarchical summarization
วิธีนี้คือสรุปข้อมูลเป็นชั้นๆ เช่น สรุปแต่ละไฟล์ แต่ละโฟลเดอร์ หรือแต่ละหมวดเอกสารก่อน แล้วค่อยให้ agent ตัดสินใจว่าจะลงลึกตรงไหน
ข้อดีคือ agent ไม่ต้องอ่านทุกอย่างเต็มๆ ตั้งแต่ต้น ข้อเสียคือมีต้นทุนในการประมวลผลสูง เพราะทุกครั้งที่ข้อมูลเปลี่ยนก็อาจต้องอัปเดตสรุปใหม่
ถ้าเอามาใช้กับธุรกิจ อาจเหมาะกับองค์กรที่มีเอกสารเปลี่ยนไม่บ่อย เช่น คู่มือ onboarding, playbook ฝ่ายขาย, หรือคู่มือบริการลูกค้า
3. Knowledge graph
นี่คือการเชื่อมโยงความสัมพันธ์ของข้อมูล เช่น เอกสาร A กระทบเอกสาร B หรือ policy นี้เชื่อมกับขั้นตอนอนุมัติอีกชุดหนึ่ง
ข้อดีคือเก่งกับงานที่มี dependency ซับซ้อนมาก แต่ข้อเสียคือสร้างยาก ต้องมีการออกแบบล่วงหน้าหนักพอสมควร
ในมุมธุรกิจ วิธีนี้น่าสนใจมากกับองค์กรที่มีหลายทีมเกี่ยวข้องกัน เช่น ฝ่ายขาย, การเงิน, กฎหมาย, compliance และ operation แต่ไม่ใช่จุดเริ่มต้นที่เหมาะสำหรับทุกทีม
4. Iterative retrieval
นี่คือวิธีที่ Nupur มองว่าเหมาะกับหลายกรณีที่สุด โดยเฉพาะทีมที่ไม่ได้สร้าง product AI โดยตรง แต่แค่อยากใช้ agent กับกระบวนการภายในของตัวเอง วิธีนี้จะทำดัชนีหรือป้ายกำกับไว้ก่อน แล้วให้ agent ค่อยๆ ไปดึงข้อมูลเพิ่มตามความเกี่ยวข้อง
ข้อดีคือใช้แรงตั้งต้นน้อยกว่าวิธีอื่น และยังให้ผลค่อนข้างดี ข้อเสียคือก็ยังมีต้นทุนการเรียกใช้งานอยู่ แต่ไม่ได้ต้องลงทุนระบบหนักตั้งแต่วันแรก
นี่เป็นจุดที่เราเห็นด้วยมาก ถ้าธุรกิจไทยเพิ่งเริ่มใช้ AI agent การเริ่มจาก iterative retrieval น่าจะ practical ที่สุด เพราะไม่ต้อง build infrastructure ใหญ่ก่อน แต่ยังลดปัญหา context ล้นได้พอสมควร
5. Self-correction
อีกวิธีคือให้ agent มีตัวตรวจซ้ำ หรือ critic node คอยเช็กว่าคำตอบที่ได้ยังสอดคล้องกับเป้าหมายตั้งต้นหรือไม่ ถ้าหลุดโจทย์ก็ให้ลองใหม่
แนวคิดนี้มีประโยชน์มากในงานที่ยอมแลก latency เพิ่มเล็กน้อย เพื่อให้ได้คำตอบที่น่าเชื่อถือขึ้น เช่น ตรวจร่างสัญญา, ตรวจความสอดคล้องของรายงาน, หรือช่วยสรุปประเด็นประชุมที่ต้องแม่น
ใครอยากอ่านแนวคิด retrieval เพิ่ม สามารถดูภาพรวมจาก Pinecone เรื่อง Retrieval Augmented Generation เพื่อทำความเข้าใจหลักคิดเบื้องหลังการดึงข้อมูลแบบเป็นขั้นตอน
Step 3: ระวัง orchestration paradox เมื่อ agent ฉลาดขึ้นแต่งานกลับไม่เดิน
อีกจุดที่คมมากในคลิปคือคำว่า orchestration paradox หมายถึง model ที่เก่งขึ้นอาจไม่ได้ช่วยให้ระบบทำงานจบเร็วขึ้นเสมอไป ตรงกันข้าม มันอาจใช้เวลาส่วนใหญ่ไปกับการคิดว่าจะใช้วิธีไหนดี จะเรียก tool ไหน จะค้นต่อไหม จะลองอีกวิธีไหม จนสุดท้าย token หมดไปกับการวางแผน มากกว่าการลงมือทำจริง
นี่เป็นอาการที่หลายทีมเจอแล้วงงว่า ทำไม AI “ดูขยัน” แต่ไม่ค่อยส่งงานกลับมาให้ใช้ได้จริง เพราะมันติดอยู่ในโหมดค้นหาแนวทางไม่รู้จบ
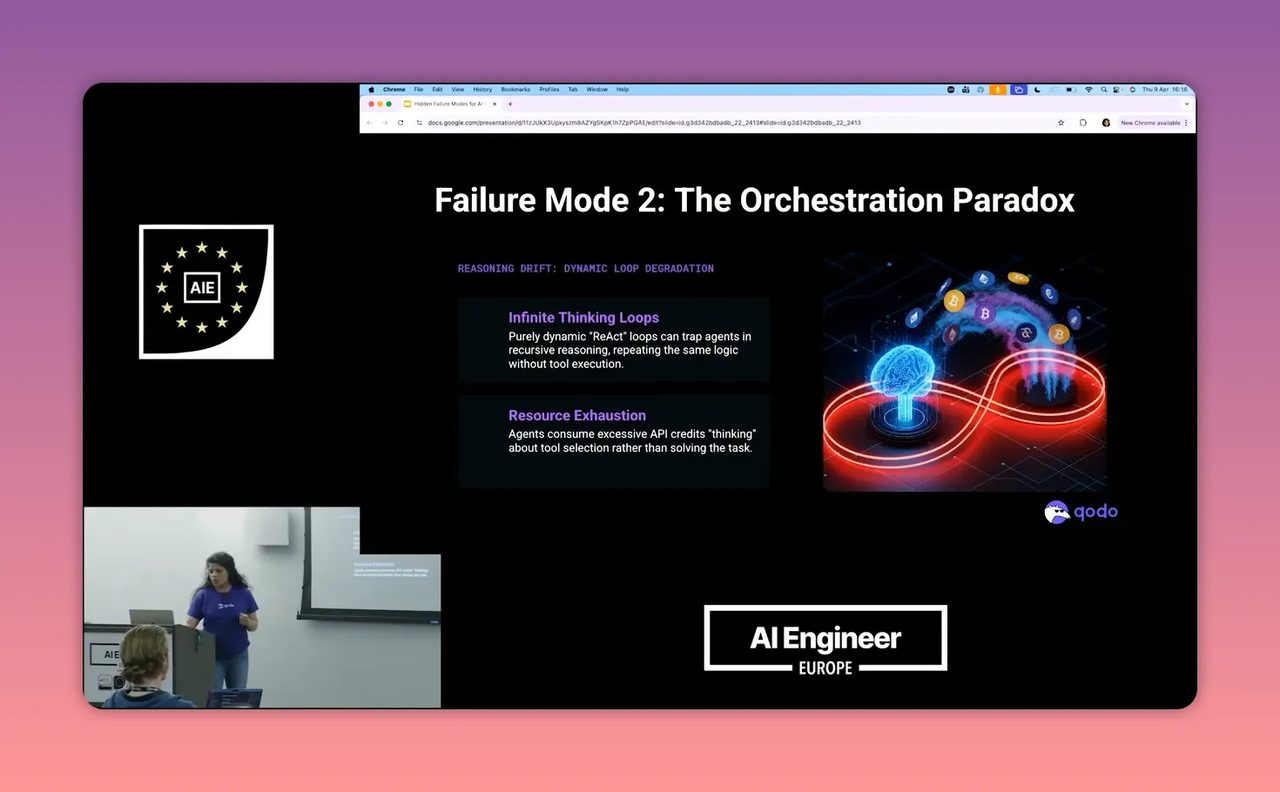
ถ้าเอาไปเทียบกับงานธุรกิจ เช่น เราสั่ง agent ให้ช่วยวางแผนแคมเปญการตลาด มันอาจใช้เวลายาวไปกับการค้น framework, เปรียบเทียบ channel, หา best practice เพิ่มเรื่อยๆ แต่ไม่ยอมสรุป action plan ที่นำไปใช้ได้
หรือในงานจัดซื้อ AI อาจวนอยู่กับการตีความ requirement แทนที่จะตอบว่า supplier คนไหนผ่านเกณฑ์และเพราะอะไร
สัญญาณอันตรายคือ
- ตอบช้าแบบผิดปกติ
- มี reasoning ยาวมากแต่ข้อสรุปน้อย
- ชอบเปลี่ยนวิธีทำงานไปมา
- ใช้ token สูงแต่ output ไม่คุ้ม
จุดนี้สะท้อนว่าการเลือก model ที่เก่งที่สุดมาใช้ทุกขั้น ไม่ได้แปลว่า workflow จะดีสุดเสมอไป
Step 4: ใช้แนวคิด 80/20 แยกงานค้นหาออกจากงานตัดสินแบบชัดเจน
ทางแก้ที่ Qodo ใช้คือ 80/20 hybrid approach โดยให้ 80% ของงานเป็นส่วนที่เปิดกว้างให้ model ที่ reasoning เก่งทำหน้าที่ค้นหา สำรวจ และหาทางเลือก ส่วนอีก 20% เป็นงานที่ต้องมี hard gate ชัดเจน เช่น validation, summarization, หรือการตัดสินตามเกณฑ์ที่กำหนดไว้

หลักคิดนี้เรียบง่ายแต่ทรงพลังมาก เพราะมันบังคับให้เราแยก task เป็น 2 ประเภท
- งานค้นหาและสำรวจ เช่น หา pattern, หา option, วิเคราะห์สิ่งที่อาจเกี่ยวข้อง
- งานตัดสินและตรวจสอบ เช่น สรุปผลตาม format, เช็กว่าเข้าเกณฑ์ไหม, จัดอันดับตาม rule
ส่วน 80% ใช้ model ที่คิดเก่งได้ เพราะต้องเผชิญโจทย์เปิด ส่วน 20% ไม่จำเป็นต้องใช้ model แพงหรือ reasoning สูงมาก เพราะเป็นงานที่มีเกณฑ์ชัดกว่า
นี่เป็นบทเรียนสำคัญสำหรับคนทำธุรกิจ ถ้าเรากำลังจะทำ AI workflow อย่าเริ่มจากถามว่า “จะใช้ model ไหน” แต่ให้เริ่มจากถามว่า “ขั้นไหนเป็นการค้นหา และขั้นไหนเป็นการตัดสิน” เมื่อแบ่งได้ชัด ต้นทุนจะลดลงและผลลัพธ์จะนิ่งขึ้นมาก
ในคลิปยังบอกด้วยว่า ถ้ากลัวส่วน 80% จะวนลูปไม่จบ ก็สามารถตั้งตัวนับจำนวนรอบ หรือกำหนด timeout ได้ เช่น ให้ลองได้ 4 ถึง 5 รอบ หรือไม่เกิน 5 นาที จากนั้นต้องใช้ผลลัพธ์ล่าสุดไปต่อ
แนวนี้ใช้กับธุรกิจไทยได้ตรงมาก เช่น
- ให้ AI หา complaint ที่เกี่ยวข้องจากหลายแหล่งก่อน
- แล้วใช้ตัวตรวจอีกตัวสรุปว่าเคสนี้เข้ากลุ่มปัญหาใด
- หรือให้ AI หา supplier หลายรายก่อน
- แล้วให้ขั้น validation เปรียบเทียบตามเกณฑ์ราคา, ระยะเวลา, เงื่อนไขชำระเงิน
Step 5: อย่าทำ one big agent ถ้างานมีหลายเป้าหมาย
อีกความเข้าใจผิดที่พบบ่อยคือ เมื่อ context window ใหญ่ขึ้น หลายทีมก็อยากให้ agent ตัวเดียวทำทุกอย่าง ทั้งตรวจสอบ ทั้งทดสอบ ทั้งรีวิว ทั้งสรุปผล เพราะคิดว่าข้อมูลชุดเดียวกันน่าจะพอ
ปัญหาคือเมื่อ agent ได้หลายเป้าหมายพร้อมกัน มันมักโฟกัสแค่บางงานและทำอีกบางงานหายไประหว่างทาง เช่น รับ 4 งาน แต่สุดท้ายส่งกลับมาดีแค่ 2 งาน
ทางออกคือแนวคิด mixture of agents หรือการแยก agent ออกเป็นตัวเล็กๆ ที่เชี่ยวชาญเฉพาะเรื่อง แล้วค่อยรวมผลกลับทีหลัง

ตัวอย่างในคลิปยกภาพให้เข้าใจง่ายมาก เช่น ถ้าให้ agent หลายตัวช่วยวางแผนทริปท่องเที่ยว ตัวหนึ่งหาโรงแรม ตัวหนึ่งหาตั๋ว อีกตัวหา location ถ้าไม่มีตัวกลางมาประกอบผลลัพธ์ เราอาจได้โรงแรมอยู่กรีซ แต่ไฟลต์ไปอีกประเทศ ซึ่งแต่ละคำตอบดีในตัวเอง แต่เอามารวมกันแล้วใช้ไม่ได้
โลกธุรกิจก็เหมือนกัน เช่น ถ้าเรามี agent ตรวจ compliance, agent วิเคราะห์ต้นทุน, agent ดู risk, agent สรุปแผนปฏิบัติการ แต่ไม่มีตัวรวม เราอาจได้คำตอบที่แต่ละชิ้นดูดี แต่ขัดกันเอง
Step 6: ใช้ judge agent เพื่อรวมคำตอบให้สอดคล้องกัน
เมื่อมี agent หลายตัวแล้ว ปัญหาถัดไปคือจะรวมผลอย่างไรไม่ให้มั่ว คำตอบของ Qodo คือใช้ judge agent ทำหน้าที่รับผลลัพธ์จาก sub-agent หลายตัว แล้วเช็กว่าเมื่อนำมาประกอบกันแล้ว ยังสมเหตุสมผลกับเป้าหมายจริงหรือไม่
นี่ต่างจากการให้ agent ตัวใหญ่คิดทุกอย่างเอง เพราะ judge agent ไม่ต้องเก่งทุกเรื่อง มันแค่ต้องเก่งเรื่องประเมินผลรวมและคัดว่าอะไรเกี่ยวข้องจริง
แนวคิดนี้คล้ายกับการบริหารทีมในองค์กร เราไม่ต้องการพนักงานคนเดียวที่ทำได้ทุกอย่าง แต่อยากได้ผู้เชี่ยวชาญหลายคน แล้วมีคนกลางที่เข้าใจภาพรวมพอจะตัดสินได้ว่าข้อเสนอใดควรผ่าน

ในตัวอย่าง code review ของ Qodo มีโครงสร้างแบบนี้
- มี context collector ไปดึงข้อมูลจาก PR, tools และแหล่ง context ต่างๆ
- จากนั้นแยกข้อมูลไปยัง agent เฉพาะทาง เช่น security agent, agent ดู code diff, agent ดู issue ที่เกี่ยวข้อง
- สุดท้าย judge agent จะรับผลกลับมา ประเมินว่าสิ่งไหนเกี่ยวข้องจริง และควรส่งต่อเป็นข้อเสนอแนะหรือไม่
ถ้าเอามาปรับใช้กับธุรกิจไทย เราสามารถคิดเป็น workflow แบบนี้ได้เช่นกัน
- collector ดึงข้อมูลจาก CRM, FAQ, ประวัติลูกค้า, เอกสารนโยบาย
- sub-agent ตัวหนึ่งวิเคราะห์เจตนาของลูกค้า
- อีกตัวเช็กสิทธิ์หรือเงื่อนไขสัญญา
- อีกตัวประเมินความเสี่ยงหรือความเร่งด่วน
- judge agent สรุปคำตอบสุดท้ายและเสนอขั้นตอนถัดไป
นี่จะดีกว่าการให้ chatbot ตัวเดียวแบกทุกอย่าง เพราะเราคุมคุณภาพแต่ละส่วนได้ชัดกว่า
Step 7: ใส่ calibration และ feedback loop เพื่อให้ agent เข้าใจองค์กรของเรา
ช่วงถามตอบท้ายคลิปมีประเด็นที่สำคัญมาก และหลายคนมองข้าม คือ agent ไม่ได้รู้เองว่าอะไรสำคัญสำหรับองค์กรของเรา แม้ใช้ภาษาเดียวกันหรือ framework เดียวกัน แต่ธุรกิจคนละประเภทก็ให้น้ำหนักคนละเรื่อง
ตัวอย่างเช่น ระบบ Java เหมือนกัน แต่บริษัท healthcare, retail และ finance ย่อมมีข้อกังวลไม่เหมือนกัน ดังนั้นถ้าไม่ส่ง guideline หรือสัญญาณเฉพาะองค์กรเข้าไป AI ก็จะตอบแบบกลางๆ และอาจไม่ตรงที่ต้องการ
Qodo แก้เรื่องนี้ด้วยการใช้หลายแหล่งเป็นสัญญาณประกอบ เช่น
- ประวัติ PR เดิมหรือประวัติการรีวิวที่ผ่านมา
- กฎหรือ guideline ที่องค์กรกำหนด
- เอกสารด้าน compliance หรือ architecture
- พฤติกรรมการยอมรับหรือปฏิเสธคำแนะนำในอดีต
จุดนี้มีความละเอียดสำคัญมาก คือไม่ใช่ทุกอย่างในอดีตควรเอามาเลียนแบบ เพราะบางอย่างที่เคยเกิดขึ้นอาจเป็นพฤติกรรมผิด เช่น การ hard-code API key ถ้าระบบเอาแต่เรียนรู้จากอดีตโดยไม่มีกฎตายตัว มันอาจเรียนรู้สิ่งที่ไม่ควรเรียนรู้
ดังนั้นเราควรแยกให้ชัดระหว่าง
- rules หรือกฎที่ต้องถือเป็นหลัก
- patterns หรือรูปแบบที่เคยเกิดขึ้น ซึ่งใช้เป็นสัญญาณได้ แต่ไม่ใช่ความจริงสูงสุด
นี่เป็นมุมที่ใช้กับงานธุรกิจทุกประเภท เช่น ถ้าเราสร้าง agent ช่วยตอบลูกค้า เราต้องแยกระหว่าง “policy บริษัท” กับ “สิ่งที่แอดมินเคยตอบบ่อย” เพราะคำตอบเดิมอาจไม่ถูกเสมอ
ถ้าอยากต่อยอดเรื่องระบบประเมิน feedback loop และการวัดคุณภาพ AI สามารถอ่านแนวคิดเพิ่มเติมจาก Google Rules of Machine Learning ซึ่งช่วยให้มองภาพการใช้ข้อมูลป้อนกลับกับระบบตัดสินใจได้ดีขึ้น
Actionable Insights
- อย่าเริ่มจากการยัดข้อมูลทั้งหมดเข้า model ให้เริ่มจากคัดว่า task นี้ต้องเห็นอะไรจริงๆ
- แยก workflow เป็นช่วงค้นหา กับช่วงตัดสิน เพื่อเลือก model ให้เหมาะกับงานแต่ละช่วง
- ถ้างานมีหลายเป้าหมาย ใช้หลาย agent เฉพาะทาง ดีกว่า one big agent
- เพิ่ม judge หรือ critic node เสมอในงานที่มีผลกระทบต่อธุรกิจ
- เก็บ feedback ว่าคำแนะนำไหนถูกยอมรับหรือปฏิเสธ เพื่อปรับน้ำหนักรอบถัดไป
Troubleshooting
- ปัญหา: AI ตอบกว้างมากแต่ไม่ตรงประเด็น
สาเหตุ: ส่ง context เยอะเกินจน model จับเป้าหมายหลักไม่อยู่
วิธีแก้: ลดข้อมูลที่ไม่จำเป็น แยก task ให้แคบลง และใช้ retrieval ดึงเฉพาะส่วนที่เกี่ยวข้อง - ปัญหา: ระบบใช้ token สูงแต่ได้คำตอบช้า
สาเหตุ: agent ติดอยู่ใน orchestration paradox ใช้เวลาคิดวิธีมากกว่าทำงาน
วิธีแก้: ตั้ง timeout หรือนับจำนวนรอบ และแยกงานค้นหากับงาน validation ออกจากกัน - ปัญหา: agent หลายตัวให้ผลลัพธ์ขัดกันเอง
สาเหตุ: ไม่มีตัวกลางรวมผลและประเมินความสอดคล้อง
วิธีแก้: เพิ่ม judge agent ที่รับผลจากทุกตัวแล้วสรุปตามเป้าหมายเดียว - ปัญหา: คำแนะนำของ AI ไม่เข้ากับวิธีทำงานขององค์กร
สาเหตุ: model ไม่มี guideline หรือสัญญาณเฉพาะขององค์กร
วิธีแก้: ป้อนกฎภายใน เอกสาร policy และ feedback จากการใช้งานจริงเข้า workflow - ปัญหา: AI เรียนรู้จากอดีตแล้วทำตามพฤติกรรมผิดๆ
สาเหตุ: ใช้ historical data โดยไม่แยกระหว่าง rule กับ pattern
วิธีแก้: กำหนดกฎตายตัวให้ชัด และให้น้ำหนักประวัติแค่เป็นสัญญาณประกอบ
การต่อยอด
- ลองสร้าง AI agent สำหรับตรวจเอกสารภายใน เช่น ใบเสนอราคา สัญญา หรือคำขออนุมัติ โดยมี judge node คอยตรวจความครบถ้วน
- ทำ workflow ช่วยทีมบริการลูกค้า ที่ดึงข้อมูลจากหลายระบบแล้วสรุปคำตอบแบบมีเหตุผลรองรับ
- ใช้ feedback จากทีมงานจริงมาสร้างระบบถ่วงน้ำหนักคำแนะนำ เพื่อให้ AI เข้ากับวิธีทำงานขององค์กรเรามากขึ้นทุกเดือน
สรุป Checklist ทั้งหมด
- ☐ เข้าใจก่อนว่า context เยอะไม่ได้แปลว่าคำตอบดีขึ้น
- ☐ ระวัง U curve ที่ทำให้ข้อมูลตรงกลางหายไป
- ☐ เลือกวิธีจัด context ให้เหมาะ เช่น iterative retrieval หรือ summarization
- ☐ เพิ่ม critic หรือ self-correction ในงานสำคัญ
- ☐ แยกงานค้นหากับงานตัดสินตามแนวคิด 80/20
- ☐ ตั้ง timeout หรือ limit รอบเพื่อกัน loop ไม่จบ
- ☐ หลีกเลี่ยง one big agent ถ้างานมีหลายเป้าหมาย
- ☐ ใช้ sub-agent เฉพาะทาง และมี judge agent รวมผล
- ☐ ป้อน guideline, policy และข้อมูลเฉพาะองค์กรเข้า workflow
- ☐ เก็บ feedback ว่าคำแนะนำไหนถูกยอมรับหรือปฏิเสธ
- ☐ แยก rule ออกจาก pattern เพื่อไม่ให้ AI เรียนรู้สิ่งผิด
สรุปแล้ว ข้อคิดที่คมที่สุดจาก Why More Context Makes Your Agent Dumber คือปัญหาของ AI agent ไม่ได้อยู่ที่ context window เล็กเกินไป แต่อยู่ที่เราออกแบบระบบให้มันคิดกับข้อมูลอย่างไรต่างหาก ถ้าเราใส่ข้อมูลทั้งหมดแบบไม่คัด ไม่แยกบทบาทของ model และไม่มีกลไกตัดสินผลลัพธ์ สุดท้าย agent จะดูฉลาดแต่ทำงานไม่ค่อยจบ
แต่ถ้าเราเริ่มจากการจัด context ให้ถูก แบ่ง task ให้ชัด ใช้หลาย agent ตามความเชี่ยวชาญ และมี feedback loop ที่ดี AI จะเริ่มเป็นเครื่องมือที่ใช้ได้จริงกับธุรกิจ ไม่ใช่แค่ของเดโมที่ดูน่าตื่นเต้นในห้องประชุมเท่านั้น